linux内存管理笔记(二十三)----伙伴系统Linux概述
在内核初始化完成后,内存管理的责任由伙伴系统承担。前面一章主要学习了伙伴系统的软件算法实现原理伙伴系统原理,本章正式开始Linux下伙伴系统的学习,本章主要是原理性的梳理一些流程,其主要包括
- linux对于伙伴系统的设计思路
- 内存碎片的问题和分配器如何处理碎片
- 伙伴系统的分配器API
1. 设计思路
前面章节中学习了伙伴系统原理,我们重新梳理伙伴系统的核心思路:内核将系统的空闲页面分成11个块链表,每个块链表分别管理着1,2,4,8,16,32,64,128,256,512和1024个物理页帧号,每个页面大小为4K bytes,那么对于伙伴系统管理的块大小范围从4K bytes到4M bytes,以2的倍数递增,其内存管理框图如下图所示

2. 伙伴系统的结构
系统内存中的每个物理内存页,都对应于一个struct page实例。每个内存域都关联一个struct zone的实例,其中保存了用于管理伙伴系统数据的主要结构组。
struct zone {
/* free areas of differents sizes */
struct free_area free_area[MAX_ORDER];
};
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
对于free_area数组总共有11个索引,每个索引管理着不同大小的块链表,对于其构成如下
- free_area[0]管理的内存单元为1(2^0)个页面,即大小为4K byte内存
- free_area[1]管理的内存单元为2(2^1)个页面,即大小为8K byte内存
- 以此类推,即可得到free_area[2],free_area[3] … free_area[11]
struct free_area 是一个伙伴系统的辅助数据结构:
| 字段 | 描述 |
|---|---|
| free_list | 用于连接空闲页的链表,页链表包含大小相同的连续内存区域 |
| nr_free | 指定了当前内存区中空闲页块的数目,而每种迁移类型都对应于一个空闲列表 |
伙伴系统的分配器维护着空闲页面组成的块,每一个块都是一个 2 的幂次方个页,指数为阶.比如两个页就是 21,4 个页就是 22,这其中的 1 和 2 就是阶,以此类推可以到达 MAX_ORDER。zone->free_area[MAX_ORDER] 数组中阶作为各个元素的索引,用来对应链表中的连续内存块包含的页面数量。我们来看看一个示意图,索引 0 指向的链表就是 20 阶链表,他携带的内存块都是 1 个页面,再比如 24 这个位置链表就是表示他下面挂的都是 64 个页大小的连续内存块,那么他的字节数为 256K。
3. 内存块是如何连接
从 struct zone 的 free_area 结构体数组内的 free_list 可以得知,这个数组保存的是一个链表的头,所以他其实指向的是一个完整的链表,根据这个数组的索引可以得知,这个链表下面挂载的都是 2x 方个数的连续页面,每一个 free_list 项表示的是一个连续的物理内存块,这样管理起来很简单而且开销不大。具体实现如图所示:
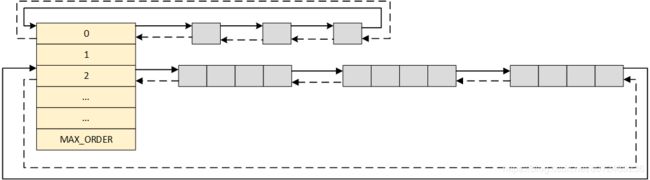
伙伴不必是彼此连续的,从图中可以看出,不同大小的连续页面块都是挂载在不同的链表上,其满足以下关系
- 当低阶连续的连续的页面不足时,一个内存区在分配期间会自动分解成两半,内核会自动将未用的一般加入到对应的链表中
- 如果未来的某个时刻,由于内存释放的缘故,两个内存区都处于空闲状态,可通过其地址判断其是否为伙伴,如果是伙伴,那么就会被合并起来。
4. 避免碎片
在linux的内存管理方面,有一个长期存在的问题,在系统启动并长期运行后,物理内存中会产生很多的内存碎片问题,如下图所示
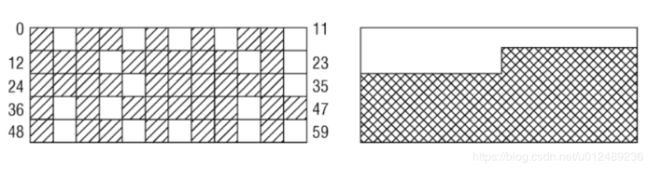
- 对于该空间,最大的连续空页只有一页,这对于用户空间的应用程序没有什么问题,其内存时通过页表映射的范式,无论空闲页在物理内存中如何的分布,应用程序看到的内存总是连续的。
- 对于内核,碎片确实一个大问题,物理内存一致映射到地址空间的内核部分,此时内核无法映射比一页更大的内存区。
物理内存的碎片化一直是linux的一大问题,内核对于该问题仿照文件系统的方式,通过碎片合并的方式解决该问题。但是由于许多的物理内存页时不能移动到任意未知的,阻碍了该方法的实施,所以内核采用的时反碎片化,即试图从最初开始尽可能的防止碎片问题。
对于内核,将已分配的页划分成下面3种不同类型
| 页面类型 | 概述 | 例子 |
|---|---|---|
| 不可移动页 | 在内存中有固定的位置,不能移动到其他地方 | 核心内核分配的大多数内存属于该类型 |
| 可回收页 | 不能直接移动,但可以删除,其内容可以从某些源重新生成 | kswapd守护进程会根据可回收页访问的频繁程度,周期性的释放此类内存。另外在内存短缺的情况下,页可以发起页面回收机制。 |
| 可移动页 | 可以随意地移动,属于用户空间应用程序的页属性 | 他们是通过页表映射的。如果他们复制到新的位置,页表项页可以相应的更新,应用程序不会注意到任何事。 |
而对于内核,使用的反碎片化技术,即基于将具有相同可移动性的页分组思想。前面由于页无法移动,导致在原本空余的内存区中将无法进行连续内存分配。根据页的可移动性,将其分配到不同的列表中,即可防止这种情况。内核可以采用以下思想
内存将内存区域划分为分别用于可移动页和不可移动页的分配
free_area管理的内存还细分为各种类型,例如不可移动页面和可移动页面等,每种类型的页面类型对应一个free_list链表,该链表就链接着页面结构体。
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE,
#endif
MIGRATE_TYPES
};
| 宏 | 类型 |
|---|---|
| MIGRATE_UNMOVABLE | 不可移动页,用于内核分配的页面,I/O缓冲区,内核堆栈等 |
| MIGRATE_MOVABLE | 可移动页,当需要大的连续内存时,通过移动当前使用的页面来尽可能防止碎片,用于分配用户内存; |
| MIGRATE_RECLAIMABLE | 可回收页,当没有可用内存时使用此类型 |
| MIGRATE_PCPTYPES | 是per_cpu_pageset, 即用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目 |
| MIGRATE_HIGHATOMIC | 在罕见的情况下,内核需要分配一个高阶的页面块而不能休眠.如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_HIGHATOMIC中分配内存 |
| MIGRATE_CMA | Linux内核最新的连续内存分配器(CMA), 用于避免预留大块内存 |
| MIGRATE_ISOLATE | 是一个特殊的虚拟区域, 用于跨越NUMA结点移动物理内存页。在大型系统上, 它有益于将物理内存页移动到接近于使用该页最频繁的CPU。 |
| MIGRATE_TYPES | 只是表示迁移类型的数目, 也不代表具体的区域 |
如果内核无法满足针对某一给定迁移类型的分配请求,会怎么办呢?内核提供一种备用列表fallbacks的方式,规定了在指定列表中无法满足分配请求时,接下来应使用哪种迁移类型
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};
以MIGRATE_RECLAIMABLE为例,如果我需要申请这种页框,当然会优先从这类页框的链表中获取,如果没有,我会依次尝试从MIGRATE_UNMOVABLE -> MIGRATE_MOVABLE 链表中进行分配。
5. 初始化伙伴系统
在初始化伙伴系统之前,所有的node和zone的描述符都已经初始化完毕,同时物理内存中所有的页描述符页相应的初始化为了MIGRATE_MOVABLE类型的页。初始化过程中首先将所有管理区的伙伴系统链表置空,首先回顾下free_area的相关域都被初始化
static void __meminit zone_init_free_lists(struct zone *zone)
{
unsigned int order, t;
for_each_migratetype_order(order, t) {
INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
zone->free_area[order].nr_free = 0;
}
}
#define for_each_migratetype_order(order, type) \
for (order = 0; order < MAX_ORDER; order++) \
for (type = 0; type < MIGRATE_TYPES; type++)
在内存子系统初始化期间,memmap_init_zone负责处理内存域的page实列,所有的页最初都标记为可移动的
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
........
/* 该区所有页都设置为MIGRATE_MOVABLE */
if ((z->zone_start_pfn <= pfn) && (pfn < zone_end_pfn(z)) && !(pfn & (pageblock_nr_pages - 1)))
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
........
}
对于高端内存区和低端内存区在上章节已经梳理过,本章将不在重复梳理。到这里,高端内存和低端内存的初始化就已经完成了。所以未使用的页框都已经放入伙伴系统中供伙伴系统进行管理。
6. 分配器API
buddy分配器是按照页为单位分配和释放物理内存的,free_area就是通过buddy分配器来管理的,其职能分配2的整数幂的页。那么就决定了该接口不能像标准的C库提供的malloc或者bootmem分配器那样指定所需大小的内存,必须指定的是分配阶,伙伴系统将在内存中分配2^n页,内核中细颗粒的分配只能使用slab分配器(或者slub/slob分配器),内核提供多个接口供其他模块申请页框使用
| 函数接口 | 功能 |
|---|---|
| struct page * alloc_pages (gfp_mask, order) | 向伙伴系统请求连续的2的order次方个页框,返回第一个页描述符。 |
| struct page * alloc_page (gfp_mask) | 相当于struct page * alloc_pages(gfp_mask, 0)。 |
| unsigned long get_zeroed_page(gfp_t gfp_mask) | 分配一页并返回一个page实例,页对应的内存填充0(所有其他函数,分配之后页的内容是未定义的) |
| void * __get_free_pages (gfp_mask, order) | 工作方式与上述函数相同,但返回分配内存块的虚拟地址,而不是page实例 |
CPU的高速缓存,对于申请单个页框,系统会从每个CPU的高速缓存维护的单个页框链表中进行分配;而对于申请多个页框,系统则从伙伴系统中进行分配,可以说每个CPU的高速缓存算是伙伴系统的一部分,专门用于分配单个 页框,因为系统希望尽量让那些刚释放掉的单个页框分配出去,这样有效的提高缓存命中率,因为释放掉的页框可能还处于缓存中,而杠分配的页框一般都会马上使用,系统就不用对这些页框进行换入换出缓存了
有4个函数用于释放不在使用的页,其定义如下:
- free_page(struct page *)和free_pages(struct page *, order)用于将一个或2^n页返回给内存管理子系统中,内存区的起始地址由指向该内存区的第一个page实例的指针表示
- __ free_page(addr) 和 __free_pages(addr, order),其定于与前面两个类似,但在表示需要释放内存区域时,使用了虚拟地址而不是page实例
内存分配掩码(Get Free Page Mask, GFP_mask),是描述内核分配内存方法的32位或64位标志符,可分为两类:行为修饰符、区修饰符。行为描述符表示分配方式,区修饰符表示分配区。
区修饰符表示内存应该从哪个区分配,通常分配可以从任何区开始,不过,内核优先从ZONE_NORMAL开始,这样可确保其他区在需要时有足够的空闲页可用 [1] 。下表是区修饰符的列表。
| 标志 | 描述 |
|---|---|
| __GFP_DMA | 从ZONE_DMA分配 |
| __GFP_DMA32 | 只在ZONE_DMA32分配 |
| __GFP_HIGHMEM | 从ZONE_HIGHMEM或ZONE_NORMAL分配 |
行为修饰符表示内核应当如何分配所需的内存,例如分配器分配内存中的睡眠行为、失败行为、启动各类设备文件行为,具体含义如下表。
| 行为修饰符 | 描述 |
|---|---|
| __GFP_RECLAIMABLE __GFP_MOVABLE |
是页迁移机制所需的标志,它们分别将分配的内存标记为可回收的或可移动的。 |
| __GFP_HIGH | 分配器可以访问紧急事件缓冲池 |
| __GFP_IO | 在查找空闲内存期间,分配器可以进行磁盘I/O操作。 |
| __GFP_FS | 分配器可执行VFS操作,可启动文件系统I/O。 |
| __GFP_REPEAT | 分配器在分配失败后自动重试,重试也可能失败,但有上限次数。 |
| __GFP_NOFAIL | 分配器在分配失败后一直重试,直至成功 |
| __GFP_NORETRY | 分配器在分配失败后不重试,从而导致分配失败 |
| __GFP_COMP | 添加混合页元素, 在hugetlb的代码内部使用 |
| __GFP_ZERO | 分配器在分配成功时,将返回填充字节0的页 |
在源码中注释强调,一般不直接使用行为修饰符,而是采用类型标志组合行为修饰符和区修饰符,将各种可能用到的组合进行组合,用户使用时无需记住各类行为修饰符的意义,而是直接使用下述表格中的类型标志。
| 类型标志 | 描述 |
|---|---|
| GFP_ATOMIC | 用于原子分配,在任何情况下都不能中断,用在中断处理程序,下半部,持有自旋锁以及其他不能睡眠的地方 |
| GFP_NOWAIT | 与GFP_ATOMIC类似,不同之处在于,调用不会退给紧急内存池,这就增加了内存分配失败的可能性 |
| GFP_KERNEL | 这是一种常规的分配方式,可能会阻塞。这个标志在睡眠安全时用在进程的长下文代码中。为了获取调用者所需的内存,内核会尽力而为。这个标志应该是首选标志 |
| GFP_NOIO | 这种分配可以阻塞,但不会启动磁盘I/O,这个标志在不能引发更多的磁盘I/O时阻塞I/O代码,这可能导致令人不愉快的递归 |
| GFP_NOFS | 这种分配在必要时可以阻塞,但是也可能启动磁盘,但是不会启动文件系统操作,这个标志在你不能在启动另一个文件系统操作时,用在文件系统部分的代码中 |
| GFP_USER | 这是一种常规的分配方式,可能会阻塞。这个标志用于为用户空间进程分配内存时使用 |
| GFP_DMA GFP_DMA32 | 用于分配适用于DMA的内存,当前是__GFP_DMA的同义词,GFP_DMA32也是__GFP_GMA32的同义词 |
| GFP_HIGHUSER | 是GFP_USER的一个扩展,也用于用户空间。 它允许分配无法直接映射的高端内存。使用高端内存页是没有坏处的,因为用户过程的地址空间总是通过非线性页表组织的 |
| GFP_HIGHUSER_MOVABLE | 用途类似于GFP_HIGHUSER,但分配将从虚拟内存域ZONE_MOVABLE进行 |
对于我们驱动中使用最多的场景是GFP_KERNEL和GFP_ATOMIC
- GFP_KERNEL:进程上下文中使用,可以睡眠,也可以用在不可以睡眠的场景
- GFP_ATMOIC:常用中断处理程序、软中断、tasklet,不能用于睡眠的使用场景
7 参考资料
内核工匠(oppo)
深入理解Linux系统