电子商务网站用户行为分析及服务推荐
电子商务网站用户行为分析及服务推荐
目录
- 电子商务网站用户行为分析及服务推荐
- 实验介绍
- 背景与挖掘目标
- 分析方法与过程
- 数据抽取
- 数据探索分析
- 网页类型分型
- 点击次数分析
- 网页排名
- 数据预处理
- 数据清洗
- 数据变换
- 属性规约
- 模型构建——基于物品的协同过滤
- 模型分析
- 实验总结
实验介绍
背景与挖掘目标
本实验主要的研究对象是北京某家法律网站,是一家电子商务类的大型法律资讯网站。基于该网站用户的访问记录,研究用户的兴趣偏好,分析用户需求和行为,发现用户兴趣点,从而引导用户发现自己的信息需求,将长尾网页准确的推荐给所需用户,帮助用户发现潜在有用信息。
推荐系统和搜索引擎的不同在于,推荐系统不需要用户提供明确的要求,而是通过分析用户的历史行为,从而主动想用户推荐能够满足他们兴趣和需求的信息。
分析方法与过程
本实验的目标是对用户进行推荐,即通过协同过滤算法将用户与物品之间建立联系,并进行推荐。由于浏览网站的用户区别很大,不同的用户关注的信息不同。所以我们需要先对数据分析,以用户浏览网页的类型进行分类,然后对每个类型中的内容进行推荐。
分析的过程主要包括:
• 从系统中获取用户访问网站的原始记录。
• 对数据进行多维度分析。
• 对数据进行预处理。
• 对用户防卫的html页面进行数据处理
• 利用多种算法进行推荐,进行模型评价。
数据抽取
本实验使用的数据以用户的访问时间为条件,选取3个月内(2015-02-01~2015-04-29)用户的访问数据作为原始数据集。由于地区差异会导致查询内容不同,我们仅抽取广州地区的用户访问数据进行分析。
数据量共有837 450条记录。是本次课程中数据量最大的实验。
python中的pandas库本身可以利用read_sql()函数来读取数据库。有一个问题,pandas在读取数据时,都是将全部数据读入内存中,因此在数据量较大时是难以实现的。
但Pandas提供了chunksize参数,可以分块读取大文件。
代码实现如下:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
'''
用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据。
'''
数据探索分析
网页类型分型
对原始数据中的网页类型、点击次数和网页排名等各个维度进行分布分析,获得内在规律。
本节我们针对原始数据中用户点击的网页类型进行统计,网页类型是指“网址类型”中的前3位数字。
代码实现:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/mysql?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
'''
用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据。
'''
counts = [ i['fullURLId'].value_counts() for i in sql] #逐块统计
counts = pd.concat(counts).groupby(level=0).sum() #合并统计结果,把相同的统计项合并(即按index分组并求和)
counts = counts.reset_index() #重新设置index,将原来的index作为counts的一列。
counts.columns = ['index', 'num'] #重新设置列名,主要是第二列,默认为0
counts['type'] = counts['index'].str.extract('(\d{3})') #提取前三个数字作为类别id
counts['percent'] = counts['num']/counts['num'].sum()*100
counts_ = counts[['type', 'num','percent']].groupby('type').sum() #按类别合并
counts_.sort_values('num', ascending = False) #降序排列
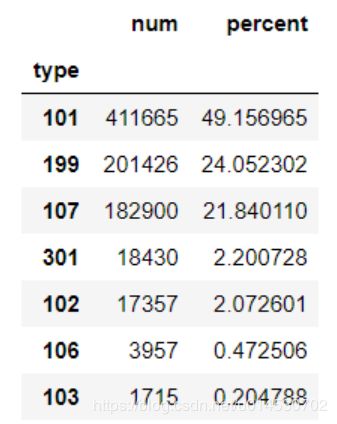
从统计结果中发现点击与咨询相关(101)的记录占了49.16%,其次是其他的类型(199)占比24%左右,然后是知识相关(107)占比22%左右。
由此统计得到用户点击的页面类型的排行榜为:咨询相关、知识相关、其他方面的网页、法规(301)、律师相关(102)。初步得到用户更加偏向于查看咨询或者进行咨询。
进一步对咨询类别内部进行统计分析,代码实现:
engine = create_engine('mysql+pymysql://root:[email protected]:3306/mysql?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
#统计101类别的情况
def count101(i): #自定义统计函数
j = i[['fullURLId']][i['fullURLId'].str.contains('101')].copy() #找出类别包含101的网址
return j['fullURLId'].value_counts()
counts2 = [count101(i) for i in sql] #逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() #合并统计结果
counts2 = pd.DataFrame(counts2)
counts2.columns=['num']
counts2['percent'] = counts2['num']/counts2['num'].sum()*100
counts2.sort_values('num', ascending = False) #降序排列
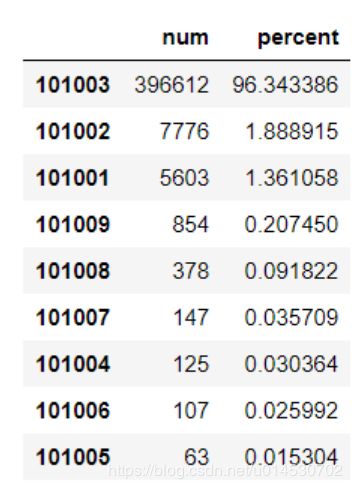
其中浏览咨询内容页记录(101003)最多,其次是咨询列表页(101002)和资源首页(101001)。综合上述初步结论,可以得出用户都喜欢通过浏览问题的方式找到自己需要的信息,而不是提问或者查看知识。
对知识类型内部进行统计分析,由于知识类型只有一种类型107001,我们依据网址进行分类,代码实现:
engine = create_engine('mysql+pymysql://root:[email protected]:3306/mysql?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
#统计107类别的情况
def count107(i): #自定义统计函数
j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() #找出类别包含107的网址
j['type'] = None #添加空列
j['type'][j['fullURL'].str.contains('info/.+?/')] = u'知识首页'
j['type'][j['fullURL'].str.contains('info/.+?/.+?')] = u'知识列表页'
j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')] = u'知识内容页'
return j['type'].value_counts()
counts2 = [count107(i) for i in sql] #逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() #合并统计结果
counts2 = pd.DataFrame(counts2)
counts2.columns=['num']
counts2['percent'] = counts2['num']/counts2['num'].sum()*100

由于其他类网页在总浏览量中占比为24%,属于较大数据。分析其他类(199)页面的情况,代码实现:
engine = create_engine('mysql+pymysql://root:[email protected]:3306/mysql?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
#统计1999001类别的情况
def count101(i): #自定义统计函数
j = i[['pageTitle']][i['fullURLId'].str.contains('1999001')].copy() #找出类别包含101的网址
j['type'] = u'其他'
j['type'][(j['pageTitle']!= '') &(j['pageTitle'].str.contains(u'快车-律师助手'))] = u'快车-律师助手'
j['type'][(j['pageTitle']!= '') &(j['pageTitle'].str.contains(u'免费发布法律咨询'))] = u'免费发布咨询'
j['type'][(j['pageTitle']!= '') &(j['pageTitle'].str.contains(u'咨询发布成功'))] = u'咨询发布成功'
j['type'][(j['pageTitle']!= '') &(j['pageTitle'].str.contains(u'快搜'))] = u'快搜'
return j['type'].value_counts()
counts2 = [count101(i) for i in sql] #逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() #合并统计结果
counts2 = pd.DataFrame(counts2)
counts2.columns=['num']
counts2['percent'] = counts2['num']/counts2['num'].sum()*100
counts2.sort_values('num', ascending = False) #降序排列
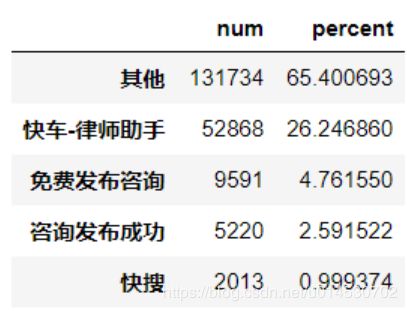
在这类网页中,标题为快车-律师助手的这类信息占比达到77%,这部分信息通过辨认是律师的一个登录页面,可以忽略。而其他带有“?”的页面记录占其记录的15%左右。这部分大多是被分享过的,对其处理后可以还原其原本类型。在快搜和免费发布咨询网址中,类型混杂,且数据占比量较小,本实验我们将其直接删去。
从上述网页类型分布分析中,可以发现一些与分析目标无关数据的规则:
- 咨询发布成功页面
- 中间类型页面(跳转页面)
- 快搜与发布咨询等混杂类型页面
- 重复数据
- 律师登录行为页面
点击次数分析
本节统计分析原始数据用户浏览网页次数的情况,代码实现:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/mysql?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
#统计点击次数
#value_count统计数据出现的频率
c = [i['realIP'].value_counts() for i in sql]
count3 = pd.concat(c).groupby(level=0).sum()
count3 = pd.DataFrame(count3)
count3[1] = 1
count3 = count3.groupby('realIP').sum()
count3_ =count3.iloc[:7,:].append(count3.iloc[7:,:].sum(),ignore_index=True)
count3_.index = list(range(1,8))+['7次以上']

浏览一次的用户占比达到58%左右,大部分用户浏览的次数在2~7次,用户浏览的平均次数为3次。大约80%的用户(不超过3次)只提供了大约30%的浏览量(二八定律)。在数据中,最大点击次数为42 790次,这次点击经判断为律师的浏览信息(通过律师助手),可以忽略。
对浏览次数达7次以上的情况进行分析,发现大部分用户浏览8~100次,代码实现:
counts3_7 = pd.concat([count3.iloc[7:100,:].sum(),count3.iloc[100:300,:].sum(),count3.iloc[300:,:].sum()])
counts3_7.index = ['8-100','101-300','301以上']
counts3_7df = pd.DataFrame(counts3_7)
counts3_7df.index.name = '点击次数'
counts3_7df.columns = ['用户数']

问题咨询页占比78%,知识页占比15%,而且通过对记录进行观察分析,这些记录大多是由搜索引擎进入的。可以对这些用户进行初步判断:
流失用户,在问题咨询与知识页面没有找到相关的需要。
- 用户找到其需要的信息,直接退出。
- 这种可被称为网页的跳出率,针对用户的个性化推荐的目的则是降低网页的跳出率。
针对点击一次的用户浏览的网页进行统计分析,看出排名靠前的都是知识与咨询页面,因此猜测大量用户的关注都在知识或咨询页面上。
网页排名
根据上两节分析目标可知,个性化推荐主要针对以html为后缀的网页。
首先对原始数据中统计以html为后缀的网页点击率,代码实现:
sql = pd.read_sql('all_gzdata', engine, chunksize=10000)
counts4 = [i[['realIP','fullURL','fullURLId']] for i in sql]
counts4_ = pd.concat(counts4)
a = counts4_[counts4_['fullURL'].str.contains('\.html')]
a.head()
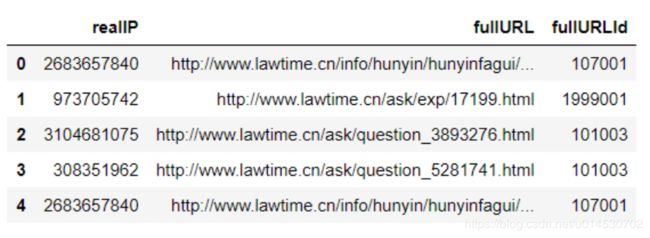
查看点击次数前20名,“法规专题”占了大部分,其次是“知识”,然后是“咨询”。我们可以看到知识页面相对咨询页面少很多,当大量用户在浏览咨询页面时,呈现一种比较分散的浏览次数,即每个页面的点击率都不高,但其总的浏览量高于知识。
类型点击数,代码实现:
pd.DataFrame(counts4_[-counts4_['realIP'].isin(a['realIP'])].drop_duplicates('fullURL').groupby('fullURLId').size()).sort_values(by=0,ascending=False)

数据预处理
本实验依据数据探索分析结果,发现与分析目标无关或模型需要处理的数据,针对此类数据进行处理。
我们将对数据通过数据清洗、数据集成和数据变换转化为建模数据。
数据清洗
数据清洗规则如下:
- 中间类型网页(跳转页面)
- 律师登录助手页面
- 咨询发布成功页面
- 快搜与免费发布咨询页面
- 重复记录
- 无.html点击行为的用户记录
- 主网址不含关键字
- 其他类别带有?的记录
本节将通过该规则将数据进行清洗, 并过滤出剩余记录中以html为后缀的网页。根据数据分析结果可知,咨询与知识是其主要业务来源,故需筛选咨询与知识相关的记录,将此部分数据作为模型分析需要的数据,代码实现:
sql = pd.read_sql('all_gzdata', engine, chunksize=10000)
for i in sql:
d = i[['realIP','fullURL']]
d = d[d['fullURL'].str.contains('\.html')].copy()
d.to_sql('cleaned_gzdata', engine, index = False, if_exists = 'append')
数据变换
对于网页翻页数据,将其还原为原始类别,再针对每个用户访问的页面进行去重操作。
代码实现:
for i in sql:
d = i.copy()
d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html','.html')
d = d.drop_duplicates()
d.to_sql('changed_gzdata', engine, index = False, if_exists='append')
由于部分网页所属类别需要人工分类,分类目标是分析咨询类别与知识类别。其中对网址中包含ask、askzt关键字的记录人为归类至咨询类别,对网址中包含zhishi、faguizt关键字的网址归类为知识类别。
代码实现:
for i in sql:
d = i.copy()
d['type_l'] = d['fullURL']
d['type_l_1'] = None
d['type_l_2'] = None
d['type_l'][d['fullURL'].str.contains('(ask)|(askzt)')] = 'zixun'
d['type_l'][d['fullURL'].str.contains('(info)|(zhishiku)')] = 'zhishi'
d['type_l'][d['fullURL'].str.contains('(faguizt)|(lifadongtai)')] = 'fagui'
d['type_l'][d['fullURL'].str.contains('(fayuan)|(gongan)|(jianyu)|(gongzhengchu)')] = 'jigou'
d['type_l'][d['fullURL'].str.contains('interview')]= 'fangtan'
d['type_l'][d['fullURL'].str.contains('d\d+(_\d)?(_p\d+)?\.html')] = 'zhengce'
d['type_l'][d['fullURL'].str.contains('baike')]= 'baike'
d['type_l'][d['type_l'].str.len()>15] = 'etc'
d[['type_l_1','type_l_2']]= d['fullURL'].str.extract('http://www.lawtime.cn/(info|zhishiku)/(?P[A-Za-z]+)/(?P[A-Za-z]+)/\d+\.html' ,expand=False).iloc[:,1:]
d.to_sql('splited_gzdata', engine, index = False, if_exists='append')
属性规约
由于推荐系统模型的输入数据需要,需对处理后的数据进行属性规约,提取模型需要的属性。本实验中模型需要的数据属性为用户和用户访问的网页。因此删除其他的属性。
使用数据为:
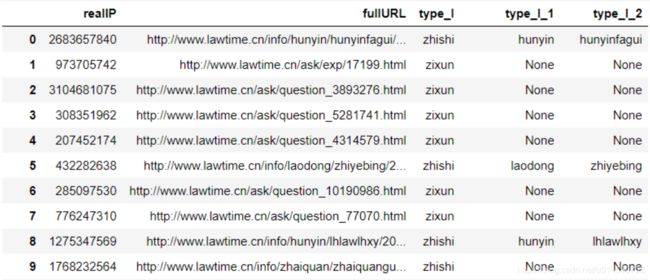
模型构建——基于物品的协同过滤
由于网页访问的性质,网页数明显小于用户数,本实验采用基于物品的协同过滤推荐系统对用户进行个性化推荐。基于物品的协同过滤系统的一般处理过程:分析用户与物品的数据集,通过用户对项目的浏览与否找到相似的物品,然后根据用户的历史爱好,推荐相似的项目给目标用户。
算法主要分为两步:
计算物品之间的相似度
根据物品相似度和用户的历史行为给用户生成推荐列表
本实验中我们采用杰卡德相似系数方法计算物品之间的相似度。
杰卡德相似系数方法:

两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。杰卡德相似系数是衡量两个集合的相似度一种指标。
代码实现:
import pandas as pd
import numpy as np
sql = pd.read_sql('splited_gzdata', engine, chunksize=10000)
c = [i for i in sql]
sample = pd.concat(c)
sample = pd.DataFrame(sample)
data = pd.crosstab(sample[sample['type_l_1']=='hunyin']['realIP'],sample[sample['type_l_1']=='hunyin']['fullURL'])
data_ = data.values
def Jaccard(a,b):
return abs(((a+b)//2).sum())/abs(np.ceil((a + b)/2).sum())
class Recommender:
sim = None
def similarity(self, x, distance):
y = np.ones((len(x),len(x)))
for i in range(len(x)):
for j in range(len(x)):
y[i,j] = distance(x[i], x[j])
return y
def fit(self, x, distance = Jaccard):
self.sim = self.similarity(x, distance)
def recommend(self, a):
return np.dot(self.sim, a)
r = Recommender()
r.fit(data_.T)
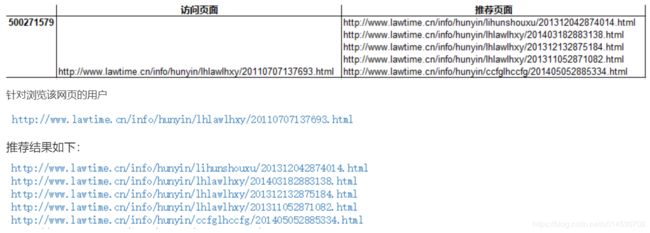
realid = 500271579
uid = list(data.index).index(realid)
sim_sort = pd.Series(r.recommend(data_[uid])).sort_values(ascending=False)
vind = sim_sort[sim_sort>=1].index
ind = sim_sort[(sim_sort>0)&(sim_sort<1)].index
for i in vind:
print(data.columns[i])
for i in ind:
print(data.columns[i])
c = pd.DataFrame({'访问页面':'\n'.join(data.columns[i] for i in vind),'推荐页面':'\n'.join(data.columns[i] for i in ind[:5])},index=[realid],columns=['访问页面', '推荐页面']).to_excel('123.xls')
模型分析
通过基于项目的协同过滤算法,针对每个用户进行推荐,推荐相似度排序前5的项目。对于婚姻类咨询,访问页面的主题为离婚协议书,基于我们的模型给用户推荐了相似度排名前5的网页,内容分别为离婚分割财产、离婚协议书范文、民政局对离婚协议书的要求、签订离婚协议是否可以反悔、协议离婚手续流程。
实验总结
本实验主要介绍协同过滤算法在电子商务领域中的应用,实现对用户的个性化推荐。通过对用户的访问日志的数据进行分析与处理,采用基于物品的协同过滤算法对处理后的数据进行建模分析,最后对模型结果进行分析。