Elasticsearch中什么是 tokenizer、analyzer、filter ?
Elastic search 是一个能快速帮忙建立起搜索功能的,最好之一的引擎。
搜索引擎的构建模块 大都包含 tokenizers(分词器), token-filter(分词过滤器)以及 analyzers(分析器)。
这就是搜索引擎对数据处理和存储的方式,所以,通过上面的3个模块,数据就可以被轻松快速的查找。
下面讨论下, tokenizers(分词器), token-filter(分词过滤器)以及 analyzers(分析器)是如何工作的?
Tokenizers(分词器)
分词,就是将一个字符串,按照特定的规则打散为多个小的字符串的过程,按照专业术语说法就是就是打散为token(符号)。
举个例子:
Whitespace tokenizer (空格分词器)
空格分词器将字符串,基于空格来打散。
还有很多其他的分词器,比如Letter tokenizer(字母分词器),字母分词器遇到非字母类型的符号,然后打散字符串。
例如:
Input => “quick 2 brown’s fox “
Output => [quick,brown,s,fox]
它仅仅保留字母,并且一处所有特殊字符以及数字,所以叫做字母分词器。
Token Filters(字符过滤器)
字符过滤器 ,是操作分词器处理后的字符结果,并且相应地修改字符。
举个简单的例子
Lowercase filter : 转小写过滤器,会将所有字符字母转为小写
Input => “QuicK”
Output => “quick”
Stemmer filter:除梗过滤器,根据特定的规则(可配置),会除去单词的一部分内容。
例子 1: 去除单词的时态
Input => “running”
Output => “run”
例子 2: 去除复数
Input => “shoes”
Output => “shoe”
Analyzer(分析器)
分析器是分词器和分词过滤器的结合,可以被应用到Elasticsearch的任何字段用来分析。这里有很多Elasticsearch内置的分析器。
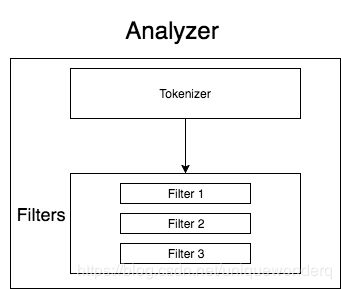
这里列举几个官方内置的分析器:
- Standard Analyzer(标准分析器)
标准分析器是最常被使用的分析器,它是基于统一的Unicode 字符编码标准的文本进行分割的算法,同时它也会消除所有的标点符号,将分词项小写,消除通用词等。
例如:
Input => “The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.”
Output => [quick, brown, fox, jump, over, lazy,dog, bone]
主题:移除所有的标点符号,数字,停用词 比如 the, s
而对于中文,标准分析器则是单字分割

- Whitespace Analyzer(空格分析器):空格分析器基于空格来划分文本。它 内部使用whitespace tokenizer来切割数据.
例如:
Input => “quick brown fox”
Output => [quick, brown, fox]
自定义Analyzer
就上面所说,分析器是分词器和过滤器的结合。所以,你可以按照你的需求定义你自己的分析器,从可以使用的分词器和过滤器。
那么如何定义呢?举个例子
{
"analyzer":{
"my_custom_analyzer":{
"type":"custom", // Define the type as custom analyzer
"tokenizer":"standard",//Define the tokenizer
"filter":[ // Define the toke Filter
"uppercase"
]
}
}
}
上面这个分析器的设置如下:
name — my_custom_analyzer
tokenizer — standard
filter — uppercase
运行结果:
Input => “Quick Brown Fox”
Output => [QUICK, BROWN, FOX]
如下的图,可以帮你更好地理解分析器处理数据的过程:
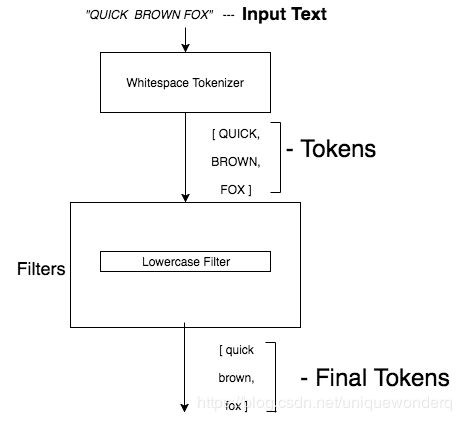
几个自定义分析器的例子如下:
1 ) 带有停用词和同义词的分析器
{
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase",
"english_stop",
"synonyms"
]
}
},
"filter":{
"english_stop":{
"type":"stop",
"stopwords":"_english_"
},
"synonym":{
"type":"synonym",
"synonyms":[
"i-pod, ipod",
"universe, cosmos"
]
}
}
}
}
}
运行如下:
Input => I live in this Universe
Output => [live, universe]
单词 [I, in , this] 都是停用词,被移除了,因为这些词在搜索的时候并没有什么用
2)带有除梗和停用词的分析器
{
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase",
"english_stop",
"english_stemmer"
]
}
},
"filter":{
"english_stemmer":{
"type":"stemmer",
"stopwords":"english"
},
"english_stop":{
"type":"stop",
"stopwords":"_english_"
}
}
}
}
}
运行如下:
Input => “Learning is fun”
Output => [learn, fun]
单词 “[is]” 作为停用词被移除, “learning” 除梗后变为 “learn”.
3)带有特殊符号映射为特定单词的分析器
{
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"char_filter":[
"replace_special_characters"
],
"tokenizer":"standard",
"filter":[
"lowercase"
]
}
},
"char_filter":{
"replace_special_characters":{
"type":"mapping",
"mappings":[
":) => happy",
":( => sad",
"& => and"
]
}
}
}
}
}
运行如下:
Input => Good weekend :)
Output => [good, weekend, happy]
Input => Pride & Prejudice
Output => [Pride, and, Prejudice]
请注意 :
这里我们使用char_filter而不是token_filter ,因为char_filter 在tokenizer 前会运行,因此避免了特殊字符,比如笑脸还有&连接符被后面的tokenizer 分隔开,或者token_filter移除。因此,你可以根据自己的需求来配置分析器,然后来获取更好地搜索结果。