python/c++读/存16bit图像 tensorflow--different inference result in python/c++
以前python下训练、验证模型,工程化到C++验证结果与python下一致。
这次python下重新搭建训练模型、验证模型,没问题,结果是正确的。但是当工程化到c++时发现c++结果不正确且与python下验证结果不一致。
python下训练代码部分如下:可以看到是采用decode_png方式读取图片数据
def get_batch(image, label, image_W, image_H, batch_size, capacity):
# step1:将上面生成的List传入get_batch() ,转换类型,产生一个输入队列queue
# tf.cast()用来做类型转换
image = tf.cast(image, tf.string)
# 可变长度的字节数组.每一个张量元素都是一个字节数组
label = tf.cast(label, tf.int32)
# tf.train.slice_input_producer是一个tensor生成器
# 作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
input_queue = tf.train.slice_input_producer([image, label])
label = input_queue[1]
image_contents = tf.read_file(input_queue[0])
# tf.read_file()从队列中读取图像
#print(image_contents)
#image=tf.py_func(lambda input:cv2.imread(input,flags=-1),[image_contents],tf.float32)
'''
imagepath=bytes.decode(image_contents)
imagecv=cv2.imread(imagepath,flags=-1)
image=tf.convert_to_tensor(imagecv)
'''
# step2:将图像解码,使用相同类型的图像
image = tf.image.decode_png(image_contents, channels=3,dtype=tf.uint16)
#print(image)
#2020.3.17
image=tf.image.resize_images(image,[image_W,image_H])
image.set_shape([image_W,image_H,3])
#print(image)
#image = array_ops.expand_dims(image, 0)
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
image = tf.image.transpose_image(image)
#print(image)
# 对resize后的图片进行标准化处理
image = tf.image.per_image_standardization(image)
# step4:生成batch
# image_batch: 4D tensor [batch_size, width, height, 3], dtype = tf.float32
# label_batch: 1D tensor [batch_size], dtype = tf.int32
image_batch, label_batch = tf.train.batch([image, label], batch_size=batch_size, num_threads=16, capacity=capacity)
# 重新排列label,行数为[batch_size]
label_batch = tf.reshape(label_batch, [batch_size])
# image_batch = tf.cast(image_batch, tf.uint8) # 显示彩色图像
image_batch = tf.cast(image_batch, tf.float32) # 显示灰度图
# print(label_batch) Tensor("Reshape:0", shape=(6,), dtype=int32)
#Change to ONE-HOT
label_batch = tf.one_hot(label_batch, depth= 2)
label_batch = tf.cast(label_batch, dtype=tf.int32)
label_batch = tf.reshape(label_batch, [batch_size, 2])
#print(label_batch)
#print(image_batch)
#https://blog.csdn.net/xiaomu_347/article/details/81040855
return image_batch, label_batch python下的验证代码如下:(也是decode_png读取图片)
import os
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
image_W=64;
image_H=64;
#use output directly
with tf.Session() as sess1:
sess1.run(tf.global_variables_initializer())
new_saver1 = tf.train.import_meta_graph(r'D:\wdxrt0305\0310\xrtmodel\0317model\model.meta')
new_saver1.restore(sess1,tf.train.latest_checkpoint(r'D:\wdxrt0305\0310\xrtmodel\0317model'))
graph1 = tf.get_default_graph()
input_x1 = graph1.get_tensor_by_name("input:0")
outputlabel = graph1.get_tensor_by_name("output:0")
PATH = 'E:/xrtcnn-20200305/imgs/objs/0.png'
image_dir = tf.gfile.FastGFile(PATH, 'rb').read()
imagepng = tf.image.decode_png(image_dir, channels=3,dtype=tf.uint16)
#2020.3.17
image2=tf.image.resize_images(imagepng,[image_W,image_H])#bilinear
#pngdata=image2.eval()
#print(pngdata)
image2.set_shape([image_W,image_H, 3])
image = tf.image.per_image_standardization(image2)
debug=image.eval()
print(debug)
feed_dict1={input_x1:np.reshape(debug, [-1,image_W,image_H,3])}
img_out_label = sess1.run(outputlabel,feed_dict1)
out_softmax1 = graph1.get_tensor_by_name("softmax:0")
img_out_softmax = sess1.run(out_softmax1,feed_dict1)
s1=img_out_softmax[0][0]
s2=img_out_softmax[0][1]
print("fei: ",s1," , kuang: ",s2)
print ("img_out_label:",img_out_label)
#del pngdata
del debug # memory leak
sess1.close()如上python验证代码中是用decode_png方式读取图片数据,我发现如果使用下面这两句替换decode_png预测也是一样的效果:
image_png=cv2.imread(PATH,flags=-1)
imagepng = image_png[...,::-1].astype(np.float32)虽然是opencv读取图片数据,读成数组。在tf.image.resize_images这句也可以接受数组的。反正两种方式读出来概率完全一样。
于是我按照python下的验证代码直接转c++下的验证代码基本如下:
/////////////////////////////////////find the difference between python inference and c++ inference
int main()//xrtCnnPredict()//
{
int standard_rows=64;
int standard_cols=standard_rows;
string graphpath="/media/root/Ubuntu311/projects/Xrt_projects/XRT_CNN_Primer/xrtmodel/0317model/model.meta";
string modelpath="/media/root/Ubuntu311/projects/Xrt_projects/XRT_CNN_Primer/xrtmodel/0317model/model";
///////CNN initiation--
tensorflow::Session* session;
tensorflow::Status status = NewSession(tensorflow::SessionOptions(), &session);
if (!status.ok())
{
std::cout << "ERROR: NewSession() init failed..." << std::endl;
return -1;
}
tensorflow::MetaGraphDef graphdef;
tensorflow::Status status_load = ReadBinaryProto(tensorflow::Env::Default(), graphpath, &graphdef); //从meta文件中读取图模型;
if (!status_load.ok()) {
std::cout << "ERROR: Loading model failed..." << std::endl;
std::cout << status_load.ToString() << "\n";
return -1;
}
tensorflow::Status status_create = session->Create(graphdef.graph_def()); //将模型导入会话Session中;
if (!status_create.ok()) {
std::cout << "ERROR: Creating graph in session failed..." << status_create.ToString() << std::endl;
return -1;
}
// 读入预先训练好的模型的权重
tensorflow::Tensor checkpointPathTensor(tensorflow::DT_STRING, tensorflow::TensorShape());
checkpointPathTensor.scalar()() = modelpath;
status = session->Run(
{{ graphdef.saver_def().filename_tensor_name(), checkpointPathTensor },},
{},{graphdef.saver_def().restore_op_name()},nullptr);
if (!status.ok())
{
throw runtime_error("Error loading checkpoint for long algaes ...");
}
///////CNN put in images--
char srcfile[300];
char feifile[300];
char orefile[300];
int all=0;
for(int idx=3260;idx<=5844;idx++)
{
sprintf(srcfile, "/media/root/77B548B10AEA26F1/problemimg/problemtest/%d.png", idx);
Mat src=imread(srcfile,-1);
if(!src.data)
{
//cout<<"warning:the image does not exist!"<(r)[3*c]<<","<(r)[3*c+1]<<","<(r)[3*c+2]<<"] ";
cout<<"("<(r)[3*c+1]<<") ";
}
cout<(r)[3*c]=rgbsrc.ptr(r)[3*c+2];
srccnn.ptr(r)[3*c+1]=rgbsrc.ptr(r)[3*c+1];
srccnn.ptr(r)[3*c+2]=rgbsrc.ptr(r)[3*c];
//cout<<"[("<(r)[3*c]<<","<(r)[3*c+1]<<","<(r)[3*c+2]<<"] ";
}
//cout<(r)[3*c]<<","<(r)[3*c+1]<<","<(r)[3*c+2]<<"] ";
cout<<"("<(r)[3*c+1]<<") ";
}
cout<().data();
cv::Mat cnninputImg(standard_rows, standard_cols, CV_32FC3, imgdata);
//归一化差别较大
//标准化差别较小
int pixelsnum=standard_rows*standard_cols;
cv::Mat dstimgs(standard_rows, standard_cols, CV_32FC3);
standardImageProcess(srccnn,dstimgs,pixelsnum);
dstimgs.copyTo(cnninputImg);
/*
for(int r=0;r!=20;r++)
{
for(int c=0;c!=standard_cols;c++)
{
//cout<<"[("<(r)[3*c]<<","<(r)[3*c+1]<<","<(r)[3*c+2]<<"] ";
cout<<"("<(r)[3*c]<<") ";
}
cout< > inputs;
std::string Input1Name = "input";
inputs.push_back(std::make_pair(Input1Name, resized_tensor));
//CNN predict
vector outputs;
string output="softmax";//output:0
tensorflow::Status status_run = session->Run(inputs, {output}, {}, &outputs);
if (!status_run.ok()) {
std::cout << "ERROR: RUN failed in PreAlgaeRecognitionProcess()..." << std::endl;
std::cout << status_run.ToString() << "\n";
}
int label=-1;
double prob=0.0;
// cout<<"image "< void standardImageProcess(Mat channel3imgs,Mat &dstimgs,int pixelsnum)
{
vector bgrimgs;
cv::split(channel3imgs,bgrimgs);
Mat meanbimg,stddevbimg;
Mat bimg=bgrimgs[0];
cv::meanStdDev(bimg,meanbimg,stddevbimg);
float bmean=meanbimg.at(0);
float bstddev=stddevbimg.at(0);
Mat bimgdst(bimg.rows,bimg.cols,CV_32FC1);
//subtract(bimg, bmean, bimg);
//bimgdst = bimg / bstddev;
imagestandard(bimg,bmean,bstddev,pixelsnum,bimgdst);
Mat meangimg,stddevgimg;
Mat gimg=bgrimgs[1];
cv::meanStdDev(gimg,meangimg,stddevgimg);
float gmean=meangimg.at(0);
float gstddev=stddevgimg.at(0);
Mat gimgdst(bimg.rows,bimg.cols,CV_32FC1);
//subtract(gimg, gmean, gimg);
//gimgdst = gimg / gstddev;
imagestandard(gimg,gmean,gstddev,pixelsnum,gimgdst);
Mat meanrimg,stddevrimg;
Mat rimg=bgrimgs[2];
cv::meanStdDev(rimg,meanrimg,stddevrimg);
float rmean=meanrimg.at(0,0);
float rstddev=stddevrimg.at(0,0);
Mat rimgdst(bimg.rows,bimg.cols,CV_32FC1);
//subtract(rimg, rmean, rimg);
//rimgdst = rimg / rstddev;
imagestandard(rimg,rmean,rstddev,pixelsnum,rimgdst);
vector dstimgsvec;
dstimgsvec.push_back(bimgdst);
dstimgsvec.push_back(gimgdst);
dstimgsvec.push_back(rimgdst);
cv::merge(dstimgsvec,dstimgs);
}
void imagestandard(Mat &channel1img,float mean,float std,int pixelsnum,Mat &imgdst)
{
float thre=1.0/pixelsnum;
for(int r=0;r!=channel1img.rows;r++)
{
for(int c=0;c!=channel1img.cols;c++)
{
float x=channel1img.ptr(r)[c];
imgdst.ptr(r)[c]=(x-mean)/max(std,thre);
}
}
}
int getPredictLabel(tensorflow::Tensor &probabilities,int &output_class_id,double &output_prob)
{
int ndim2 = probabilities.shape().dims(); // Get the dimension of the tensor
auto tmap = probabilities.tensor(); // Tensor Shape: [batch_size, target_class_num]
int output_dim = probabilities.shape().dim_size(1); // Get the target_class_num from 1st dimension
std::vector tout;
// Argmax: Get Final Prediction Label and Probability
for (int j = 0; j < output_dim; j++)
{
//std::cout << "Class " << j << " prob:" << tmap(0, j) << "," << std::endl;
if (tmap(0, j) >= output_prob) {
output_class_id = j;
output_prob = tmap(0, j);
}
}
std::cout <<" prob:" << tmap(0, 0) << " , "< 当我使用的同样的一张图片、同样的模型,出来结果相差很大,类别都不一样。
于是我一步步找差别,发现:
一、读存16bit图像不一样
python验证代码中两种读取数据都是按r,g,b方式来的,而opencv是b,g,r!!!所以必须先对imread后的结果通道转换。
也就是上面所示的这句:
imagepng = image_png[...,::-1].astype(np.float32)c++笨拙写的这样:
Mat srcrgb(src.rows, src.cols, CV_16UC3);
for(int r=0;r!=src.rows;r++)
{
for(int c=0;c!=src.cols;c++)
{
srcrgb.ptr(r)[3*c]=src.ptr(r)[3*c+2];
srcrgb.ptr(r)[3*c+1]=src.ptr(r)[3*c+1];
srcrgb.ptr(r)[3*c+2]=src.ptr(r)[3*c];
}
} 经过对比每个像素点的数据,发现python和c++下每个数据已统一。
二、resize方式
我查看了下python和c++下的resize方式是一样的,都是双线性插值法。但是python下tf.image.resize与c++下cv::resize后的数据对比发现很不一样。不止是float与ushort的差别,是每个像素点的数据的问题!
三、标准化方式
python下的标准化是直接调用tf.image.per_image_standardization;而C++没有现成的函数,我试过归一化结果与tf.image.per_image_standardization差别较大,于是只能按公式像上面给出的那样写了一个函数,差别出来比较接近。但还是有一点差别。
但是即使以上三点差别,第二、三点的综合差别竟然导致c++/python预测类别不一致啊,你说概率不一致还能理解,但类别都不一样?!!!
我查了很多方式但并未直接解决这个问题。
有一个问题我很疑惑,python下:训练模型时是decode_png读图,然后使用tf.image.resize...等预处理训练图片,那是否python验证时也一定要decode_png读图、tf.image.resize来处理验证图??事实证明,如果也这样做,预测出来的结果是正确的(因为和训练中处理图片的代码一样)(预测出来概率是[0.9297426 , 0.07025738])。但如果不这样做,比如python下加载这个模型用cv2.imread、cv2.resize(和训练处理图片代码不同)来处理验证同一张图片,发现预测出来概率是[0.83095837, 0.1690416]。我知道这张图片实际是第一类,这样看这两种方式验证类别是正确的,但是概率不一样,到底是第一种方式概率正确还是第二种???????如果是第一种,那没办法c++工程化,因为c++下无法tf.image.resize。如果第二种方式正确,完全可以c++工程化而且与python下验证结果包括概率都一样。
我目前用的第二种方式,若有人知道,望解答。
最近发现一个博主写得好,在跟着学习: https://blog.csdn.net/u010712012/category_8126761.html
在跟着这个博主做实例:https://blog.csdn.net/qq_41776781/article/details/94452085
1、AlexNet
import tensorflow as tf
import numpy as np
from tensorflow.python.framework import dtypes
from tensorflow.python.framework.ops import convert_to_tensor
#from tensorflow.data import Dataset
img_size=64
#VGG_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32)
# 把图片数据转化为三维矩阵
class ImageDataGenerator(object):
def __init__(self, images, labels, batch_size, num_classes, image_format='png', shuffle=True):
self.img_paths = images # [P1,P2]
self.labels = labels # [1,2]
self.data_size = len(self.labels)
self.num_classes = num_classes
self.image_format = image_format
if shuffle:
self._shuffle_lists()
self.img_paths = convert_to_tensor(self.img_paths, dtype=dtypes.string)
self.labels = convert_to_tensor(self.labels, dtype=dtypes.int32)
data = tf.data.Dataset.from_tensor_slices((self.img_paths, self.labels))
data = data.map(self._parse_function_train)
data = data.batch(batch_size)
self.data = data
# 打乱图片顺序
def _shuffle_lists(self):
path = self.img_paths
labels = self.labels
permutation = np.random.permutation(self.data_size)
self.img_paths = []
self.labels = []
for i in permutation:
self.img_paths.append(path[i])
self.labels.append(labels[i])
# 把图片生成三维数组,以及把标签转化为向量
def _parse_function_train(self, filename, label):
one_hot = tf.one_hot(label, self.num_classes)
img_string = tf.read_file(filename)
if self.image_format == "jpg": # 增加图片类别区分
img_decoded = tf.image.decode_jpeg(img_string, channels=3,dtype=tf.uint16)
elif self.image_format == "png":
img_decoded = tf.image.decode_png(img_string, channels=3,dtype=tf.uint16)
else:
print("Error! Can't confirm the format of images!")
img_resized = tf.image.resize_images(img_decoded, [img_size, img_size])
img_resized.set_shape([img_size,img_size,3])
image = tf.image.random_flip_left_right(img_resized)
image = tf.image.random_flip_up_down(image)
image = tf.image.transpose_image(image)
image = tf.cast(image, tf.float32) * (1. / 65535)import tensorflow as tf
def alexnet(x, keep_prob, num_classes):
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 96], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(x, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[96], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
# lrn1
with tf.name_scope('lrn1') as scope:
lrn1 = tf.nn.local_response_normalization(conv1,
alpha=1e-4,
beta=0.75,
depth_radius=2,
bias=2.0)
# pool1
with tf.name_scope('pool1') as scope:
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID')
# conv2
with tf.name_scope('conv2') as scope:
pool1_groups = tf.split(axis=3, value = pool1, num_or_size_splits = 2)
kernel = tf.Variable(tf.truncated_normal([5, 5, 48, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value = kernel, num_or_size_splits = 2)
conv_up = tf.nn.conv2d(pool1_groups[0], kernel_groups[0], [1,1,1,1], padding='SAME')
conv_down = tf.nn.conv2d(pool1_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up, bias_down])
conv2 = tf.nn.relu(bias, name=scope)
# lrn2
with tf.name_scope('lrn2') as scope:
lrn2 = tf.nn.local_response_normalization(conv2,
alpha=1e-4,
beta=0.75,
depth_radius=2,
bias=2.0)
# pool2
with tf.name_scope('pool2') as scope:
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID')
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
# conv4
with tf.name_scope('conv4') as scope:
conv3_groups = tf.split(axis=3, value=conv3, num_or_size_splits=2)
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value=kernel, num_or_size_splits=2)
conv_up = tf.nn.conv2d(conv3_groups[0], kernel_groups[0], [1, 1, 1, 1], padding='SAME')
conv_down = tf.nn.conv2d(conv3_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up,bias_down])
conv4 = tf.nn.relu(bias, name=scope)
# conv5
with tf.name_scope('conv5') as scope:
conv4_groups = tf.split(axis=3, value=conv4, num_or_size_splits=2)
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
kernel_groups = tf.split(axis=3, value=kernel, num_or_size_splits=2)
conv_up = tf.nn.conv2d(conv4_groups[0], kernel_groups[0], [1, 1, 1, 1], padding='SAME')
conv_down = tf.nn.conv2d(conv4_groups[1], kernel_groups[1], [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
biases_groups = tf.split(axis=0, value=biases, num_or_size_splits=2)
bias_up = tf.nn.bias_add(conv_up, biases_groups[0])
bias_down = tf.nn.bias_add(conv_down, biases_groups[1])
bias = tf.concat(axis=3, values=[bias_up,bias_down])
conv5 = tf.nn.relu(bias, name=scope)
# pool5
with tf.name_scope('pool5') as scope:
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='SAME',)
print('alexNet中最后一层卷积层的形状是:', pool5.shape)
# flattened6
with tf.name_scope('flattened6') as scope:
flattened = tf.reshape(pool5, shape=[-1, 2*2*256])
# fc6
with tf.name_scope('fc6') as scope:
weights = tf.Variable(tf.truncated_normal([2*2*256, 4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.xw_plus_b(flattened, weights, biases)
fc6 = tf.nn.relu(bias)
# dropout6
with tf.name_scope('dropout6') as scope:
dropout6 = tf.nn.dropout(fc6, keep_prob)
# fc7
with tf.name_scope('fc7') as scope:
weights = tf.Variable(tf.truncated_normal([4096,4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.xw_plus_b(dropout6, weights, biases)
fc7 = tf.nn.relu(bias)
# dropout7
with tf.name_scope('dropout7') as scope:
dropout7 = tf.nn.dropout(fc7, keep_prob)
# fc8
with tf.name_scope('fc8') as scope:
weights = tf.Variable(tf.truncated_normal([4096, num_classes],
dtype=tf.float32,
stddev=1e-1), name='weights')
biases = tf.Variable(tf.constant(0.0, shape=[num_classes], dtype=tf.float32),
trainable=True, name='biases')
fc8 = tf.nn.xw_plus_b(dropout7, weights, biases)"""
Created on Sun Mar 29 15:32:17 2020
https://blog.csdn.net/qq_41776781/article/details/94452085
@author: 90467
"""
import os
import numpy as np
import tensorflow as tf
from alexnetright import alexnet
from datageneratorright import ImageDataGenerator
#from datetime import datetime
import glob
from tensorflow.data import Iterator
import matplotlib.pyplot as plt
# 初始参数设置
img_size=64
learning_rate = 1e-3
num_epochs = 20 # 代的个数 之前是10
train_batch_size = 200 # 之前是1024
#test_batch_size = 100
dropout_rate = 0.5
num_classes = 2 # 类别标签
display_step = 2 # display_step个train_batch_size训练完了就在tensorboard中写入loss和accuracy
# need: display_step <= train_dataset_size / train_batch_size
'''
filewriter_path = "./tmp/tensorboard" # 存储tensorboard文件
checkpoint_path = "./tmp/checkpoints" # 训练好的模型和参数存放目录
'''
image_format = 'png' # 数据集的数据类型
file_name_of_class = ['fei','kuang'] # fei对应标签0,kuang对应标签1。默认图片包含独特的名词,比如类别
train_dataset_paths = ['D:/wdxrt0305/0310/images/0325/train/fei/','D:/wdxrt0305/0310/images/0325/train/kuang/'] # 指定训练集数据路径(根据实际情况指定训练数据集的路径)
#test_dataset_paths = ['G:/Lab/Data_sets/catanddog/test/cat/',
# 'G:/Lab/Data_sets/catanddog/test/dog/'] # 指定测试集数据路径(根据实际情况指定测试数据集的路径)
# 注意:默认数据集中的样本文件名称中包含其所属类别标签的名称,即file_name_of_class中的名称
# 初始参数设置完毕
# 训练数据集数据处理
train_image_paths = []
train_labels = []
# 打开训练数据集目录,读取全部图片,生成图片路径列表
for train_dataset_path in train_dataset_paths:
length = len(train_image_paths)
train_image_paths[length:length] = np.array(glob.glob(train_dataset_path + '*.' + image_format)).tolist()
for image_path in train_image_paths:
image_file_name = image_path.split('/')[-1]
for i in range(num_classes):
if file_name_of_class[i] in image_file_name:
train_labels.append(i)
break
# get Datasets
# 调用图片生成器,把训练集图片转换成三维数组
train_data = ImageDataGenerator(
images=train_image_paths,
labels=train_labels,
batch_size=train_batch_size,
num_classes=num_classes,
image_format=image_format,
shuffle=True)
# get Iterators
with tf.name_scope('input'):
# 定义迭代器
train_iterator = Iterator.from_structure(train_data.data.output_types,
train_data.data.output_shapes)
training_initalizer=train_iterator.make_initializer(train_data.data)
#test_iterator = Iterator.from_structure(test_data.data.output_types,test_data.data.output_shapes)
#testing_initalizer=test_iterator.make_initializer(test_data.data)
# 定义每次迭代的数据
train_next_batch = train_iterator.get_next()
#test_next_batch = test_iterator.get_next()
x = tf.placeholder(tf.float32, [None, img_size, img_size, 3])
y = tf.placeholder(tf.float32, [None, num_classes])
keep_prob = tf.placeholder(tf.float32)
# alexnet
fc8 = alexnet(x, keep_prob, num_classes)
# loss
with tf.name_scope('loss'):
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=fc8,
labels=y))
# optimizer
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# accuracy
with tf.name_scope("accuracy"):
correct_pred = tf.equal(tf.argmax(fc8, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
'''
# Tensorboard
tf.summary.scalar('loss', loss_op)
tf.summary.scalar('accuracy', accuracy)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(filewriter_path)
'''
#开启GPU运算
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
# 定义一代的迭代次数
train_batches_per_epoch = int(np.floor(train_data.data_size / train_batch_size))
#test_batches_per_epoch = int(np.floor(test_data.data_size / test_batch_size))
allnum=int(np.floor(train_batches_per_epoch*num_epochs))
fig_accuracy = np.zeros(allnum)
fig_loss = np.zeros(allnum)
fig_i=0
sess = tf.Session(config=config)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for epoch in np.arange(num_epochs):
if coord.should_stop():
break
sess.run(training_initalizer)
print("Epoch number: {} start".format(epoch + 1))
# train
for step in range(train_batches_per_epoch):
img_batch, label_batch = sess.run(train_next_batch)
#print(img_batch.shape,'\n',label_batch.shape)
loss,_ = sess.run([loss_op,train_op], feed_dict={x: img_batch,y: label_batch,keep_prob: dropout_rate})
acc = sess.run(accuracy, feed_dict={x: img_batch,y: label_batch,keep_prob: dropout_rate})
if step % display_step == 0:
print("index[%s]".center(50,'-')%epoch)
print("Train: loss:{},accuracy:{}".format(loss,acc))
saver.save(sess,r'D:/wdxrt0305/0310/xrtmodel/0327jinxingmodel/model')
fig_loss[fig_i] =loss
fig_accuracy[fig_i] =acc
fig_i=fig_i+1
# 绘制曲线
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
lns1 = ax1.plot(np.arange(allnum), fig_loss, label="Loss")
# 按一定间隔显示实现方法#
ax2.plot(np.arange(len(fig_accuracy)), fig_accuracy, 'r')
lns2 = ax2.plot(np.arange(allnum), fig_accuracy, 'r', label="Accuracy")
ax1.set_xlabel('iteration')
ax1.set_ylabel('training loss')
ax2.set_ylabel('training accuracy')
# 合并图例
lns = lns1 + lns2
labels = ["Loss", "Accuracy"]
# labels = [l.get_label() for l in lns]
plt.legend(lns, labels, loc=7)
plt.show()
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
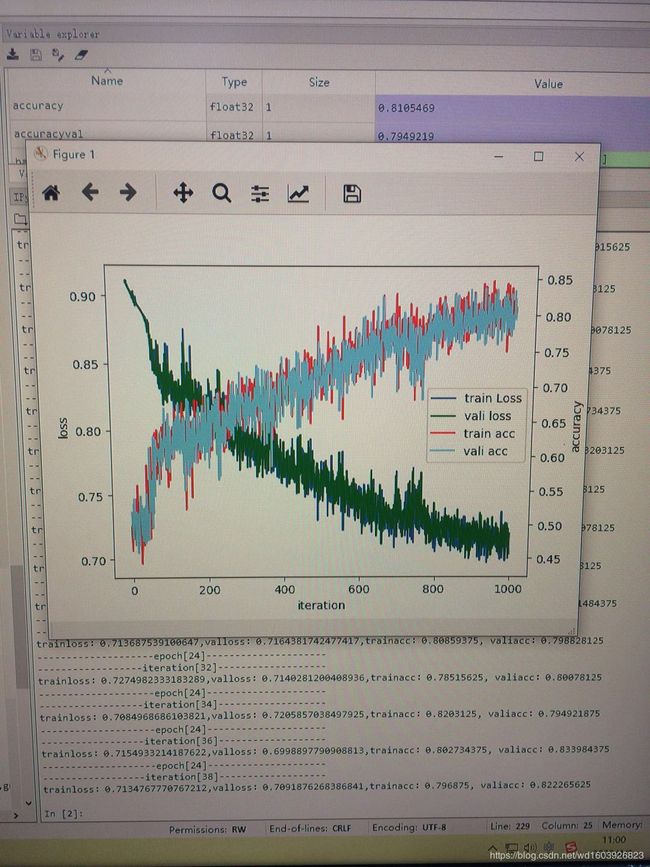
sess.close()曲线:
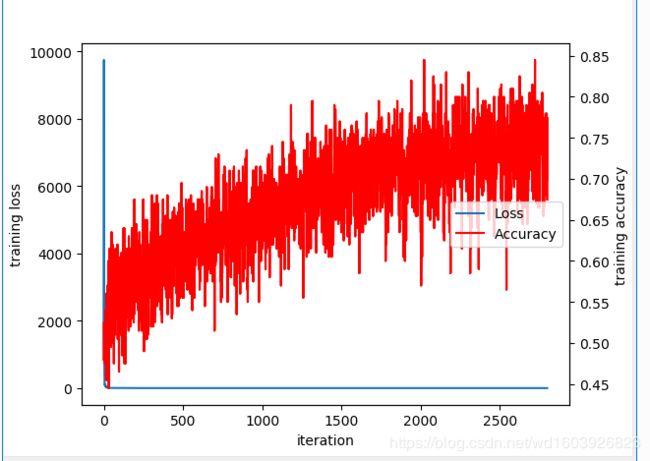 我知道这么看训练acc整体是上升的,但震荡较大(调lr好像没用,据说是因为每个batch的图片不一样,所以有震荡是正常?),但训练loss变化幅度和训练acc不同步,这里loss下降太快,怎么会这样?
我知道这么看训练acc整体是上升的,但震荡较大(调lr好像没用,据说是因为每个batch的图片不一样,所以有震荡是正常?),但训练loss变化幅度和训练acc不同步,这里loss下降太快,怎么会这样?
还不如之前的一个简单的训练模型:
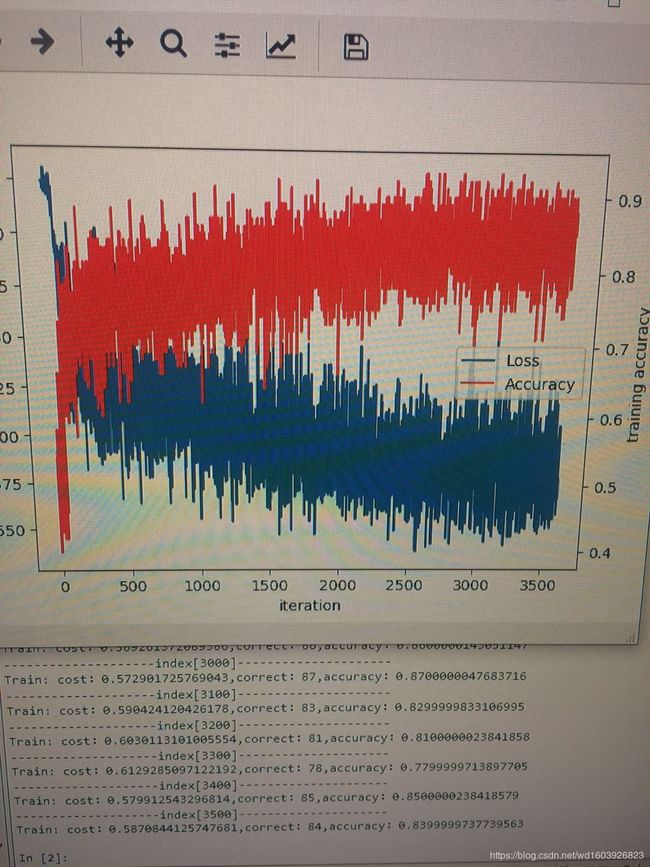 这个变化loss与acc是同步的,而且准确率还高些。
这个变化loss与acc是同步的,而且准确率还高些。
今天在学习了这个大神 https://blog.csdn.net/han_xiaoyang/article/list/1?t=1&orderby=UpdateTime 相关文章的分析网络调节网络技巧后,我将上图这个网络进行了调节,然后曲线图如下:
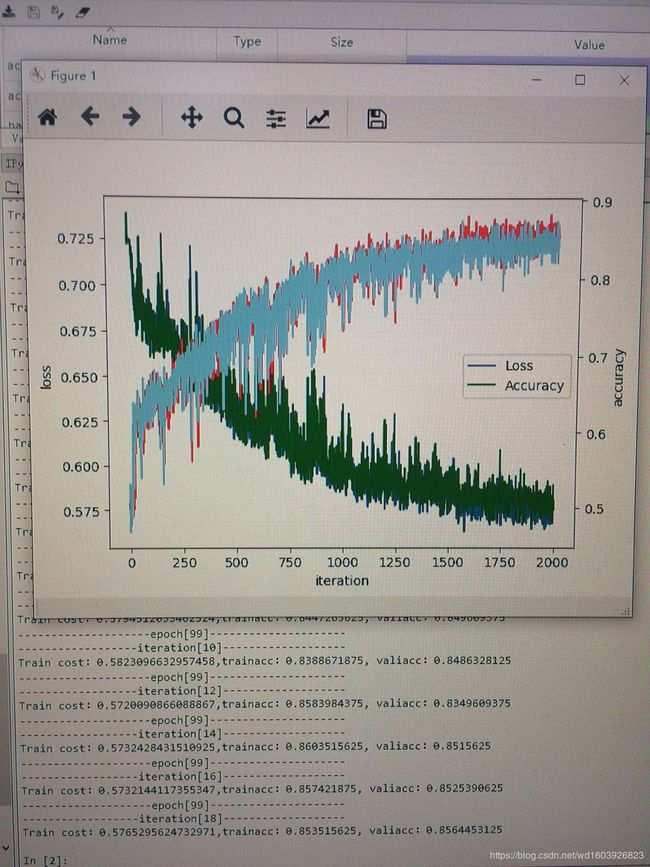 蓝色绿色分别是训练和验证loss,红色和天蓝色分别是训练和验证的acc。但是trainloss与valloss曲线非常贴近(几乎重合),train_acc和val_acc的曲线也非常贴近(几乎重合)。这种现象正常吗?我看别人的曲线好像虽然trainloss和valloss都下降,但曲线不会很贴近,train和val的acc曲线也是走势都上升,但不会贴近??在我现在的认知里我觉得这个模型学习能力很强,但我将这个模型在测试集上测试时测试效果不如人意,我现在在怀疑是测试集的分布情况与训练集验证集差别很大?我不知道除此之外还应怀疑什么?但是数据分布差别不大啊,都是随机的。我同事说这是过拟合?!
蓝色绿色分别是训练和验证loss,红色和天蓝色分别是训练和验证的acc。但是trainloss与valloss曲线非常贴近(几乎重合),train_acc和val_acc的曲线也非常贴近(几乎重合)。这种现象正常吗?我看别人的曲线好像虽然trainloss和valloss都下降,但曲线不会很贴近,train和val的acc曲线也是走势都上升,但不会贴近??在我现在的认知里我觉得这个模型学习能力很强,但我将这个模型在测试集上测试时测试效果不如人意,我现在在怀疑是测试集的分布情况与训练集验证集差别很大?我不知道除此之外还应怀疑什么?但是数据分布差别不大啊,都是随机的。我同事说这是过拟合?!
然后我减小模型容量,因为训练集就20000,加了L2正则化和dropout,发现又欠拟合,然后我去掉了dropout,只在训练集加入了L2正则化:
import numpy as np
import tensorflow as tf
from xrtPrecess import get_files_list,get_file, get_batch
import math
from tensorflow.python.framework import graph_util
import matplotlib.pyplot as plt
# 变量声明
N_CLASSES = 2
IMG_W = 64 # resize图像,太大的话训练时间久
IMG_H = 64
train_dir =r'D:\wdxrt0305\0331\train'
#train, train_label= get_files_list(train_dir)
train, train_label,test,test_label = get_file(train_dir)
trainnum=len(train_label)
lr = tf.placeholder(tf.float32)
learning_rate = lr
def build_network(channel,keep_prob,is_training=True):
X = tf.placeholder(tf.float32, shape=(None,IMG_W,IMG_H,3), name='input')
Y = tf.placeholder(tf.int32, shape=(None,N_CLASSES), name='Y')
def weight_variable(shape, n):
initial = tf.truncated_normal(shape, stddev=n, dtype=tf.float32)
return initial
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape, dtype=tf.float32)
return initial
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x, name):
return tf.nn.max_pool(x, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
# 搭建网络
# 第一层卷积
# 第一二参数值得卷积核尺寸大小,即patch;第三个参数是通道数;第四个是卷积核个数
with tf.variable_scope('conv1') as scope:
# 所谓名字的scope,指当绑定了一个名字到一个对象的时候,该名字在程序文本中的可见范围
w_conv1 = tf.Variable(weight_variable([3, 3, 3, 64], 1.0), name='weights', dtype=tf.float32)
b_conv1 = tf.Variable(bias_variable([64]), name='biases', dtype=tf.float32) # 64个偏置值
# tf.nn.bias_add 是 tf.add 的一个特例:tf.add(tf.matmul(x, w), b) == tf.matmul(x, w) + b
# h_conv1 = tf.nn.relu(tf.nn.bias_add(conv2d(images, w_conv1), b_conv1), name=scope.name)
tmp1=conv2d(X, w_conv1)+b_conv1
#h_conv1 = tf.nn.relu(tf.nn.dropout(tmp1,keep_prob), name='conv1') # 得到128*128*64(假设原始图像是128*128)
h_conv1 = tf.nn.relu(tmp1, name='conv1')
# 第一层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作,局部响应归一化,增强了模型的泛化能力。
# tf.nn.lrn(input,depth_radius=None,bias=None,alpha=None,beta=None,name=None)
with tf.variable_scope('pooling1_lrn') as scope:
pool1 = max_pool_2x2(h_conv1, 'pooling1') # 得到64*64*64
norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm1')
# 第二层卷积
# 32个3x3的卷积核(16通道),padding=’SAME’,表示padding后卷积的图与原图尺寸一致,激活函数relu()
with tf.variable_scope('conv2') as scope:
w_conv2 = tf.Variable(weight_variable([3, 3, 64, 32], 0.1), name='weights', dtype=tf.float32)
b_conv2 = tf.Variable(bias_variable([32]), name='biases', dtype=tf.float32) # 32个偏置值
tmp2=conv2d(norm1, w_conv2)+b_conv2
#h_conv2 = tf.nn.relu(tf.nn.dropout(tmp2,keep_prob), name='conv2') # 得到64*64*32
h_conv2 = tf.nn.relu(tmp2, name='conv2')
# 第二层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作
with tf.variable_scope('pooling2_lrn') as scope:
pool2 = max_pool_2x2(h_conv2, 'pooling2') # 得到32*32*32
norm2 = tf.nn.lrn(pool2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm2')
# 第三层卷积
# 16个3x3的卷积核(16通道),padding=’SAME’,表示padding后卷积的图与原图尺寸一致,激活函数relu()
with tf.variable_scope('conv3') as scope:
w_conv3 = tf.Variable(weight_variable([3, 3, 32, 16], 0.1), name='weights', dtype=tf.float32)
b_conv3 = tf.Variable(bias_variable([16]), name='biases', dtype=tf.float32) # 16个偏置值
tmp3=conv2d(norm2, w_conv3)+b_conv3
#h_conv3 = tf.nn.relu(tf.nn.dropout(tmp3,keep_prob), name='conv3') # 得到32*32*16
h_conv3 = tf.nn.relu(tmp3, name='conv3')
# 第三层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作
with tf.variable_scope('pooling3_lrn') as scope:
pool3 = max_pool_2x2(h_conv3, 'pooling3') # 得到16*16*16
norm3 = tf.nn.lrn(pool3, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm3')
'''
with tf.variable_scope('conv4') as scope:
w_conv4_1 = tf.Variable(weight_variable([3, 3, 16, 24], 0.1), name='weights', dtype=tf.float32)
b_conv4_1 = tf.Variable(bias_variable([24]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv4_1 = tf.nn.relu(conv2d(norm3, w_conv4_1)+b_conv4_1, name='conv4_1')
w_conv4_2 = tf.Variable(weight_variable([5, 5, 16, 24], 0.1), name='weights', dtype=tf.float32)
b_conv4_2 = tf.Variable(bias_variable([24]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv4_2 = tf.nn.relu(conv2d(norm3, w_conv4_2)+b_conv4_2, name='conv4_2')
w_conv4_3 = tf.Variable(weight_variable([7, 7, 16, 24], 0.1), name='weights', dtype=tf.float32)
b_conv4_3 = tf.Variable(bias_variable([24]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv4_3 = tf.nn.relu(conv2d(norm3, w_conv4_3)+b_conv4_3, name='conv4_3')
h_conv4 = tf.concat((h_conv4_1,h_conv4_2,h_conv4_3),axis=3, name='conv4')
with tf.variable_scope('pooling4_lrn') as scope:
pool4 = max_pool_2x2(h_conv4, 'pooling4') # 得到16*16*16
norm4 = tf.nn.lrn(pool4, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm4')
with tf.variable_scope('conv5') as scope:
w_conv5_1 = tf.Variable(weight_variable([1, 1, 24, 64], 0.1), name='weights', dtype=tf.float32)
#print(norm4.shape,' ',w_conv5_1.shape)
b_conv5_1 = tf.Variable(bias_variable([64]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv5_1 = tf.nn.relu(conv2d(norm4, w_conv5_1)+b_conv5_1, name='conv5_1')
w_conv5_2 = tf.Variable(weight_variable([3, 3, 24, 64], 0.1), name='weights', dtype=tf.float32)
b_conv5_2 = tf.Variable(bias_variable([64]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv5_2 = tf.nn.relu(conv2d(norm4, w_conv5_2)+b_conv5_2, name='conv5_2')
w_conv5_3 = tf.Variable(weight_variable([5, 5, 24, 64], 0.1), name='weights', dtype=tf.float32)
b_conv5_3 = tf.Variable(bias_variable([64]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv5_3 = tf.nn.relu(conv2d(norm4, w_conv5_3)+b_conv5_3, name='conv5_3')
w_conv5_4 = tf.Variable(weight_variable([7, 7, 24, 64], 0.1), name='weights', dtype=tf.float32)
b_conv5_4 = tf.Variable(bias_variable([64]), name='biases', dtype=tf.float32) # 16个偏置值
h_conv5_4 = tf.nn.relu(conv2d(norm4, w_conv5_4)+b_conv5_4, name='conv5_3')
h_conv5 = tf.concat((h_conv5_1,h_conv5_2,h_conv5_3,h_conv5_4),axis=3, name='conv5')
with tf.variable_scope('pooling5_lrn') as scope:
pool5 = max_pool_2x2(h_conv5, 'pooling5') # 得到16*16*16
norm5 = tf.nn.lrn(pool5, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm5')
'''
# 第四层全连接层
# 128个神经元,将之前pool层的输出reshape成一行,激活函数relu()
with tf.variable_scope('local3') as scope:
shape = int(np.prod(norm3.get_shape()[1:]))
#reshape = tf.reshape(norm3, shape=[BATCH_SIZE, -1])
pool3_flat = tf.reshape(pool3, [-1, shape])
#dim = reshape.get_shape()[1].value
w_fc1 = tf.Variable(weight_variable([shape, 256], 0.005), name='weights', dtype=tf.float32)
#print(w_fc1," ",pool3_flat.shape)
b_fc1 = tf.Variable(bias_variable([256]), name='biases', dtype=tf.float32)
h_fc1 = tf.nn.relu(tf.matmul(pool3_flat, w_fc1) + b_fc1, name=scope.name)
# 第五层全连接层
# 128个神经元,激活函数relu()
with tf.variable_scope('local4') as scope:
w_fc2 = tf.Variable(weight_variable([256 ,256], 0.005),name='weights', dtype=tf.float32)
b_fc2 = tf.Variable(bias_variable([256]), name='biases', dtype=tf.float32)
h_fc2 = tf.nn.relu(tf.matmul(h_fc1, w_fc2) + b_fc2, name=scope.name)
# Softmax回归层
# 将前面的FC层输出,做一个线性回归,计算出每一类的得分,在这里是6类,所以这个层输出的是六个得分。
with tf.variable_scope('softmax_linear') as scope:
weights = tf.Variable(weight_variable([256, N_CLASSES], 0.005), name='softmax_linear', dtype=tf.float32)
biases = tf.Variable(bias_variable([N_CLASSES]), name='biases', dtype=tf.float32)
#softmax_linear = tf.add(tf.matmul(h_fc2_dropout, weights), biases, name='softmax_linear')#0306
softmax_linear = tf.add(tf.matmul(h_fc2, weights), biases, name='softmax_linear')
# softmax_linear = tf.nn.softmax(tf.add(tf.matmul(h_fc2_dropout, weights), biases, name='softmax_linear'))
#return softmax_linear
# 最后返回softmax层的输出
finaloutput = tf.nn.softmax(softmax_linear, name="softmax")
tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv1)
tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv2)
tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv3)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv4_1)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv4_2)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv4_3)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv5_1)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv5_2)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv5_3)
#tf.add_to_collection(tf.GraphKeys.WEIGHTS, w_conv5_4)
regularizer = tf.contrib.layers.l2_regularizer(scale=5.0/trainnum)
reg_term = tf.contrib.layers.apply_regularization(regularizer)
if is_training==True:
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=finaloutput, labels=tf.cast(Y, tf.float32))+reg_term)
else:
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=finaloutput, labels=tf.cast(Y, tf.float32)))
#cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=finaloutput, labels=Y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=finaloutput, labels=tf.cast(Y, tf.float32)))
optimize = tf.train.AdamOptimizer(lr).minimize(cost)
prediction_labels = tf.argmax(finaloutput, axis=1, name="output")
read_labels = tf.argmax(Y, axis=1)
correct_prediction = tf.equal(prediction_labels, read_labels)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
correct_times_in_batch = tf.reduce_sum(tf.cast(correct_prediction, tf.int32))
return dict(X=X,Y=Y,lr=lr,optimize=optimize,correct_prediction=correct_prediction,
correct_times_in_batch=correct_times_in_batch,cost=cost,accuracy=accuracy)
show_epochs=2
#train_dir =r'D:\wdxrt0305\0331\train'
##train, train_label= get_files_list(train_dir)
#train, train_label,test,test_label = get_file(train_dir)
BATCH_SIZE = 256#32#1024 # 每个batch要放多少张图片
CAPACITY =1024 # 一个队列最大多少
epochs=50#60
iterations=int(np.ceil(len(train_label) /BATCH_SIZE))
MAX_STEP = epochs*iterations
print("训练样本标签数量为:%d 个"%len(train_label))
print("iterations: ",iterations)
print("step: ",MAX_STEP)
num=MAX_STEP
#num=int(np.ceil(MAX_STEP / show_epochs))
fig_accuracy = np.zeros(num)
fig_loss = np.zeros(num)
fig_valaccuracy = np.zeros(num)
fig_valloss = np.zeros(num)
fig_i=0
#lr = 0.0001 # 一般小于0.0001
max_learning_rate = 0.001 #0.0002
min_learning_rate = 0.0000001
#decay_speed = 100.0
train_batch, train_label_batch = get_batch(train, train_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY)
vali_batch, vali_label_batch = get_batch(test, test_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY)
#print(train_batch)
#print(train_label_batch)
keep_prob = tf.placeholder(tf.float32)
is_training = tf.placeholder(tf.bool,name="is_training")
graph = build_network(channel=3,keep_prob=keep_prob,is_training=is_training)
sess = tf.Session()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for epoch in np.arange(epochs):
if coord.should_stop():
break
for step in np.arange(iterations):
learning_rate = max_learning_rate - (max_learning_rate-min_learning_rate) * (fig_i/num)
batch_xs, batch_ys= sess.run([train_batch, train_label_batch])
batch_valxs, batch_valys= sess.run([vali_batch, vali_label_batch])
#learning_rate = min_learning_rate + (max_learning_rate - min_learning_rate) * math.exp(-step/decay_speed)
accuracy,mean_cost_in_batch,return_correct_times_in_batch,_=sess.run([graph['accuracy'],graph['cost'],graph['correct_times_in_batch'],graph['optimize']], feed_dict={
graph['X']: batch_xs,
graph['lr']:learning_rate,
graph['Y']: batch_ys,
keep_prob:0.5,
is_training:True
})
accuracyval,mean_cost_val=sess.run([graph['accuracy'],graph['cost']], feed_dict={
graph['X']: batch_valxs,
graph['lr']:learning_rate,
graph['Y']: batch_valys,
keep_prob:1.0,
is_training:False
})
if step % show_epochs == 0:
print("epoch[%s]".center(50,'-')%epoch)
print("iteration[%s]".center(50,'-')%step)
print("trainloss:{},valloss:{},trainacc:{}, valiacc:{}".format(mean_cost_in_batch,mean_cost_val,accuracy,accuracyval))
#fig_loss.loc[fig_i] = sess.run([graph['cost']], feed_dict={graph['X']: batch_xs,graph['lr']:learning_rate,graph['Y']: batch_ys})
#fig_accuracy.loc[fig_i] =sess.run([graph['accuracy']], feed_dict={graph['X']: batch_xs,graph['lr']:learning_rate,graph['Y']: batch_ys})
fig_loss[fig_i] =mean_cost_in_batch
fig_accuracy[fig_i] =accuracy
fig_valloss[fig_i] =mean_cost_val
fig_valaccuracy[fig_i] =accuracyval
fig_i=fig_i+1
saver.save(sess,r'D:/wdxrt0305/0310/xrtmodel/0401jinxingmodel/model')
# 绘制曲线
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
lns1 = ax1.plot(np.arange(num), fig_loss, label="train Loss")
lns2=ax1.plot(np.arange(num), fig_valloss, 'green',label="vali Loss")
# 按一定间隔显示实现方法#
ax2.plot(np.arange(len(fig_accuracy)), fig_accuracy, 'r')
lns3 = ax2.plot(np.arange(num), fig_accuracy, 'red', label="train Accuracy")
lns4 = ax2.plot(np.arange(num), fig_valaccuracy, 'skyblue', label="vali Accuracy")
ax1.set_xlabel('iteration')
ax1.set_ylabel('loss')
ax2.set_ylabel('accuracy')
# 合并图例
lns = lns1 + lns2+lns3+lns4
labels = ["train Loss", "vali loss","train acc","vali acc"]
# labels = [l.get_label() for l in lns]
plt.legend(lns, labels, loc=7)
plt.show()
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
sess.close()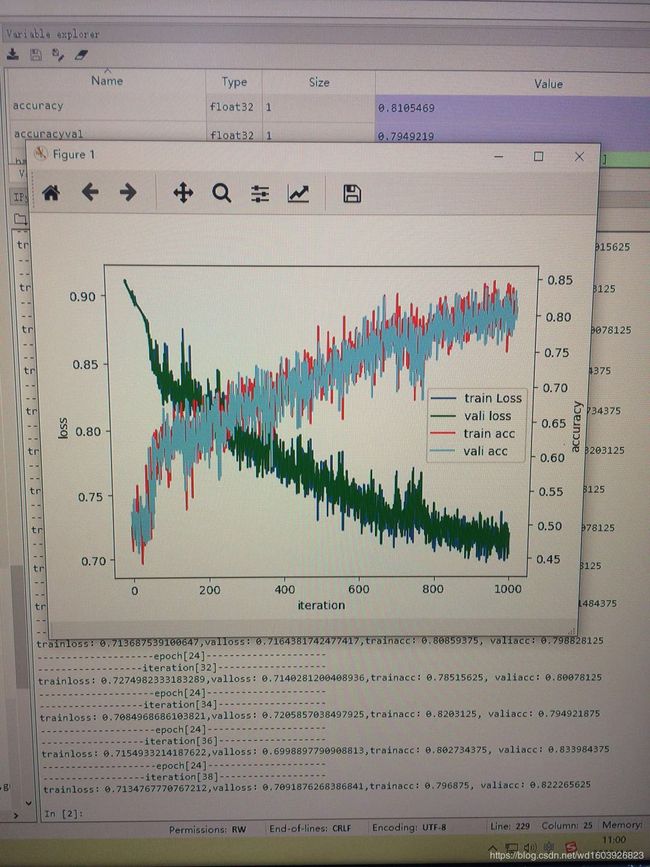 其实依旧还是很贴近,几乎重合,然后测试集上效果不好。为什么呢??
其实依旧还是很贴近,几乎重合,然后测试集上效果不好。为什么呢??
2、VGG19
使用不加BN的VGG19,训练loss一直在0.69,训练acc一直在0.5左右;然后加入BN后虽然loss一开始不是0.69,但很快收敛到0.69左右,这不对!
import tensorflow as tf
def bn(x, is_training):
return tf.layers.batch_normalization(x, training=is_training)
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding="SAME"):
return tf.nn.max_pool(x, ksize=[1, kHeight, kWidth, 1],
strides=[1, strideX, strideY, 1], padding=padding, name=name)
def dropout(x, keepPro, name=None):
return tf.nn.dropout(x, keepPro, name)
def fcLayer(x, inputD, outputD, reluFlag, name):
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape=[inputD, outputD], dtype="float")
b = tf.get_variable("b", [outputD], dtype="float")
out = tf.nn.xw_plus_b(x, w, b, name=scope.name)
if reluFlag:
return tf.nn.relu(out)
else:
return out
def convLayer(x, kHeight, kWidth, strideX, strideY, featureNum, name, padding = "SAME"):
channel = int(x.get_shape()[-1])
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape=[kHeight, kWidth, channel, featureNum])
b = tf.get_variable("b", shape=[featureNum])
featureMap = tf.nn.conv2d(x, w, strides=[1, strideY, strideX, 1], padding=padding)
out = tf.nn.bias_add(featureMap, b)
return tf.nn.relu(tf.reshape(out, featureMap.get_shape().as_list()), name=scope.name)
class VGG19(object):
def __init__(self, x, keepPro, classNum, is_training):
self.X = x
self.KEEPPRO = keepPro
self.CLASSNUM = classNum
self.is_training = is_training
self.begin_VGG_19()
def begin_VGG_19(self):
"""build model"""
conv1_1 = convLayer(self.X, 3, 3, 1, 1, 64, "conv1_1" )
conv1_1 = bn(conv1_1, self.is_training)
conv1_2 = convLayer(conv1_1, 3, 3, 1, 1, 64, "conv1_2")
conv1_2 = bn(conv1_2, self.is_training)
pool1 = maxPoolLayer(conv1_2, 2, 2, 2, 2, "pool1")
conv2_1 = convLayer(pool1, 3, 3, 1, 1, 128, "conv2_1")
conv2_1 = bn(conv2_1, self.is_training)
conv2_2 = convLayer(conv2_1, 3, 3, 1, 1, 128, "conv2_2")
conv2_2 = bn(conv2_2, self.is_training)
pool2 = maxPoolLayer(conv2_2, 2, 2, 2, 2, "pool2")
conv3_1 = convLayer(pool2, 3, 3, 1, 1, 256, "conv3_1")
conv3_1 = bn(conv3_1, self.is_training)
conv3_2 = convLayer(conv3_1, 3, 3, 1, 1, 256, "conv3_2")
conv3_2 = bn(conv3_2, self.is_training)
conv3_3 = convLayer(conv3_2, 3, 3, 1, 1, 256, "conv3_3")
conv3_3 = bn(conv3_3, self.is_training)
conv3_4 = convLayer(conv3_3, 3, 3, 1, 1, 256, "conv3_4")
conv3_4 = bn(conv3_4, self.is_training)
pool3 = maxPoolLayer(conv3_4, 2, 2, 2, 2, "pool3")
conv4_1 = convLayer(pool3, 3, 3, 1, 1, 512, "conv4_1")
conv4_1 = bn(conv4_1, self.is_training)
conv4_2 = convLayer(conv4_1, 3, 3, 1, 1, 512, "conv4_2")
conv4_2 = bn(conv4_2, self.is_training)
conv4_3 = convLayer(conv4_2, 3, 3, 1, 1, 512, "conv4_3")
conv4_3 = bn(conv4_3, self.is_training)
conv4_4 = convLayer(conv4_3, 3, 3, 1, 1, 512, "conv4_4")
conv4_4 = bn(conv4_4, self.is_training)
pool4 = maxPoolLayer(conv4_4, 2, 2, 2, 2, "pool4")
conv5_1 = convLayer(pool4, 3, 3, 1, 1, 512, "conv5_1")
conv5_1 = bn(conv5_1, self.is_training)
conv5_2 = convLayer(conv5_1, 3, 3, 1, 1, 512, "conv5_2")
conv5_2 = bn(conv5_2, self.is_training)
conv5_3 = convLayer(conv5_2, 3, 3, 1, 1, 512, "conv5_3")
conv5_3 = bn(conv5_3, self.is_training)
conv5_4 = convLayer(conv5_3, 3, 3, 1, 1, 512, "conv5_4")
conv5_4 = bn(conv5_4, self.is_training)
pool5 = maxPoolLayer(conv5_4, 2, 2, 2, 2, "pool5")
print('最后一层卷积层的形状是:', pool5.shape)
fcIn = tf.reshape(pool5, [-1, 4*4*512])
fc6 = fcLayer(fcIn, 4*4*512, 4096, True, "fc6")
dropout1 = dropout(fc6, self.KEEPPRO)
fc7 = fcLayer(dropout1, 4096, 4096, True, "fc7")
dropout2 = dropout(fc7, self.KEEPPRO)
self.fc8 = fcLayer(dropout2, 4096, self.CLASSNUM, True, "fc8")
#https://blog.csdn.net/qq_41776781/article/details/94452085import numpy as np
import tensorflow as tf
from vgg19 import VGG19
from datageneratorright import ImageDataGenerator
#from datetime import datetime
import glob
from tensorflow.data import Iterator
import matplotlib.pyplot as plt
# 初始参数设置
img_size=64
learning_rate = 1e-4
num_epochs = 7 # 代的个数 之前是10
train_batch_size = 200 # 之前是1024
#test_batch_size = 100
dropout_rate = 0.5
num_classes = 2 # 类别标签
display_step = 2 # display_step个train_batch_size训练完了就在tensorboard中写入loss和accuracy
# need: display_step <= train_dataset_size / train_batch_size
'''
filewriter_path = "./tmp/tensorboard" # 存储tensorboard文件
checkpoint_path = "./tmp/checkpoints" # 训练好的模型和参数存放目录
'''
image_format = 'png' # 数据集的数据类型
file_name_of_class = ['fei','kuang'] # fei对应标签0,kuang对应标签1。默认图片包含独特的名词,比如类别
train_dataset_paths = ['D:/wdxrt0305/0310/images/0325/train/fei/','D:/wdxrt0305/0310/images/0325/train/kuang/'] # 指定训练集数据路径(根据实际情况指定训练数据集的路径)
#test_dataset_paths = ['G:/Lab/Data_sets/catanddog/test/cat/',
# 'G:/Lab/Data_sets/catanddog/test/dog/'] # 指定测试集数据路径(根据实际情况指定测试数据集的路径)
# 注意:默认数据集中的样本文件名称中包含其所属类别标签的名称,即file_name_of_class中的名称
# 初始参数设置完毕
# 训练数据集数据处理
train_image_paths = []
train_labels = []
# 打开训练数据集目录,读取全部图片,生成图片路径列表
for train_dataset_path in train_dataset_paths:
length = len(train_image_paths)
train_image_paths[length:length] = np.array(glob.glob(train_dataset_path + '*.' + image_format)).tolist()
for image_path in train_image_paths:
image_file_name = image_path.split('/')[-1]
for i in range(num_classes):
if file_name_of_class[i] in image_file_name:
train_labels.append(i)
break
# get Datasets
# 调用图片生成器,把训练集图片转换成三维数组
train_data = ImageDataGenerator(
images=train_image_paths,
labels=train_labels,
batch_size=train_batch_size,
num_classes=num_classes,
image_format=image_format,
shuffle=True)
# get Iterators
with tf.name_scope('input'):
# 定义迭代器
train_iterator = Iterator.from_structure(train_data.data.output_types,
train_data.data.output_shapes)
training_initalizer=train_iterator.make_initializer(train_data.data)
#test_iterator = Iterator.from_structure(test_data.data.output_types,test_data.data.output_shapes)
#testing_initalizer=test_iterator.make_initializer(test_data.data)
# 定义每次迭代的数据
train_next_batch = train_iterator.get_next()
#test_next_batch = test_iterator.get_next()
x = tf.placeholder(tf.float32, [None, img_size, img_size, 3])
y = tf.placeholder(tf.float32, [None, num_classes])
#keep_prob = tf.placeholder(tf.float32)
# Vgg19
model = VGG19(bgr_image=x, num_class=num_classes)
score = model.fc8
train_layer = ['fc8', 'fc7', 'fc6']
# List of trainable variables of the layers we want to train
var_list = [v for v in tf.trainable_variables() if v.name.split('/')[0] in train_layer]
with tf.name_scope('loss'):
#loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=score, labels=y))
loss_op = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=score, labels=tf.cast(y, tf.float32)))
gradients = tf.gradients(loss_op, var_list)
gradients = list(zip(gradients, var_list))
with tf.name_scope('optimizer'):
# 优化器,采用梯度下降算法进行优化
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.apply_gradients(grads_and_vars=gradients)
with tf.name_scope("accuracy"):
# 定义网络精确度
correct_pred = tf.equal(tf.argmax(score, 1), tf.argmax(y, 1))
accuracy = tf.cast(correct_pred, tf.float32)
# 把精确度加入到TensorBoard
#tf.summary.scalar('loss', loss)
init = tf.global_variables_initializer()
'''
# Tensorboard
tf.summary.scalar('loss', loss_op)
tf.summary.scalar('accuracy', accuracy)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(filewriter_path)
'''
#开启GPU运算
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
# 定义一代的迭代次数
train_batches_per_epoch = int(np.floor(train_data.data_size / train_batch_size))
#test_batches_per_epoch = int(np.floor(test_data.data_size / test_batch_size))
allnum=int(np.floor(train_batches_per_epoch*num_epochs))
fig_accuracy = np.zeros(allnum)
fig_loss = np.zeros(allnum)
fig_i=0
sess = tf.Session(config=config)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for epoch in np.arange(num_epochs):
if coord.should_stop():
break
sess.run(training_initalizer)
print("Epoch number: {} start...".format(epoch + 1))
# train
for step in range(train_batches_per_epoch):
img_batch, label_batch = sess.run(train_next_batch)
#print(img_batch.shape,'\n',label_batch.shape)
loss,_ = sess.run([loss_op,train_op], feed_dict={x: img_batch,y: label_batch})
softmax_prediction = sess.run(score, feed_dict={x: img_batch,y: label_batch})
prediction_label = sess.run(tf.argmax(softmax_prediction, 1))
actual_label = sess.run(tf.argmax(label_batch, 1))
rightlabel=0
for i in range(len(prediction_label)):
if prediction_label[i] == actual_label[i]:
rightlabel += 1
precision = rightlabel /train_batch_size
if step % display_step == 0:
print("index[%s]".center(50,'-')%step)
print("Train: loss:{},accuracy:{}".format(loss,precision))
saver.save(sess,r'D:/wdxrt0305/0310/xrtmodel/0327jinxingmodel/model')
fig_loss[fig_i] =loss
fig_accuracy[fig_i] =precision
fig_i=fig_i+1
# 绘制曲线
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
lns1 = ax1.plot(np.arange(allnum), fig_loss, label="Loss")
# 按一定间隔显示实现方法#
ax2.plot(np.arange(len(fig_accuracy)), fig_accuracy, 'r')
lns2 = ax2.plot(np.arange(allnum), fig_accuracy, 'r', label="Accuracy")
ax1.set_xlabel('iteration')
ax1.set_ylabel('training loss')
ax2.set_ylabel('training accuracy')
# 合并图例
lns = lns1 + lns2
labels = ["Loss", "Accuracy"]
# labels = [l.get_label() for l in lns]
plt.legend(lns, labels, loc=7)
plt.show()
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
sess.close()曲线图:
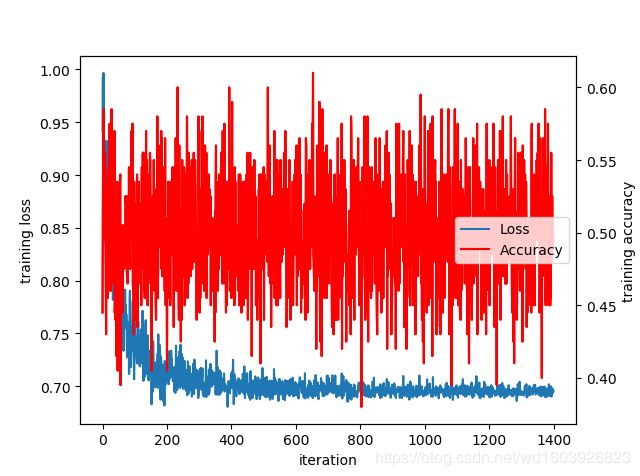
这不正确!网络完全没有学习能力?!

 认真的小布丁和认真打游戏的对象
认真的小布丁和认真打游戏的对象