中国保险业过去五年基础数据分析
中国保险业过去五年基础数据分析
分析报告目录
- 中国保险业过去五年基础数据分析
- 一.分析报告介绍
- 二.用到的主要工具
- 三.保险数据采集
- 四.数据清洗和预处理
- 五.数据分析阶段
- 5.1 当前保险业状态分析
- 5.2 过去统计数据分析
- 5.3 未来状态预测
- 六.数据分析总结
一.分析报告介绍
“保险”是近两年来人们茶余饭后的热门话题,我本次的报告是网上学习了数据分析相关课程以后的项目结业作业。本作业将从公开途径抓取中国保险业过去5年的基础数据,管中窥豹看一看这个行业及保险产品当前的状况,过去的发展及未来的驱势。
本次作业选取了这两年我个人比较感兴趣,自己平时比较关注的保险业进行了简单的分析,从选题,数据抓取,建模分析独立完成,历时一周,花了大量的时间。虽然这份报告对于真正业内人士来说只能算是皮毛,但是也给了我一个很好了解,体验数据挖掘/数据分析的整个过程。最大的感受是最重要的是好的,足够完备的数据,有了好的数据,后面的分析建模很多时候就是水到渠成的事情了。
此外,对保险行业内部的相关资料和知识点查询,也感谢我个人的保险经纪人陆颖一直一来有问必答的无私帮助。
二.用到的主要工具
Python版本: Python3.6
jupter notebook: Anaconda3-5.2.0-Windows-x86_64
pandas:数据分析读取数据
matplotlib:绘图
rcParams:用来正常显示中文,并设置中文字体
三.保险数据采集
本次报告的数据是通过和讯保险页面采集自2013年1月至2018年9月的保险行业基础数据,主要是保险总保费,各险种保费,和总赔付支出,各险种赔付支出的数据。
具体数据爬取代码这里就省略了。
四.数据清洗和预处理
经过数据爬取阶段,我们获得了所有的数据组成一个以月份为辨识标签的二维数组(total_data),接下来我们需要对数据进行基本的预处理,其中包括了生成Dataframe,查看数据缺失及错误状况,添加缺失并修改错误数据。
import pandas as pd
import numpy as np
a = np.vstack(total_data) #将初始数组生成DataFrame
columns_name = ['date','原保险保费总收入','财产险收入','人身险总收入','寿险收入','健康险收入','人身意外保险收入','原保险赔付总支出','财产险支出','人身险总支出','寿险支出','健康险支出','人身意外保险支出']
df = pd.DataFrame(data = a,columns = columns_name)
df.date = pd.to_datetime(df.date) #将传入的日期数据转变成datatime
df.set_index('date',inplace = True) #将日期数据转成DatatimeIndex
df1 = df.loc[:,:].astype(float) #确保每个表项都是float型
由于数据都是线性的,所以我们可以通过画个图来看数据采集是否完整,有无错误。
###############################################
####本段内容是为了解决画图无法显示中文字体的问题,如果可以显示中文则无需执行本段内容
####指定默认字体 需要先将网上下载的的SimHei.ttf 文件放入 ~\Anaconda3\Lib\site-packages\matplotlib\mpl-data\fonts\ttf 中,然后敲入以下命令即可:
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
###############################################
from matplotlib import pyplot as plt
%matplotlib inline
df1.plot(figsize=(16,9)) #对初始的DataFrame进行画图
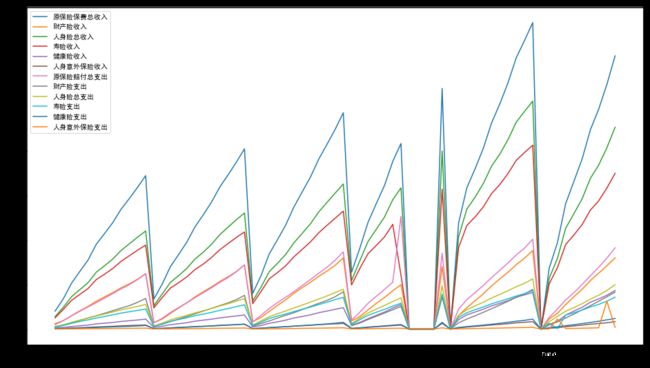
根据图示,我们可以看到2016年后段,17年1月份,12月份数据缺失,此外,16年7月, 18年2月和8月线条都有突变,预示数据大概率有误。这里数据的矫正只能手动输入,矫正数据源自保险监督管理委员会官网。
官网数据网页没有规律,且网页内表格不同年份的格式不一致,所以并未直接作为数据源进行采样。
df2 = df1.replace(0,np.nan) #先将0值全部替换成NAN值,以便后期检索是否还有未补缺数据
#获取缺失的基本月份数据
data1608 = [22958.9373,5635.0848,17323.8524,13721.4564,3098.2305,504.1655,6901.1431,2937.1279,3964.0152,3242.7249,605.3101,115.9803]
data1609 = [25168.2615,6370.5827,18797.6788,14783.8733,3430.4069,583.3985,7750.6999,3321.5870,4429.1129,3610.5333,687.1908,131.3888]
data1610 = [27010.3752,7018.3821,19991.9932,15703.9707,3647.7410,640.2814,8526.1670,3670.1245,4856.0425,3946.5561,763.4167,146.0697]
data1611 = [28864.8711,7773.0544,21091.8167,16556.6817,3841.7960,693.3390,9450.0194,4131.1226,5318.8968,4287.5209,870.7195,160.6564]
data1701 = [8553.4033,973.8127,7579.5907,6861.5894,641.1138,76.8875,1277.2914,419.6850,857.6063,729.5261,109.4866,18.5937]
data1712 = [36581.0074,9834.6579,26746.3495,21455.5650,4389.4604,901.3241,11180.7933,5087.4496,6093.3437,4574.8907,1294.7670,223.6859]
data1612 = [30959.1009,8724.4981,22234.6028,17442.2167,4042.4968,749.8893,10512.8900,4726.1839,5786.7061,4602.9462,1000.7522,183.0077]
#将缺失月份输入dataframe中
df2.loc['2016-08-01'] = pd.Series(data1608,index = df2.columns)
df2.loc['2016-09-01'] = pd.Series(data1609,index = df2.columns)
df2.loc['2016-10-01'] = pd.Series(data1610,index = df2.columns)
df2.loc['2016-11-01'] = pd.Series(data1611,index = df2.columns)
df2.loc['2017-01-01'] = pd.Series(data1701,index = df2.columns)
df2.loc['2017-12-01'] = pd.Series(data1712,index = df2.columns)
df2.loc['2016-12-01'] = pd.Series(data1612,index = df2.columns)
#对数据错误表项,根据官网校验后修正
df2.loc['2016-07-01']['原保险赔付总支出'], df2.loc['2016-07-01']['寿险收入'] = df2.loc['2016-07-01']['寿险收入'], df2.loc['2016-07-01']['原保险赔付总支出']
df2.loc['2018-02-01'][-1],df2.loc['2018-02-01'][-3] = df2.loc['2018-02-01'][-3], df2.loc['2018-02-01'][-1]
df2.loc['2018-08-01'][-1] = df2.loc['2018-08-01'][-4]-df2.loc['2018-08-01'][-3] - df2.loc['2018-08-01'][-2]
#再次画图查看数据是否连续线性
df2.plot(figsize=(16,9))
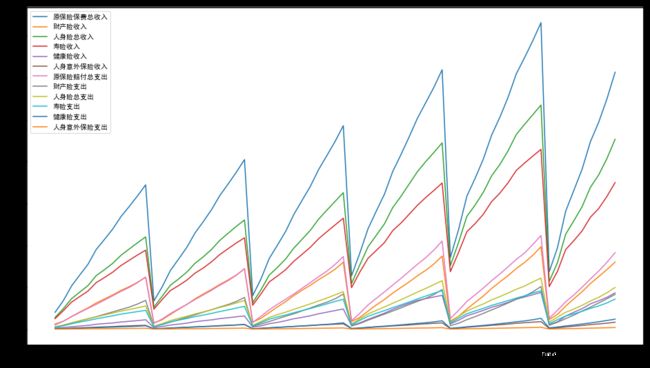
查看过官网以后,我们还发现,每个月的数据其实都是当年自一月份以来数据之和,而不是单个月数据,这意味着我们对除一月份以外的数据,都需要减去该月之前一个月的数据,以算出真正该月产生的保险数据。
df_month = df2.copy()
i = len(df_month)
while i > 0:
i -= 1 #从表最后行往前修正数据
if (df_month.index[i]).to_pydatetime().month == 1: #如果当月月份是一月份,则数据不需要修改
continue
else: #非一月份的当月数据需要减去前面一个月的数据以获取当月值
df_month.loc[df_month.index[i]] -= df_month.loc[df_month.index[i] - pd.DateOffset(months=1)]
#获取最终的月数据,画图检验
df_month.plot(figsize=(16,9))
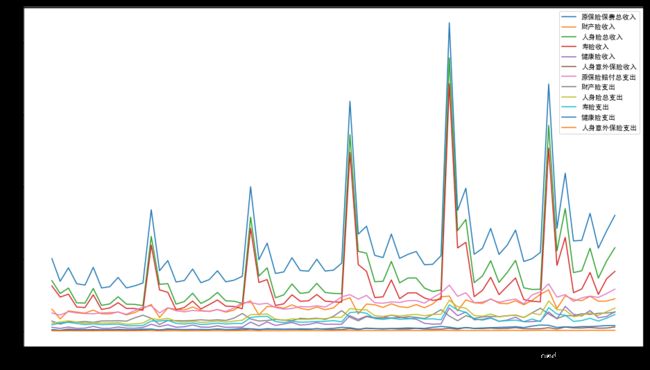
#接下来根据月数据生成季度数据和年度数据
df_year = df_month.resample('Y').sum()
df_quarter = df_month.resample('Q').sum()
五.数据分析阶段
数据分析阶段,我们将分成当前数据状态分析,过去统计数据分析和未来状态预测三个方面来进行。
5.1 当前保险业状态分析
我们将通过对2018年保险业收入和支出的饼图来进行当前保险业的状态分析。
#2018年保费收入和赔付的饼图
#先定义一个简单函数,使得饼图中不但可以显示百分比,还能显示具体数字显示
def pct_number(pct, data):
number = float(pct/100.*np.sum(data))
return "{:.2f}%\n({:.2f} 亿元)".format(pct, number)
fig, axes = plt.subplots(nrows = 1, ncols = 2,figsize = (14, 6)) #画两个饼图,一个收入,一个赔付
axes[0].axis('equal') #两个圆都是正圆
axes[1].axis('equal')
labels0 = ['财产险收入','寿险收入','健康险收入','人身意外险收入'] #定义饼图不同部分标签
labels1 = ['财产险赔付','寿险赔付','健康险赔付','人身意外险赔付']
axes[0].set_title("2018 保险收入", fontsize = 20) #定义饼图title
axes[1].set_title("2018 保险赔付", fontsize = 20)
#截取2018年各单项险种数据进行展示
axes[0].pie(df_year.iloc[-1,[1,3,4,5]], labels = labels0,autopct = lambda pct: pct_number(pct, df_year.iloc[-1,[1,3,4,5]]))
axes[1].pie(df_year.iloc[-1,[7,9,10,11]], labels = labels1,autopct = lambda pct: pct_number(pct, df_year.iloc[-1,[7,9,10,11]]))
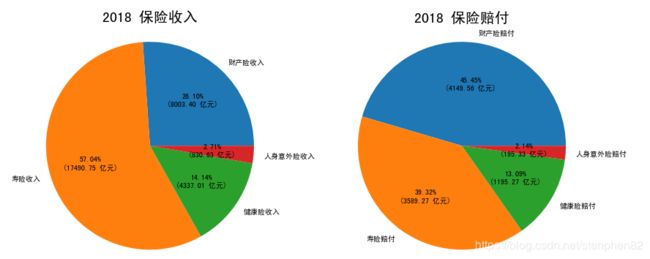
通过2018至今年第三季度饼图中各保险占比和费用的展示,我们可以清楚的看到:
1.在保险收入的部分,寿险占到了近六成份额,是保险公司绝对的营收大头。然而在支出部分,寿险却不是支出最多的,同时收入和支出的差额是各种险种中最大的。
但是为什么会造成这样的数据差距呢?其实懂点商业保险的都知道单纯的人寿保险同等保额对应的保费普遍并不会比健康险更贵,所以这里的寿险是个泛指,我个人认为里面很大比例应该是所谓的年金险。由于年金险也是在被保险人身故时结束保险责任的一种人身保险,所以在划类时也被划分到了寿险类是可以理解的。
同时年金险的缴费和赔付特点和其他所有保险都是相反的,别的保险都是短期或定期缴少量保费,出险后获取大额保额赔付,说穿了就是其他不出险人的保费都赔给出险的人了。
但是年金险的特点则是投保人需要短期或定期缴大额保费后,被保险人每年或者退休以后才能收到约定的的少量定额赔付,但是赔付次数/年限一直延续直到被保险人去世为止。这里的赔付费用用的是投保人前期交的大量保费后,保险公司用这笔钱理财盈余所得。也就是用的就是自己的本钱,和他人保费无关。
此外,年金险一般还会同时卖一个万能险,等同提供一个高额利率的银行储蓄账户,这又是一个吸钱的大杀器。
年金险的这个收入高,赔付低的特点使得寿险这块必然成为保险公司争抢市场的重中之重。
2.人身意外险和健康险收入支出占比基本相同,分别只有2%和15%左右,说明这两个险种当前并不是保险公司的营收重点。但是这两个险种收入和支出差距也很明显,显示他们也有很好的发展空间。
3.财险收入占比不到三成却要支出四成五的赔付,使得财险在赔付占比上排名第一。财险本身分类太多太杂,从车险,房屋险,到矿山,土地,甚至各种信用责任,和人身人寿无关的都算财险。对个体财险公司而言,其所承保项目每年突发事故,天灾人祸出险的多寡可能会很大的影响该财险公司的盈利,但是对整个市场来说,财险市场算是一个比较成熟稳定的市场。
5.2 过去统计数据分析
对于过去统计数据,我们会从保费的收入和赔付数额以及月同比增长率两方面来分析。
##画两个柱状图,对应收入和赔付支出的历史数据
my_colors = ['r','g','y','b'] #对四种险种定义4个颜色对应
fig, axes = plt.subplots(nrows = 2, ncols = 1,sharex = True,figsize = (16, 12))
df_quarter.iloc[:,[1,3,4,5]].plot.bar(figsize = (16, 9),ax = axes[0],color = my_colors) #四个险种的收入季度柱状图
df_quarter.iloc[:,[7,9,10,11]].plot.bar(figsize = (16, 9),ax = axes[1],color = my_colors) #四个险种的赔付支出季度柱状图
axes[0].set_title("保险季度收入",fontsize = 15) #定义柱状图title
axes[1].set_title("保险季度赔付",fontsize = 15)
axes[1].set_xlabel("日期") #定义柱状图的x,y轴label
axes[1].set_ylabel("单位: 亿元")
axes[0].set_ylabel("单位: 亿元")
patches, labels = axes[0].get_legend_handles_labels() #这两段代码是为了调整图中示例标签的位置
axes[0].legend(patches, labels, loc = 2)
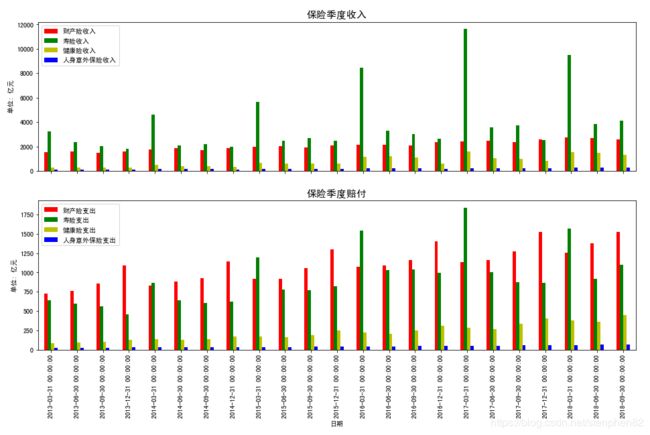
从2013年至今的保险各险种季度收入和赔付柱状图我们可以看到:
1.从保费收入来看,整体体量寿险和财险收入要明显高于健康险和人身意外险。其中寿险在每年的第一季度总能一骑绝尘,和所有其他险种拉开巨大的差距。究其原因其实还是前面提过的年金险引起的。由于年金险强大的吸金效益,每年年末新年伊始各家保险公司都会倾尽所能卖自己的“开门红”产品,这些“开门红”基本都是年金险。这就造成了第一季度巨量的保费收入。
2.从保费赔付支出来看,首先我们可以发现Y轴单位差了整整一个量级,说明保险业整体盈利能力还是非常巨大的。其次,虽然峰值依然是寿险的,但是平均来看显然财险总支出会更大些,这也符合我们前面饼图显示的各险种赔付比例。至于为什么第一季度寿险赔的也特别多呢?当然是因为年金险这个季度签得多,由于年金险赔付都是按年支出,自然同样的季节赔的也就多了。 有意思的是财险总是第四季度赔付最多,应该是和大家年前清账,以便进行全年盈亏统计不无关系。
#画月同比增长率的折线图
from matplotlib.ticker import FuncFormatter
df_month_rate = df_month.pct_change(periods = 12).iloc[12:,:] #计算月同比增长率,取值时去掉最初作为base数据的12个月
fig, axes = plt.subplots(nrows = 2, ncols = 1,figsize = (16, 12))
df_month_rate.iloc[:,[3,4]].plot(color=['g','y'], ax = axes[0],figsize=(16, 12),grid=True) #为避免凌乱,将4个险种两两分开显示
df_month_rate.iloc[:,[1,5]].plot(color=['r','b'], ax = axes[1],figsize=(16, 12),grid=True) #
def to_percent(temp, position): #定义一个可以在y轴将小数显示成百分数的函数
return '%.f'%(100*temp) + '%'
for i in range(0,2): #定义x,y轴label和格式,多画一条y=0的基准线
axes[i].yaxis.set_major_formatter(FuncFormatter(to_percent))
axes[i].set_ylabel("同比增长率")
axes[i].set_xlabel("日期")
axes[i].axhline(y=0, color='black', lw=2)
axes[1].set_title("财险/意外险月同比增长率",fontsize=15) #定义图像title
axes[0].set_title("寿险/健康险月同比增长率",fontsize=15)
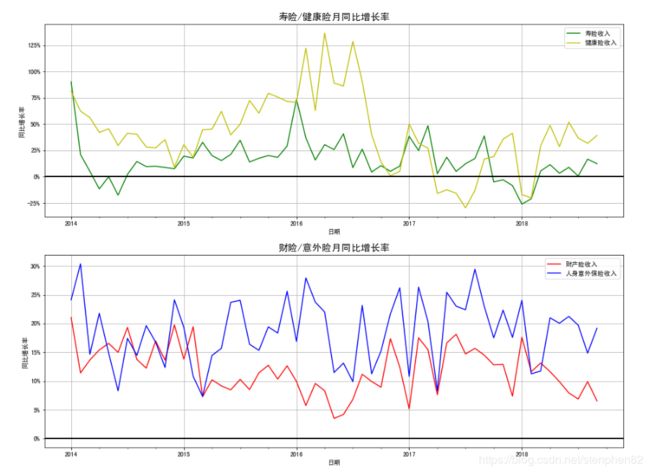
从分组后的月同比增长率我们可以看到:
1.根据Y轴的数值,总得来说各险种收入和赔付都处在高速的增长中,说明我国保险业近几年发展速度迅猛。
2.从各险种而言,我们可以看到健康险收入的同比增长率在2017年以前明显高于其他险种,增幅最高可以超过125%。当时超高的增长率主要是由于16年底前市场有很多带理财属性的短期/定期健康险(很多都是直接银行当有保险功能的理财产品代卖),受到当时消费者的热捧。
然而我们可以看到健康险的同比增长率自16年底开始出现急跌,17年中旬和18年开年甚至录得了负增长。其背后的原因是因为自16年中旬开始,相关监管机构和高层就开始放出“保险信保”信号,要求行业回归本源,大力发展保障型产品,而不是吸收资金只求规模,避免造成潜在金融系统风险。随之对应的是先后出台多项红头文件和措施,杜绝了健康险同年金险一样朝偏理财产品的转变。
但是就算如此,其实健康险同比增长率也并非一蹶不振,17年后期及18年中期依旧能够录得高速的增长率,说明了健康险在更注重保障以后仍然有广阔的发展空间,这是由于75,80后的人们开始保险意识的逐步觉醒,很多人开始自发的去了解保险,主动购买保险。这种主动行为目标都是以重疾险,医疗险等健康险为主体的。
相对于健康险的超高增长,寿险的增长率略低,且自16初后似乎就开始进入下降通道。主要原因还是“保险信保”的政策改变引起的。特别是17年10月份开始实行的著名的134号文件,对年金险很多快速返还,高额利率等有潜在风险的行业做法做了更严格的规定和限制,从而使年金险作为理财产品的吸引力大幅下降。
3.相对于前两个险种而言,财险和人身意外险的同比增长率虽然没有超高速的增长率,但是胜在稳定,几年来都能保持在一个区间中,其中意外险的小体量也预示着更大的发展空间。
5.3 未来状态预测
由于保险数据非常规整的季度性,很适合用prophet工具进行时间序列的分析和预测。我们会对各保险在未来三年内进行保费收入,月同比增长率以及各险种在总保险收入中的占比进行预测。
#如果没有,需要先安装fbprophet
#!conda install -c conda-forge --yes fbprophet
from fbprophet import Prophet
import warnings
warnings.filterwarnings('ignore')
以下是各保险在未来三年内保费收入预测
#定义一个调用prophet并画出相应预测图的函数
def prophet_image(df,periods,ax): #传入dataframe,预测时长和子图序列信息
df = df.reset_index() # 重置索引
df.columns = ['ds', 'y']
m = Prophet() # 创建加法模型
m.fit(df) # 训练
future = m.make_future_dataframe(periods=periods, freq='M') # 生成预测序列
forecast = m.predict(future) # 预测
fig = m.plot(forecast,ax=ax) # 绘图
#绘制4中保险月收入未来三年的预测图
fig, axes = plt.subplots(nrows=2, ncols=2,figsize=(14, 8)) #绘制一个2X2的图,分别对应四个险种
prophet_image(df_month.iloc[:,1],39,axes[0,0]) #调用上面定义的函数进行未来3年的保费数据预测
prophet_image(df_month.iloc[:,3],39,axes[0,1])
prophet_image(df_month.iloc[:,4],39,axes[1,0])
prophet_image(df_month.iloc[:,5],39,axes[1,1])
for i in range(0,2): #定义个子图y轴label,加画一条x轴基准线已区分历史值和预测值
for j in range(0,2):
axes[i,j].set_ylabel("单位: 亿元")
axes[i,j].axvline(x='2018-09-01',ls="--",color="y", lw=1)
axes[0,0].set_xlabel("财险保费未来三年预测") #定义各子图的x轴label
axes[0,1].set_xlabel("寿险保费未来三年预测")
axes[1,0].set_xlabel("健康险保费未来三年预测")
axes[1,1].set_xlabel("人身意外险保费未来三年预测")
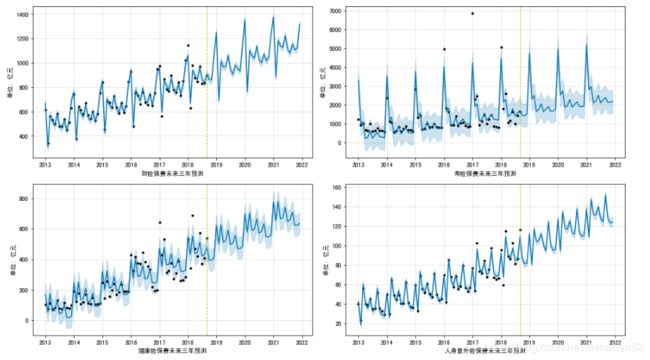
从四种险种的未来三年保费收入预测图中我们可以看到:
1.各个险种的保费收入依旧能够稳步增长,说明整个行业总体增长的基石依然存在,行业还是很有发展前景的。
2.从斜率上我们也可以看出来,寿险保费预测的斜率明显低于其他三个险种,显示出寿险(年金险)由于受规模和政策的影响,发展趋缓。
3.每个图中折线周边的蓝色阴影部分标志着此点对应日期所预测数值的离散范围。财险和意外险阴影很小,说明这两个险种过往的运营数据规律性明显,所以预测值离散很小。而寿险和健康险由于受政策影响较大,过往数据规律性较差,所以预测值的离散程度也就较高。
我们最后再看下各险种在未来三年对于总保费的占比趋势预测。
fig, axes = plt.subplots(nrows=2, ncols=2,figsize=(16, 8)) #绘制一个2X2的图,分别对应四个险种
prophet_image(df_month.iloc[:,1]/df_month.iloc[:,0],39,axes[0,0]) #将单个险种保费除以总保费的数值带入函数中进行预测
prophet_image(df_month.iloc[:,3]/df_month.iloc[:,0],39,axes[0,1])
prophet_image(df_month.iloc[:,4]/df_month.iloc[:,0],39,axes[1,0])
prophet_image(df_month.iloc[:,5]/df_month.iloc[:,0],39,axes[1,1])
for i in range(0,2):
for j in range(0,2):
axes[i,j].yaxis.set_major_formatter(FuncFormatter(to_percent)) #对各子图设定y轴百分比显示
axes[i,j].set_ylabel("占比 %") #对各子图定义y轴label
axes[i,j].axhline(y=0,ls="--",color="black", lw=1) #对各子图加画一条y=0基准线
axes[i,j].axvline(x='2018-09-01',ls="--",color="y", lw=1) #对各子图加画一条x轴基准线已区分历史值和预测值

从各险种占总保费收入的比重预测图中我们可以看到,财险和寿险的份额会逐渐缩小,健康险和意外险的份额会逐渐扩大。这也预示着未来市场发展的重点和方向的转变。
六.数据分析总结
根据对保险业近五年基础数据的分析,我们可以知道,
首先保险业务收入支出数额巨大,巨大的保费收入最终会通过各种投资渠道流入到整个金融市场中去,在整个金融体系中占据的不可忽视的作用和地位。
对具体险种而言,财险市场总体稳定独立,发展良好。而在人寿险市场,在过去及可预见未来的时间内,寿险(年金险)市场仍将是每个保险公司的必争之地,体量巨大,利润丰厚。但是随着政策的扶持,国民保险意识的觉醒,健康险和人身意外险已经开始奋起直追,他们将是未来新兴的增长点。