网格计算, 云计算, 集群计算, 分布式计算, 超级计算
整体来说都有将任务分割、运算、组合,只是协同和处理的重点不同;
超级计算强调的是高并行计算能力,应用设备多是超级计算机如天河一号,是infiniband的高并行处理架构,实现总线级协同,一般采用计算能力更强的GPU而非CPU;
集群计算和分布式计算是相对于设备部署结构来说,这种计算相对超算来说,对于计算的并行处理及响应要求较低,需要实现的是网络环境下的协同,实现的效果受网络环境影响。
网格计算是集群计算和分布式计算与超级计算中间的产物,是在原来集群计算和分布式计算不能满足需求,而超算又过于难以实现的情况下,想通过增进网络带宽方式来实现通过集群计算和分布式计算能够达到接近超级计算的结果,国家网格节点之间的带宽都是T级别的,就可想而知对于基础资源的需求。
而云计算是更接近应用的资源整合,在协调资源整合应用的前提下,对于应用处理的并行处理要求跟低,只是一种松散耦合的方式,但强调将任务分解、处理、组合的过程,以充分利用现有资源。
虚拟化和云计算是相辅相成的。云计算落地的第一步是IAAS,而云基础架构本身又是搭建在虚拟化技术上面的。 虚拟化技术主要分为以下几个大类 :1.平台虚拟化(Platform Virtualization),针对计算机和操作系统的虚拟化。 2.资源虚拟化(Resource Virtualization),针对特定的系统资源的虚拟化,比如内存、存储、网络资源等。 3.应用程序虚拟化(Application Virtualization),包括仿真、模拟、解释技术等。
云计算是并行计算(Parallel Computing)、分布式计算(Distributed Computing)和网格计算(Grid Computing)的发展,或者说是这些计算机科学概念的商业实现。云计算是虚拟化(Virtualization)、效用计算(Utility Computing)、IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等概念混合演进并跃升的结果。总的来说,云计算可以算作是网格计算的一个商业演化版。
简而言之:
1 云计算是将一台设备通过虚拟化拆分成多台虚拟机器使用。
2 网格计算式将多台设备合并成一台设备使用。
来源:
http://zhidao.baidu.com/link?url=qsg9l4H_Q9zkzZ2hQ4hIKNg9cSgjh9Jdk8E2d7rZz2a8L9XNLLMHepWxjMIZtnq4-dPNR1YOy4i2G4pgj4qtAa
http://zhidao.baidu.com/question/133931838100732005.html?fr=qrl&index=1&qbl=topic_question_1
http://zhidao.baidu.com/question/354342684.html?qbl=relate_question_1
http://zhidao.baidu.com/question/324910551.html?qbl=relate_question_4
http://zhidao.baidu.com/question/70675394.html?qbl=relate_question_0
http://www.chinacloud.cn/
http://bbs.chinacloud.cn/
http://www.chinacloud.cn/show.aspx?id=14382&cid=11
所谓网格计算,是指在逻辑上将接入网络的多台计算机作为一台计算机使用,通过提高各台计算机的使用效率,使其整体的处理能力大大提高,甚至与超级计算机媲美。在网格计算模式下,系统可以自动向每台计算机分配处理任务。如果其中一台计算机出现故障,其它的计算机可以自动替代它并继续进行处理。网格计算的实质就是集中利用分散的IT资源。
企业信息系统的发展经历了三个阶段。第一代处理方式为大型主机集中处理,在这种处理方式下,无论是在物理上还是逻辑上平台都是集中的;第二代处理方式为客户端/服务器型的处理模式,存在数量众多的服务器与客户终端,无论是在物理上还是逻辑上平台都是分散的;网格计算是企业信息系统的第三代处理方式,是物理上分散、逻辑上集中的方式,在逻辑上则可以作为一台计算机来使用。
其实一回事, 堆廉价硬件这种思路不就是互联网穷屌们玩不起超算才想出来的么, 不过超算就是比较精细了, 对很多方面都有优化, 玩得全是高富帅级硬件(IB 级背板带宽, 啧啧, 要是普及到户就能永世宅了).
有幸我村校有一个 WNY 地区唯一的超算中心, 于是蹭了门课有幸参观了超算中心和顺便蹭了个账号实践模拟了一下蛋白质折叠. 这东西真不是你搭个 mapreduce 就玩得起的. 隔壁化学系和建筑系, 生物系的连商学院的都跑过来蹭, 反倒是计算机系的用得少.
针对计算目的不一样, 往往每个超算中心都有不通的通信协议和分布调度策略. 你见过 Spark 或者 Hadoop 改变通信协议和调度策略么(不是没有, 少)
还记得前段时间超算会议开完之后教授上的第一节课失落地呜呼哀哉: top 10 里面中国竟然占了大部分, 美帝就2个, 美帝药丸云云, 心中就充满了自豪啊!(谁叫我们人多计算资源不够啊! 中国应该是唯一一个国家大部分地市级基本上都有超算中心, 要不天气预报和疾控预防怎么玩, 具体我也不知道听这个波兰教授吹的)
1-分布式计算平台例如阿里云所处理的任务通常比较“小”,例如开一个web服务器或者是linux系统的虚拟机,或者说map-reduce这种普通的pc就能养成的一个独立的任务。分布式计算平台直接通过以太网连接(每秒几百MB),通常各个主机的通信量不会很大。
2-而天河这样的超级计算机,通常多个cpu+共享内存形成一块“板”,板和板直接通过超高速互连设备连接,其传输速率能够达到每秒钟几十GB(可能不是很准确,大致)。因为高速互联设备的存在,使得cpu相当于共享内存,一台超级计算机可以看做就是一台计算机,用来做大规模的科学计算,例如需要用几百GB甚至上TB的内存,做大量的运算,这个时候分布式计算平台是无法或者很难完成的。
链接:https://www.zhihu.com/question/21294792/answer/97775433
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主应该是认为:分布式计算集群计算速度辣么辣么快了,只要并连电脑足够多,计算速度就能超过天河超级计算机,那么要天河干嘛?(⊙o⊙?)
我给题主举个通俗易懂的例子:
假设π后面有几十亿位,我们就要把这几十亿位给算出来。
超级计算机的计算能力十分出众,一分钟可以计算1万位,普通计算机可以计算100位,计算集群可以并连100台电脑从而计算速度和超级计算机势均力敌。
但是真的可以这样吗??
答案是不能的,计算π是连续的,前后关联的,真的能让计算利群的第一台电脑负责前100位,第二台负责第100位到200位……
计算π是一整个数的计算,不可以分拆!!所以计算集群算π的计算速度仍为100,天河却是10000。
这个就不说了,计算π那都是渣渣,复杂的天体物理学,那才是天河的战场。
但是超级计算机也不能取代计算集群。
假如百度一下“美白教程”,对于这个搜索请求,百度可以分给多台计算机分别搜索,电脑1搜贴吧,电脑2搜网页,电脑3搜经验,电脑4搜文库……甚至可以细分给10000台电脑。
而天河就得从头开始搜,先搜贴吧,接着网页,再经验,最后文库……速度再快也干不过计算集群量大啊。
所以计算集群和超级计算机的存在都是有必要的,他们特点不同,却各有长处。
以上为个人浅见,如有错误,还请一定指出。因为是个渣渣,见识短浅,举不出高端的例子,说到这里都快要哭出来了。。。
但是很多本质上是串行化的任务是无法并行拆分的,比如微积分计算、正则表达式匹配、航天、卫星轨道计算等,这些都依赖单机单线程的强大计算能力,因此大型机是不可或缺的。
还有,分布式要应对的主要问题是PC的稳定性,如果突然的宕机可能会对金融领域造成致命的不一致性,而大型机有着良好的可靠性和服务,自然有存在的市场。
举个例子,搜索引擎在对用户搜索词做分析时,需要进行大量的模式匹配,为了保证速度我们把模式存在内存词典中,这就导致对搜索词的分析程度受限于单机内存。市面上能买到的机器内存一般在 200GB 以下,这导致很多高级分析难以开展,进而影响搜索结果质量。
怎么解决呢?一个思路就是尝试用 infiniband 或 fpga 等做高速网络,跨机器访问内存,进而 cpu 密集任务(如文本相关性计算)、多轮迭代的 io 密集型任务(如机器视觉)也能得到改善。
天气预报、地理勘探、生化实验等也是同样的,要么单个任务太大,要么任务间交互太多,这都超出了 PC + 以太网集群的能力,需要借助高速网络组成一个超级单机。这就是超算了,很必要。
天河1A的网络是定制网络硬件和定制协议,点对点带宽我记得是40G/s。天河二只会更快。
具体到程序来说,计算能力需求是一方面,更重要的还是数据通信,比如我们组的计算程序一般要上千个进程,每一个进程每秒要收发几百兆的数据,计算要持续几个小时到几天。
链接:https://www.zhihu.com/question/21294792/answer/90034776
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 天河是并行计算的机器集群,是为了解决高性能计算的问题。
- 分布式计算是为了解决大量的计算问题。
以矩阵相乘为例:分布式计算比较适合计算百万个1000×1000的矩阵的相乘;而并行计算比较适合计算一个1000000000×100000000矩阵的乘法。
为了达到上述的要求,以天河超级计算机为代表的并行计算集群的体系结构不同于一般的分布式集群,每个节点的CPU/GPU 数量多,内存大,计算前所有数据读入内存,计算过程中几乎不访问硬盘,硬盘只作为数据的备份和运算结果的保存。为了针对特定领域所需要的高并发性能,往往采用高吞吐、高性能的GPU或者特定的FPGA 代替一般的CPU进行计算,而分布式则采用通用的商用服务器或者更低廉的机器。
可见就计算能力来说,分布式计算集群在并行计算集群面前就是小巫见大巫,完全不是一个数量级,但所针对和解决的问题也是不同的。下图比较了天河二号和百度集群的一些规模参数:
<img src="https://pic2.zhimg.com/e1aca4a36dd1d70fdb63ea13e36ef205_b.png" data-rawwidth="588" data-rawheight="270" class="origin_image zh-lightbox-thumb" width="588" data-original="https://pic2.zhimg.com/e1aca4a36dd1d70fdb63ea13e36ef205_r.png">

还有一个就是并行计算的实时性要求比分布式计算要高。(比如气象、灾难卫星采集的数据需要准实时地分析得到结果,以便尽快处理灾情,这样并行计算比较合适;而分布式计算比较适合实时性较弱的业务,如日志分析和数据挖掘)
首先题主问题有问题。
计算机分为超级计算机、大型机、中型机、小型机和微型机。天河是超级计算机,不属于大型机。
介于问题不专业,所以我还是尽量用通俗的话讲。(开个玩笑)
纯属个人观点。
超级计算机一直是用于科学研究,走在时代的前列。因为超算的体系结构和指令结构都是十分复杂的,所以一直凸显出的是它的计算速度。对于超算的研究,是有助于计算机的发展的。但是,超算也只是适合待在实验室,毕竟它结构复杂,造价昂贵,维护成本更不必说。而且超算的计算速度与IO瓶颈问题,使得超算大部分时候处于空跑状态。
大型机现在专指IBM主机,也就是英文里面的mainframe专指。最早时候,在PC出来之前,其实只有大型机的。IT领域的应该都看过著名的《人月神话》这本书,现在的大型机就是书里面的IBM 360发展过来的。大型机速度虽然赶不上超算,但是通过各种平台的软件及体系,很好的平衡了计算速度和IO,使得其很好的运用于大型数据中心。但也是由于其维护成本高昂,都是大型非技术公司购买其服务的。在中国,比如五大银行、证券、金融等公司。在国外,大型机客户就多了,还涉及到一些医疗数据中心等等等等。而且大型机是按每年的计算量收费的,不是一次性支付。总的来说,大型机还是比较有应用性。
中小型机,现在几乎已死,分布式计算的出现使之成为一块鸡肋。价格不便宜,却达不到大型机的运算能力。
至于题主提到的分布式计算平台,大部分是由x86架构PC集群构成。因为PC便宜,坏了就换,而且可以完成现在海量数据的处理。所以,现在很多科技公司都愿意使用x86集群,因为有技术团队,而且维护成本低廉。
其实无论是PC集群还是超大型机,是人们两种相对的处理问题的方式而已。题主的问题标签是云计算,而云计算暨可以采用集中式,如超算和大型机,也可以采用分布式,就是如今火热的分布式。
说到此,顺便评论下中国的去IOE之风。自从当局指示国内要自力更生,去IOE后,各个大小公司都开始喊着去IOE,经常有朋友和我谈类似的问题,说我们大机已死,巴拉巴拉。。。但是中国目前并没有可以代替的技术能够真正实现,尤其是像五大行那种,要求要用浪潮服务器取代。当年没技术引进技术,现在依赖过很,已经去不掉了。
好吧,说了那么多,其实我想说的是,存在即合理。请大家忽略上一段话,我只是个学大型机又学分布式的学生,我连皮毛都不懂,我瞎扯的,不喜勿喷。我毕业论文还没写完,匿了。
然后天河一号不属于distributed computing, 她是parallel computing, 两个不是一个东西,天河一号不仅有存在的必要,而且是计算容量还远远不够,越多越好,没有上限的。这根本不是争排名,而是现实需要摆在那里,巨大的需求。
先讲讲distributed computing和parallel computing的区别。distrubuted computing是指很多个computing node分散开,互相之间没有很快的网络连接,各自领一个任务的一部分,算完后把结果汇总。这个任务是可以分解成一个个独立的小任务,不需要node之间太多通信的。而parallel computing是很多个computing node放在一起,互相之间用最快的网络连接,一起计算一个任务,这个任务有很多个步骤,需要各个node之间有很频繁的通信,通信的数据量可以很大。
举个例子,矩阵的加法是可以分解成各个模块,一个node可以独立算出对应模块的结果。矩阵的乘法就需要分解之后各个node频繁通信。学MPI应该会写过矩阵乘法。
最后讲parallel computing的必要性。科研和工业上应用都很多,说几个实际的例子吧,飞机空气动力学模拟,天气预报。这些缺口都很大,希望出现更多的天河。
超算并不是一块特别大的主板上面插了几十万个CPU,而是分为一个又一个的节点,每个节点都有一定数量的核(比如说32)。节点与节点之间需要通过网络进行通讯。即使是使用了比普通的网络快很多的InfiniBand,很多程序在超算上跑的时候性能瓶颈依然是在节点之间的通讯,因为数据量实在太大了。可想而知如果这种任务放在分布式计算上跑,使用平均200KB/s而且时不时掉线的网络传输数据程序要跑多久。
我记得我们学校超算的一个老师曾经说起过一件事情:有一帮搞核物理(貌似是,记不太清了)的去找IBM帮忙提升他们程序的计算效率,IBM的专家研究发现这个程序的特点是,相邻节点之间的数据交互非常巨大,而其他节点之间则只有少量数据交互。于是IBM的专家就为此程序专门研发了一个超级计算机,这个超级计算机相邻节点之间的通讯效率比一般的超算快非常多,而非相邻节点之间的通讯的性能则比较平庸。用这个计算机跑那个程序速度提升非常明显,而且世界让没有任何一款纯的软件能够打败他。
手机打字,回头有空想起再补充。
先给出两个结论:
1、现在所以超级计算机本质上都是集群;
2、集群可以做分布式计算,但高性能计算的要求比分布式计算要苛刻得多。
下面逐条说明:
1:超算以前有MPP、SMP等形式的存在,那些都是专用机器,近10年来超算已经全面向集群转变,一台大超算是由很多个计算刀片组成的。这也就是为什么有人说天河二号是砸钱高级DIY,因为天河二号除了主板(这个我不确定)以外的所有主要硬件都是商用设备,有钱总能买到。
2:现在的超算,或者说高性能集群,你完全可以当分布式集群来用。但是超算有更高级的文件系统和存储系统,更快个更低延迟的IB网,以及量身订造优化过的MPI跨节点(分布式)运行环境。后者非常重要,我觉得几乎可以说是现在超算的核心技术之一。现在的那些分布式系统,其计算任务都是松耦合的,没有什么明显的前后依赖。但是超算上跑的科学计算不一样,往往上一步解的结果下一步要用,因此各节点之间需要低延时的数据交换。实际上访问数据的延时和带宽是大多数高性能计算应用容易遇到的瓶颈,也是优化程序时主要着力点之一(因为内存带宽和速度跟不上CPU的速度),在一个节点内如此,跨节点的传输问题会更严重。所以才要上IB网,才要针对性优化MPI环境。分布式系统不一样,没有这个压力,我有一亿张图片要压缩我就平分下去各机器压缩完了传回来就行。所以高性能集群去做分布式系统没有任何问题,反之则不行。
----------15.12.13更新----------
看到楼上楼下有那么多人对大型机的认识不正确,我给你们一点用百度都能搜到的资料:
某国产大型主机:浪潮天梭K1 910 ,请点去技术规格那里看看
IBM 最新的大型机 z13:IBM z SystemsIBM大型机老而弥坚 z13中国市场漆黑一片_DOIT.com.cn
实际上现在的大型机里面也要用到『通用』的微处理器(IBM大型机的微处理器是Power系列的改过来的,至于安腾,虽然现在已经半死不活,也勉强可以算是『通用』吧,还有其他机器有用到),所以里面也是一大堆处理核心,而不是什么单核单线程能力很强。
下面这张图是《Computer Architecture : A Quantitative Approach (5th edition)》给出的各场景宕机时长平均带来的损失,还是2000年统计的老数据:
<img src="https://pic3.zhimg.com/abd242ae1f3bfcc8cee4b472b1977076_b.png" data-rawwidth="705" data-rawheight="372" class="origin_image zh-lightbox-thumb" width="705" data-original="https://pic3.zhimg.com/abd242ae1f3bfcc8cee4b472b1977076_r.png">所以大型机要的是稳定和安全,因为银行部门不允许在交易高峰出现哪怕五分钟的宕机。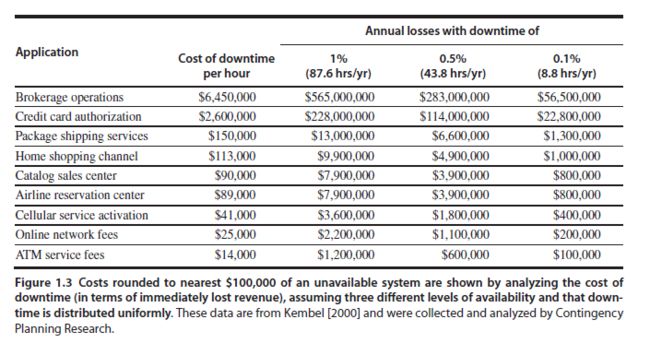 所以大型机要的是稳定和安全,因为银行部门不允许在交易高峰出现哪怕五分钟的宕机。
所以大型机要的是稳定和安全,因为银行部门不允许在交易高峰出现哪怕五分钟的宕机。
至于计算能力,这里应该做一个区分:浮点计算能力和整数计算能力。前者在任何形式的仿真计算(所有的科学计算和模拟都是仿真计算)中都是至关紧要的;后者在事务性计算上,突出表现为数据库以及日常软件应用,关系紧密。
说大型机的计算能力强大,是指其整数计算能力很强;至于其浮点运算能力,一台大型机也打不过两三块Tesla K80计算卡。没有人现在会去买大型机来做浮点运算,除非是土豪钱多任性。
而现在用在超算上的计算设备,都在加强并行(向量)浮点处理能力。因为大部分科学和工程计算问题最终都要转化到一个或多个矩阵计算问题上,而矩阵计算问题就要处理大量的向量。所以Xeon Phi里有512位的向量部件,GPGPU上有上千个流处理器,都是极其具有针对性的。
好,回到原本的问题上,我解释一下为什么说网络通信技术,也就是硬件层面的IB网架构和软件上的MPI跨节点通信库的调试,是超算的核心技术之一。
先说硬件。现在世界上跑得最快的500台超级计算机,在Home | TOP500 Supercomputer Sites查到完整的列表。排名前50的超算,其互联方式基本都是定制的(基于InfiniBand)或者直接就是IB网,排名最前的非定制非IB网的机器是第66名联想自己弄的一套,Segment是Industry。用以太网的机器,其持续运行速度(你基本上可以理解为一个充分优化的应用能连续跑出来的最快的速度)比起其理论最大速度,很多都没有超过一半。过半的那些很多都是排名比较后或者计算节点数比较少的机器。Mellanox在其报告http://www.mellanox.com/page/top_500中也提到,将近一半的超算用了IB网。而商用的分布式计算集群,比如第66名那台,用的是万兆以太,计算效率只有三分之一不到。但是作为商用集群,这一点问题都没有。
再说一下MPI通信库的问题。有好的硬件,也要有好的软件去用,前50的超算基本都会针对自己的架构去做一个MPI库的优化。现在能获取到的免费高性能通用MPI库有OpenMPI、MPICH和MVAPICH,商用的有Intel MPI。天河二号上的MPI是基于MPICH做了深度优化的。我之前有一个程序,在16个节点上运行,每个节点上有一个长度为三千两百万的double型向量,要将这16个向量做加法,然后存到一台机器上,MPI库有一个函数MPI_Reduce提供现成的算法去处理。Intel MPI做一次这样的处理,用时比天河二号自主的MPI要慢了一倍有多。所以如果你不去做优化,那些一边计算一边需要MPI交换数据的程序,就会很慢。分布式集群一般就不会去处理这种事情,最多买个好一点的商业库,或者直接用免费的。这样的话做科学计算的速度就远远不如定制过MPI库的超算了。
另外,就我所知,超算上的应用里,有磁盘IO瓶颈的不多,更多的是内存带宽和网络延时&带宽瓶颈。但商用分布式集群处理的问题,MapReduce之类的,对磁盘IO的要求就比较大。这个时候商用集群可以用便宜单击来达到高磁盘IO。至于超算,它每个计算节点自己也有一块硬盘,但是不存数据。所有的用户数据都是存放在一个统一的高性能存储阵列上。
链接:https://www.zhihu.com/question/21294792/answer/18068428
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.超级计算机用infiniband这种通信背板、各种企业级内部互联架构……以便提高各节点间的网络IO,常规分布式集群一般都是千兆、万兆网卡。
2.超级计算机一般会配高档的磁盘阵列,而GFS+Mapreduce方案底层基于挂在各节点上的普通硬盘。
3.超级计算机会使用更先进的CPU和GPU,更多内存。
4.由于发热强劲,很多超级计算机采用水冷。
从这些细节可以看出:
1.超级计算机更适合计算密集型作业,如果你是用MPI算核物理、天体物理、蛋白质折叠、渲染《阿凡达》、求解普通PC上需要几千万年的迭代方程,那么就应该用超级计算机。反过来,分布式集群Mapreduce适合IO密集型的作业,加上成本低,可以把集群规模搞得很大,因此最适合扫描过滤海量的数据,例如互联网行业的经典应用:为搜索引擎创建全网Web页面的索引。
2.超级计算机造价更昂贵,维护成本也高,甚至每小时电费就得上万元。记得我以前做蛋白质搜索引擎的时候,在国内最大的超级计算机之一跑过一个80分钟的job,花了老板5000多块上机费(因为我们有项目合作,人家已经给我们打了很低的折扣了)。不过这些作业用MapReduce在普通分布式集群上跑,跑了好几天。
云计算是建立在廉价分布式硬件+牛B的软件系统设计上,在商业上越来越成功。所以正在抢占传统超级计算机的用户市场。例如阿里云刚刚和国内的动画公司合作渲染出来的《昆塔》,计算量是阿凡达的四倍。不过就我所知,各大传统超算中心其实依然是排队、忙不过来的。随着国内经济的升级,很多造船、石油、材料、生物、天体物理、军事领域的计算需求都很强烈,这一类计算密集型任务,性能和时间往往比成本更重要。
最后是广告时间(求不折叠)。我们团队在招人,云计算、大数据、分布式计算人才很合适,欢迎投简历,具体信息参考 GeneDock 也欢迎推荐,成功入职后奖励推荐人iPhone或DJI大疆无人机。