1.kube-scheduler在集群中的作用
kube-scheduler是以插件形式存在的组件,正因为以插件形式存在,所以其具有可扩展可定制的特性。kube-scheduler相当于整个集群的调度决策者,其通过预选和优选两个过程决定容器的最佳调度位置。
3.kube-scheduler源码中的关键性调用链
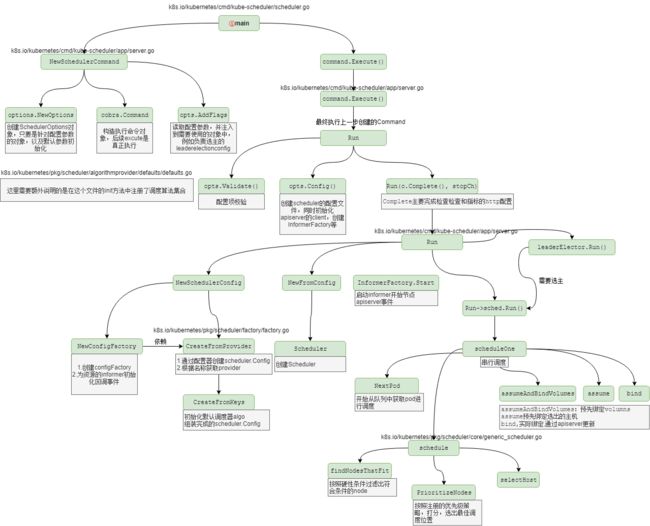
4.具体的源码分析过程
4.1.组件启动入口
位置: k8s.io/kubernetes/cmd/kube-scheduler/scheduler.go
func main() {
rand.Seed(time.Now().UTC().UnixNano())
command := app.NewSchedulerCommand()
// TODO: once we switch everything over to Cobra commands, we can go back to calling
// utilflag.InitFlags() (by removing its pflag.Parse() call). For now, we have to set the
// normalize func and add the go flag set by hand.
pflag.CommandLine.SetNormalizeFunc(utilflag.WordSepNormalizeFunc)
pflag.CommandLine.AddGoFlagSet(goflag.CommandLine)
// utilflag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
这里需要特别说明的是调度策略的注册过程,在default.go的init中对默认的Predicate、AlgorithmProvider以及Priority的策略进行注册。同时指明了默认的调度算法DefaultProvider
位置:k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go
func init() {
// Register functions that extract metadata used by predicates and priorities computations.
factory.RegisterPredicateMetadataProducerFactory(
func(args factory.PluginFactoryArgs) algorithm.PredicateMetadataProducer {
return predicates.NewPredicateMetadataFactory(args.PodLister)
})
···
registerAlgorithmProvider(defaultPredicates(), defaultPriorities())
factory.RegisterFitPredicate("PodFitsPorts", predicates.PodFitsHostPorts)
// Fit is defined based on the absence of port conflicts.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
factory.RegisterFitPredicate(predicates.PodFitsHostPortsPred, predicates.PodFitsHostPorts)
// Fit is determined by resource availability.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
factory.RegisterFitPredicate(predicates.PodFitsResourcesPred, predicates.PodFitsResources)
// Fit is determined by the presence of the Host parameter and a string match
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
factory.RegisterFitPredicate(predicates.HostNamePred, predicates.PodFitsHost)
// Fit is determined by node selector query.
factory.RegisterFitPredicate(predicates.MatchNodeSelectorPred, predicates.PodMatchNodeSelector)
···
}
···
func registerAlgorithmProvider(predSet, priSet sets.String) {
//这里指明了默认的调度算法DefaultProvider
// Registers algorithm providers. By default we use 'DefaultProvider', but user can specify one to be used
// by specifying flag.
factory.RegisterAlgorithmProvider(factory.DefaultProvider, predSet, priSet)
// Cluster autoscaler friendly scheduling algorithm.
factory.RegisterAlgorithmProvider(ClusterAutoscalerProvider, predSet,
copyAndReplace(priSet, "LeastRequestedPriority", "MostRequestedPriority"))
}
下面回到从组件入口
4.2.读取配置文件,进行配置读取和初始化默认配置
位置:k8s.io/kubernetes/cmd/kube-scheduler/app/server.go
- 创建SchedulerOptions对象,只要是针对配置参数的对象,以及默认参数初始化NewOptions
- 构造执行命令对象,后续excute是真正执行cobra.Command
- 读取配置参数,并注入到需要使用的对象中,opts.AddFlags。例如负责选主的leaderelectionconfig
func NewSchedulerCommand() *cobra.Command {
opts, err := options.NewOptions()
if err != nil {
glog.Fatalf("unable to initialize command options: %v", err)
}
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `The Kubernetes ······`,
Run: func(cmd *cobra.Command, args []string) {
verflag.PrintAndExitIfRequested()
utilflag.PrintFlags(cmd.Flags())
if len(args) != 0 {
fmt.Fprint(os.Stderr, "arguments are not supported\n")
}
if errs := opts.Validate(); len(errs) > 0 {
fmt.Fprintf(os.Stderr, "%v\n", utilerrors.NewAggregate(errs))
os.Exit(1)
}
if len(opts.WriteConfigTo) > 0 {
if err := options.WriteConfigFile(opts.WriteConfigTo, &opts.ComponentConfig); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
glog.Infof("Wrote configuration to: %s\n", opts.WriteConfigTo)
return
}
c, err := opts.Config()
if err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
stopCh := make(chan struct{})
if err := Run(c.Complete(), stopCh); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
}
opts.AddFlags(cmd.Flags())
cmd.MarkFlagFilename("config", "yaml", "yml", "json")
return cmd
}
4.3.组件启动执行
本质上执行上一步的&cobra.Command
if err := command.Execute(); err != nil {
位置:k8s.io/kubernetes/cmd/kube-scheduler/app/server.go
- 设置调度算法的一些特性
- 初始化schedulerConfig
- 创建Scheduler对象
- 根据是否安全提供健康检查和指标服务
- 启动和资源相关的informer
- 根据需要进行选主,然后执行调度任务
重点关注NewSchedulerConfig 和 sched.Run()
func Run(c schedulerserverconfig.CompletedConfig, stopCh <-chan struct{}) error {
// To help debugging, immediately log version
glog.Infof("Version: %+v", version.Get())
// Apply algorithms based on feature gates.
// TODO: make configurable?
algorithmprovider.ApplyFeatureGates()
// Configz registration.
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(c.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// Build a scheduler config from the provided algorithm source.
schedulerConfig, err := NewSchedulerConfig(c)
if err != nil {
return err
}
// Create the scheduler.
sched := scheduler.NewFromConfig(schedulerConfig)
// Prepare the event broadcaster.
if c.Broadcaster != nil && c.EventClient != nil {
c.Broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: c.EventClient.Events("")})
}
// Start up the healthz server.
if c.InsecureServing != nil {
separateMetrics := c.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&c.ComponentConfig, separateMetrics), nil, nil)
if err := c.InsecureServing.Serve(handler, 0, stopCh); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
if c.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&c.ComponentConfig), nil, nil)
if err := c.InsecureMetricsServing.Serve(handler, 0, stopCh); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
if c.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&c.ComponentConfig, false), c.Authentication.Authenticator, c.Authorization.Authorizer)
if err := c.SecureServing.Serve(handler, 0, stopCh); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
// Start all informers.
go c.PodInformer.Informer().Run(stopCh)
c.InformerFactory.Start(stopCh)
// Wait for all caches to sync before scheduling.
c.InformerFactory.WaitForCacheSync(stopCh)
controller.WaitForCacheSync("scheduler", stopCh, c.PodInformer.Informer().HasSynced)
// Prepare a reusable run function.
run := func(stopCh <-chan struct{}) {
sched.Run()
<-stopCh
}
// If leader election is enabled, run via LeaderElector until done and exit.
if c.LeaderElection != nil {
c.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: run,
OnStoppedLeading: func() {
utilruntime.HandleError(fmt.Errorf("lost master"))
},
}
leaderElector, err := leaderelection.NewLeaderElector(*c.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run()
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so run inline until done.
run(stopCh)
return fmt.Errorf("finished without leader elect")
}
转到NewSchedulerConfig
位置:k8s.io/kubernetes/cmd/kube-scheduler/app/server.go
- 创建配置管理器,内部包含各类资源的Informer
- 根据算法名称,通过配置器创建scheduler.Config,加载相关策略
重点关注NewConfigFactory ,CreateFromProvider,selectHost
// NewSchedulerConfig creates the scheduler configuration. This is exposed for use by tests.
func NewSchedulerConfig(s schedulerserverconfig.CompletedConfig) (*scheduler.Config, error) {
var storageClassInformer storageinformers.StorageClassInformer
if utilfeature.DefaultFeatureGate.Enabled(features.VolumeScheduling) {
storageClassInformer = s.InformerFactory.Storage().V1().StorageClasses()
}
// Set up the configurator which can create schedulers from configs.
configurator := factory.NewConfigFactory(
s.ComponentConfig.SchedulerName,
s.Client,
s.InformerFactory.Core().V1().Nodes(),
s.PodInformer,
s.InformerFactory.Core().V1().PersistentVolumes(),
s.InformerFactory.Core().V1().PersistentVolumeClaims(),
s.InformerFactory.Core().V1().ReplicationControllers(),
s.InformerFactory.Extensions().V1beta1().ReplicaSets(),
s.InformerFactory.Apps().V1beta1().StatefulSets(),
s.InformerFactory.Core().V1().Services(),
s.InformerFactory.Policy().V1beta1().PodDisruptionBudgets(),
storageClassInformer,
s.ComponentConfig.HardPodAffinitySymmetricWeight,
utilfeature.DefaultFeatureGate.Enabled(features.EnableEquivalenceClassCache),
s.ComponentConfig.DisablePreemption,
)
source := s.ComponentConfig.AlgorithmSource
var config *scheduler.Config
switch {
case source.Provider != nil:
// Create the config from a named algorithm provider.
sc, err := configurator.CreateFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
config = sc
case source.Policy != nil:
// Create the config from a user specified policy source.
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
// Use a policy serialized in a file.
policyFile := source.Policy.File.Path
_, err := os.Stat(policyFile)
if err != nil {
return nil, fmt.Errorf("missing policy config file %s", policyFile)
}
data, err := ioutil.ReadFile(policyFile)
if err != nil {
return nil, fmt.Errorf("couldn't read policy config: %v", err)
}
err = runtime.DecodeInto(latestschedulerapi.Codec, []byte(data), policy)
if err != nil {
return nil, fmt.Errorf("invalid policy: %v", err)
}
case source.Policy.ConfigMap != nil:
// Use a policy serialized in a config map value.
policyRef := source.Policy.ConfigMap
policyConfigMap, err := s.Client.CoreV1().ConfigMaps(policyRef.Namespace).Get(policyRef.Name, metav1.GetOptions{})
if err != nil {
return nil, fmt.Errorf("couldn't get policy config map %s/%s: %v", policyRef.Namespace, policyRef.Name, err)
}
data, found := policyConfigMap.Data[componentconfig.SchedulerPolicyConfigMapKey]
if !found {
return nil, fmt.Errorf("missing policy config map value at key %q", componentconfig.SchedulerPolicyConfigMapKey)
}
err = runtime.DecodeInto(latestschedulerapi.Codec, []byte(data), policy)
if err != nil {
return nil, fmt.Errorf("invalid policy: %v", err)
}
}
sc, err := configurator.CreateFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
config = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
config.Recorder = s.Recorder
config.DisablePreemption = s.ComponentConfig.DisablePreemption
return config, nil
}
转到NewConfigFactory
位置:k8s.io/kubernetes/pkg/scheduler/factory/factory.go
- 为Informer初始化事件监听的回调函数
func NewConfigFactory(
schedulerName string,
client clientset.Interface,
nodeInformer coreinformers.NodeInformer,
podInformer coreinformers.PodInformer,
pvInformer coreinformers.PersistentVolumeInformer,
pvcInformer coreinformers.PersistentVolumeClaimInformer,
replicationControllerInformer coreinformers.ReplicationControllerInformer,
replicaSetInformer extensionsinformers.ReplicaSetInformer,
statefulSetInformer appsinformers.StatefulSetInformer,
serviceInformer coreinformers.ServiceInformer,
pdbInformer policyinformers.PodDisruptionBudgetInformer,
storageClassInformer storageinformers.StorageClassInformer,
hardPodAffinitySymmetricWeight int32,
enableEquivalenceClassCache bool,
disablePreemption bool,
) scheduler.Configurator {
stopEverything := make(chan struct{})
schedulerCache := schedulercache.New(30*time.Second, stopEverything)
// storageClassInformer is only enabled through VolumeScheduling feature gate
var storageClassLister storagelisters.StorageClassLister
if storageClassInformer != nil {
storageClassLister = storageClassInformer.Lister()
}
c := &configFactory{
client: client,
podLister: schedulerCache,
podQueue: core.NewSchedulingQueue(),
pVLister: pvInformer.Lister(),
pVCLister: pvcInformer.Lister(),
serviceLister: serviceInformer.Lister(),
controllerLister: replicationControllerInformer.Lister(),
replicaSetLister: replicaSetInformer.Lister(),
statefulSetLister: statefulSetInformer.Lister(),
pdbLister: pdbInformer.Lister(),
storageClassLister: storageClassLister,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
schedulerName: schedulerName,
hardPodAffinitySymmetricWeight: hardPodAffinitySymmetricWeight,
enableEquivalenceClassCache: enableEquivalenceClassCache,
disablePreemption: disablePreemption,
}
c.scheduledPodsHasSynced = podInformer.Informer().HasSynced
// scheduled pod cache
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedNonTerminatedPod(t)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return assignedNonTerminatedPod(pod)
}
runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c))
return false
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
},
)
···
}
转到CreateFromProvider
位置:k8s.io/kubernetes/pkg/scheduler/factory/factory.go
- 根据名称获取调度算法
func (c *configFactory) CreateFromProvider(providerName string) (*scheduler.Config, error) {
glog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
//provider = algorithmProviderMap[name]
//
provider, err := GetAlgorithmProvider(providerName)
if err != nil {
return nil, err
}
return c.CreateFromKeys(provider.FitPredicateKeys, provider.PriorityFunctionKeys, []algorithm.SchedulerExtender{})
}
转到CreateFromKeys
位置:k8s.io/kubernetes/pkg/scheduler/factory/factory.go
- 根据调度算法和策略实例化调度器
//Creates a scheduler from a set of registered fit predicate keys and priority keys.
func (c *configFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender) (*scheduler.Config, error) {
···
//默认调度器
algo := core.NewGenericScheduler(
c.schedulerCache,
c.equivalencePodCache,
c.podQueue,
predicateFuncs,
predicateMetaProducer,
priorityConfigs,
priorityMetaProducer,
extenders,
c.volumeBinder,
c.pVCLister,
c.alwaysCheckAllPredicates,
c.disablePreemption,
)
···
}
回到sched.Run() 真正开始执行调度任务
位置:k8s.io/kubernetes/cmd/kube-scheduler/scheduler.go
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
if utilfeature.DefaultFeatureGate.Enabled(features.VolumeScheduling) {
go sched.config.VolumeBinder.Run(sched.bindVolumesWorker, sched.config.StopEverything)
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
转到scheduleOne 串行调度pod
位置:k8s.io/kubernetes/cmd/kube-scheduler/scheduler.go
- 从队列中获取pod ,为pod选择合适的调度位置
- 在缓存中预先绑定Volume资源,
- 在缓存中预先绑定主机,主要愿意是真正绑定是调用apiserver是会有延迟,会晚于下一次调度
- 通过APIserver的client实现真正绑定
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
//从podQueue中获取新后者更新的pod
pod := sched.config.NextPod()
if pod.DeletionTimestamp != nil {
sched.config.Recorder.Eventf(pod, v1.EventTypeWarning, "FailedScheduling", "skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
glog.V(3).Infof("Skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
return
}
glog.V(3).Infof("Attempting to schedule pod: %v/%v", pod.Namespace, pod.Name)
// Synchronously attempt to find a fit for the pod.
start := time.Now()
suggestedHost, err := sched.schedule(pod)
if err != nil {
// schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
if fitError, ok := err.(*core.FitError); ok {
preemptionStartTime := time.Now()
sched.preempt(pod, fitError)
metrics.PreemptionAttempts.Inc()
metrics.SchedulingAlgorithmPremptionEvaluationDuration.Observe(metrics.SinceInMicroseconds(preemptionStartTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PreemptionEvaluation).Observe(metrics.SinceInSeconds(preemptionStartTime))
}
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInMicroseconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPod := pod.DeepCopy()
···
err = sched.assumeAndBindVolumes(assumedPod, suggestedHost)
if err != nil {
return
}
// assume modifies `assumedPod` by setting NodeName=suggestedHost
err = sched.assume(assumedPod, suggestedHost)
if err != nil {
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: suggestedHost,
},
})
metrics.E2eSchedulingLatency.Observe(metrics.SinceInMicroseconds(start))
if err != nil {
glog.Errorf("Internal error binding pod: (%v)", err)
}
}()
}
转到schedule
位置:k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go
- 获取当前的节点信息,并更新到本地缓存中
- 找到符合条件的节点:findNodesThatFit
- 根据策略和权重并行给满足条件的节点进行打分:PrioritizeNodes
- 根据优先级(得分)筛选出最佳的调度位置
重点关注findNodesThatFit和PrioritizeNodes
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (string, error) {
trace := utiltrace.New(fmt.Sprintf("Scheduling %s/%s", pod.Namespace, pod.Name))
defer trace.LogIfLong(100 * time.Millisecond)
if err := podPassesBasicChecks(pod, g.pvcLister); err != nil {
return "", err
}
nodes, err := nodeLister.List()
if err != nil {
return "", err
}
if len(nodes) == 0 {
return "", ErrNoNodesAvailable
}
// Used for all fit and priority funcs.
//每次调度更新新的node
err = g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
if err != nil {
return "", err
}
trace.Step("Computing predicates")
startPredicateEvalTime := time.Now()
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
if err != nil {
return "", err
}
if len(filteredNodes) == 0 {
return "", &FitError{
Pod: pod,
NumAllNodes: len(nodes),
FailedPredicates: failedPredicateMap,
}
}
metrics.SchedulingAlgorithmPredicateEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPredicateEvalTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PredicateEvaluation).Observe(metrics.SinceInSeconds(startPredicateEvalTime))
trace.Step("Prioritizing")
startPriorityEvalTime := time.Now()
// When only one node after predicate, just use it.
if len(filteredNodes) == 1 {
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
return filteredNodes[0].Name, nil
}
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.cachedNodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return "", err
}
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PriorityEvaluation).Observe(metrics.SinceInSeconds(startPriorityEvalTime))
trace.Step("Selecting host")
return g.selectHost(priorityList)
}
转到findNodesThatFit
位置:k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go
找到满足硬性条件的节点,例如资源,亲和性,反亲和性等
重点关注podFitsOnNode:
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {
···
checkNode := func(i int) {
nodeName := nodes[i].Name
fits, failedPredicates, err := podFitsOnNode(
pod,
meta,
g.cachedNodeInfoMap[nodeName],
g.predicates,
g.cache,
g.equivalenceCache,
g.schedulingQueue,
g.alwaysCheckAllPredicates,
equivCacheInfo,
)
if err != nil {
predicateResultLock.Lock()
errs[err.Error()]++
predicateResultLock.Unlock()
return
}
if fits {
filtered[atomic.AddInt32(&filteredLen, 1)-1] = nodes[i]
} else {
predicateResultLock.Lock()
failedPredicateMap[nodeName] = failedPredicates
predicateResultLock.Unlock()
}
}
workqueue.Parallelize(16, len(nodes), checkNode)
···
}
转到podFitsOnNode
位置:k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go
在同一个case中,运行两次谓词。
如果node中已经有优先级大于或者等于的提名的pod,那么当这些pod将被添加到源数据和节点信息中时将被启动
如果所有的谓词都通过,那么当这些被提名的pod没有被添加时候,也会运行
第二次是必须要通过的,因为有些谓词没有通过是不能够被提名的,例如节点的亲和性
如果节点上没有被提名的pod,或者第一次运行的谓词失败,将不再运行第二次
我们只考虑在第一次通过的同等或者更高优先级的pod,因为那些当前的"pod"必须给他们让步,并且不能为了运行它们,占用一个打开的空间
如果当前的pod释放资源给低优先级的pod是OK的
在两种情况下pod是可调度的:
当被提名的pod被视为运行时,资源相关的谓词和pod间的反亲和性往往更容易失败,
而当指定的pod被视为不运行时,pod亲和性相关的谓词更有可能失败。
我们不能只假设被提名的pod都是运行的,因为他们不是马上运行,符合条件的node可能不止一个,它们最终可能会被调度到不同的节点
func podFitsOnNode(
pod *v1.Pod,
meta algorithm.PredicateMetadata,
info *schedulercache.NodeInfo,
predicateFuncs map[string]algorithm.FitPredicate,
cache schedulercache.Cache,
ecache *EquivalenceCache,
queue SchedulingQueue,
alwaysCheckAllPredicates bool,
equivCacheInfo *equivalenceClassInfo,
) (bool, []algorithm.PredicateFailureReason, error) {
···
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
if i == 0 {
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(util.GetPodPriority(pod), meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
eCacheAvailable = equivCacheInfo != nil && !podsAdded
for _, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []algorithm.PredicateFailureReason
err error
)
//TODO (yastij) : compute average predicate restrictiveness to export it as Prometheus metric
if predicate, exist := predicateFuncs[predicateKey]; exist {
if eCacheAvailable {
fit, reasons, err = ecache.RunPredicate(predicate, predicateKey, pod, metaToUse, nodeInfoToUse, equivCacheInfo, cache)
} else {
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
}
if err != nil {
return false, []algorithm.PredicateFailureReason{}, err
}
if !fit {
// eCache is available and valid, and predicates result is unfit, record the fail reasons
failedPredicates = append(failedPredicates, reasons...)
// if alwaysCheckAllPredicates is false, short circuit all predicates when one predicate fails.
if !alwaysCheckAllPredicates {
glog.V(5).Infoln("since alwaysCheckAllPredicates has not been set, the predicate" +
"evaluation is short circuited and there are chances" +
"of other predicates failing as well.")
break
}
}
}
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}
回到PrioritizeNodes
位置:k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go
- 如果之前没有注册优先级配置,直接返回空的优先级列表,如果有优先级配置,那么按照node维初始化每个node的得分1
- 计算每个优先级策略在每个node上的得分
- 将每个node上的得分进行汇总(当然这里还需要乘以每个分值所占的权重)
- 得到每个node上的总分列表
func PrioritizeNodes(
pod *v1.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
meta interface{},
priorityConfigs []algorithm.PriorityConfig,
nodes []*v1.Node,
extenders []algorithm.SchedulerExtender,
) (schedulerapi.HostPriorityList, error) {
// If no priority configs are provided, then the EqualPriority function is applied
// This is required to generate the priority list in the required format
if len(priorityConfigs) == 0 && len(extenders) == 0 {
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
hostPriority, err := EqualPriorityMap(pod, meta, nodeNameToInfo[nodes[i].Name])
if err != nil {
return nil, err
}
result = append(result, hostPriority)
}
return result, nil
}
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
appendError := func(err error) {
mu.Lock()
defer mu.Unlock()
errs = append(errs, err)
}
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Function != nil {
// DEPRECATED
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
var err error
results[index], err = config.Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i, priorityConfig)
} else {
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
}
}
processNode := func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
var err error
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
return
}
}
}
//开启小于等于16个协程处理
workqueue.Parallelize(16, len(nodes), processNode)
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Reduce == nil {
continue
}
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
if err := config.Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if glog.V(10) {
for _, hostPriority := range results[index] {
glog.Infof("%v -> %v: %v, Score: (%d)", pod.Name, hostPriority.Host, config.Name, hostPriority.Score)
}
}
}(i, priorityConfig)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
if len(extenders) != 0 && nodes != nil {
combinedScores := make(map[string]int, len(nodeNameToInfo))
for _, extender := range extenders {
if !extender.IsInterested(pod) {
continue
}
wg.Add(1)
go func(ext algorithm.SchedulerExtender) {
defer wg.Done()
prioritizedList, weight, err := ext.Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
combinedScores[host] += score * weight
}
mu.Unlock()
}(extender)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
result[i].Score += combinedScores[result[i].Host]
}
}
if glog.V(10) {
for i := range result {
glog.V(10).Infof("Host %s => Score %d", result[i].Host, result[i].Score)
}
}
return result, nil
}
回到selectHost
位置:k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go
- 按照分值排序后返回最佳的主机
// selectHost takes a prioritized list of nodes and then picks one
// in a round-robin manner from the nodes that had the highest score.
func (g *genericScheduler) selectHost(priorityList schedulerapi.HostPriorityList) (string, error) {
if len(priorityList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
sort.Sort(sort.Reverse(priorityList))
//找到分数排名第二的分值的位置,实际上firstAfterMaxScore只为1
// 如果找到返回排序后的至二个索引,即为1,找不到返回长度,只有此种情况返回着不为1
maxScore := priorityList[0].Score
firstAfterMaxScore := sort.Search(len(priorityList), func(i int) bool { return priorityList[i].Score < maxScore })
g.lastNodeIndexLock.Lock()
ix := int(g.lastNodeIndex % uint64(firstAfterMaxScore))
g.lastNodeIndex++
g.lastNodeIndexLock.Unlock()
return priorityList[ix].Host, nil
}