任务流TaskFlow的应用
TaskFlow主要由OpenStack社区在维护,致力于为一组任务的执行提供高效细粒度的控制。在Cinder组件源码中,创建卷等耗时比较长且容易出错的操作便利用到了taskflow,同样的,Neutron组件也使用它控制创建网络的复杂操作。
一、taskflow的特性
TaskFlow作为OpenStack的通用流程引擎,能让作业执行变得容易,同时满足三种特性。
1. 独立性
不相关的原子任务执行成功与否不影响其它原子任务的执行。
2. 中断性
一个编排任务在执行过程中可以暂停,下一次执行时能从暂停处继续执行。
3. 并发性
对于无序的多个任务,引擎能基于多协程多线程多进程来同时执行它们。
二、taskflow实现原理
1. 任务的抽象
三、taskflow在作业平台的应用
1. 作业平台的应用场景
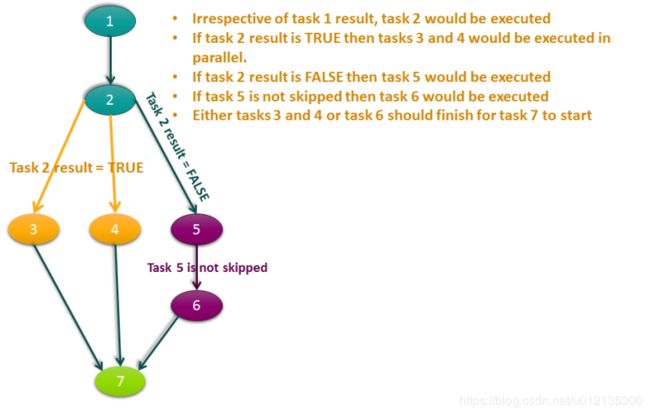
在作业平台中进行编排任务的时候,不仅需要支持线性的工作流,还要支持能适应复杂场景的多分支工作流。

1.1 安装软件
以安装MariaDB为例
- 设置MariaDB yum仓库
cat <
/etc/yum.repos.d/kubernetes.repo
# MariaDB 10.3 CentOS repository list - created 2018-09-19 02:18 UTC
# http://downloads.mariadb.org/mariadb/repositories/
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.3/centos7-ppc64le
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
EOF - sudo yum install MariaDB-server MariaDB-client ;若安装失败则 yum remove mariadb-libs*,再执行sudo yum install MariaDB-server MariaDB-client
- systemctl start mariadb
- /usr/bin/mysqladmin -uroot password 'xx' 或 /usr/bin/mysql_secure_installation
Enter current password for root (enter for none):
Set root password? [Y/n] Remove anonymous users? [Y/n] y Disallow root login remotely? [Y/n] y Remove test database and access to it? [Y/n] y Reload privilege tables now? [Y/n] y
-
firewall-cmd --add-service=mysql --permanent;firewall-cmd --reload
1.2 变更升级
以OpenStack Nova版本升级(v3.8.2)为例
- 上传升级包到yum源中,在所有节点执行:yum clean all & yum makecache
- 备份所有控制节点的nova代码:
cp -r /usr/lib/python2.7/site-packages/nova /root/NOVA3.8.2/nova-code.bak
-
备份所有控制节点的nova配置文件:
cp -r /etc/nova /root/NOVA3.8.2/nova-conf.bak
- 选择一台计算节点,备份nova代码及配置文件:
cp -r /usr/lib/python2.7/site-packages/nova /root/NOVA3.8.2/nova-code.bak
cp -r /etc/nova /root/NOVA3.8.2/nova-conf.bak
- 停止控制节点nova相关服务:
systemctl stop openstack-nova-api openstack-nova-conductor openstack-nova-scheduler openstack-nova-console openstack-nova-cert openstack-nova-consoleauth openstack-nova-novncproxy - 停止计算节点compute服务
- 控制节点代码升级:
yum upgrade openstack-nova-console openstack-nova-common openstack-nova-novncproxy openstack-nova-cert openstack-nova-api openstack-nova-conductor openstack-nova-scheduler python-nova - 计算节点代码升级:
yum upgrade openstack-nova-compute openstack-nova-common python-nova - 修改所有计算节点nova.conf配置文件:
openstack-config --set /etc/nova/nova.conf libvirt monitor_reconnect_count 100
openstack-config --set /etc/nova/nova.conf libvirt monitor_reconnect_count_interval 2[libvirt]
monitor_reconnect_count=100
monitor_reconnect_count_interval=2
-
重启控制节点nova服务
- 重启计算节点compute服务
2. 任务的编写模板
1.1 python(适用于统计分析、数据清洗、自动测试等任务)

1.2 shell(适合于变更升级等任务)
在用python实现时,Task.execute()方法在命令成功执行时返回True(对应的provides='task_1_done'),否则返回False。
原子任务模型1:带参数执行
if [ $# -ne 2 ]
then
echo Usage: test9 a b
else
total=$[$1+$2]
echo The total is $total
fi
原子任务模型2:升级指定的程序
yum upgrade app1 app2 ... appN
原子任务模型3:创建指定内容的文件
cat <
# put your own content
#
EOF
原子任务模型4:修改OpenStack配置文件
openstack-config --set /etc/{component}/{component}.conf {section} key value
原子任务模型5:分支节点
sysOS=`uname -s`
if [ $sysOS == "Darwin" ];then
echo "I'm MacOS"
elif [ $sysOS == "Linux" ];then
echo "I'm Linux"
else
echo "Other OS: $sysOS"
fi
若工作流中存在这样的任务模型,则分支节点与邻节点的连线需要配置属性,如pretask_result='example'
3. 工作流的表示
基础图标类型:判断节点、暂停节点、并行节点和任务节点,使用location中的节点type属性来标识,分别为”exclusive“,"pause", "parallel"和"task"
{
"line": [{
"id": "automated_intro_path",
"type": "out_fork",
"source": {"id": "decision", "arrow": "Right"}
"target": {"id": "automated_intro", "arrow": "Left"},
"condition": {
"expression": "identifier >= 6" # identifier为分支前的原子任务的某个输出参数的id
}
}, {
"id": "personalized_intro_path",
"type": "out_fork",
"source": {"id": "decision", "arrow": "Right"},
"target": {"id": "personalized_intro", "arrow": "Left"}
}, {
"id": "sid-xxx",
"type": "in_fork",
"source": {"id": "update_yum", "arrow": "Right"},
"target": {"id": "decision", "arrow": "Left"}
“condition”: {}
}
],
"location": [{
"id": "update_yum",
"type": "task",
"atomic_task_id": 150,
"business": {
"key_task_flag": 1,
"operator": 2,
"audit_person": 2
}
"data": {"host_ids": [2, 3, 6], "params": {"input": [], "output": []}}
}, {
"id": "chart3",
"type": "task",
"atomic_task_id": 151,
"data": {
"host_ids": [12, 45, 30],
"params": {
"input": [{
"id": "sid-01"
"key": "worker",
"value": "2",
"type": "integer"
}],
"output": [{
"id": "sid-03"
"key": "path",
"value": "/opt/data/girls.jar",
"type": "string"
}]
}
}, {
"id": "decision",
"type": "exclusive",
"default": "automated_intro_path"
}, {
"id": "personalized_intro",
"type": "task",
"business": {
"key_task_flag": 1,
"operator": 1,
"audit_person": 3
}
"atomic_task_id": 5,
"data": {'host_ids': [13, 4, 86], "params": {"input": [], "output": []}}
}, {
"id": "automated_intro",
"type": "task",
"atomic_task_id": 36,
"data": {'host_ids': [21, 34, 86], "params": {"input": [], "output": []}}
}]
}
工作流规范与后台执行时选用的TaskFlow模式的关系:
- 若json中表示边的key不包括'condition',则直接选用LinearFlowlinear_flow.Flow("pass-from-to").add(TaskA('a'), TaskB('b'))
- 若json中表示边的key包括'condition',且'condition'的type为'parallel',则选用LinearFlow + UnorderedFlow
unorderedflow.add(CommonTask("task2"), CommonTask("task3"))
linearflow.add(CommonTask("task1"),
unorderedflow) - 若json中表示边的key包括'condition',且'condition'的type为'exclusive',则选用GraphFlow
flow = gf.Flow('g')
a = utils.AddOneSameProvidesRequires("a", inject={'value': 0})
b = utils.AddOneSameProvidesRequires("b")
c = utils.AddOneSameProvidesRequires("c")
flow.add(a, b, c, resolve_requires=False)
flow.link(a, b, decider=lambda history: False,
decider_depth='atom')
flow.link(b, c)
四、后续的优化工作