一、说明
本次配置基于上一篇博客《Hadoop完全分布式搭建全过程》做补充,基于完全分布式做高可用搭建。。。。。。
二、原理
产生背景:Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
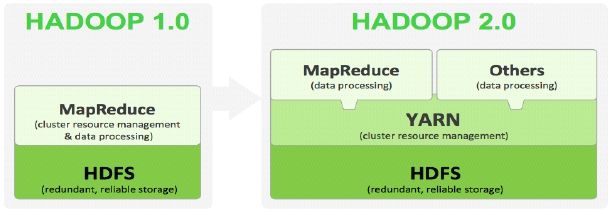
HDFS存在的问题
NameNode单点故障,难以应用于在线场景 HA
NameNode压力过大,且内存受限,影扩展性 F
MapReduce存在的问题
JobTracker访问压力大,影响系统扩展性
难以支持除MapReduce之外的计算框架,比如Spark、Storm等
Hadoop2.0模块:Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
HDFS:NN Federation(联邦)、HA;
2.X:只支持2个节点HA,3.0实现了一主多备
MapReduce:运行在YARN上的MR;
离线计算,基于磁盘I/O计算
YARN:资源管理系统
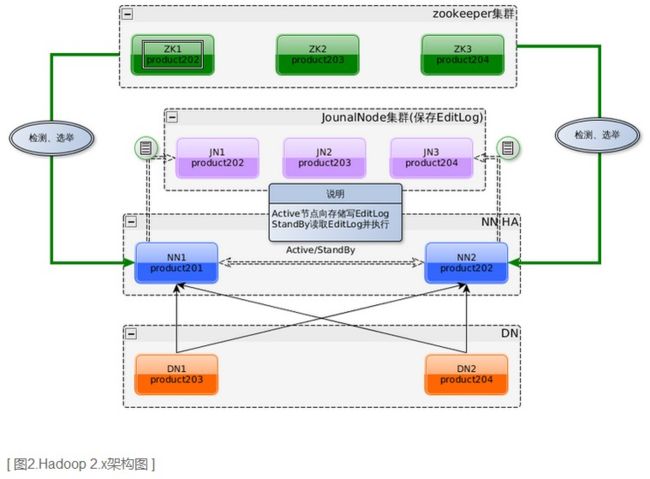
对于单点故障,Hadoop2.X中实现主备模式,有两个NameNode节点,去除Hadoop1.X中的SecondaryNameNode节点,用actived和standby状态区分主备机,也就是有两台NameNode主机,一台对 外提供服务(actived),另一台处于待命状态(standby),当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下, 手工或者自动切换到另一个NameNode提供服务,两个NameNode节点有 下面几点需要说明:
1、任务分工:active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
2、数据同步:两台NameNode元数据同步策略,官网提供了两种同步策略NFS(Network File System)和QJM(Quorum Journal Manager),一般采用QJM方式,原因及QJM方式文章后面补充
3、健康检测:Hadoop2.X中使用zookeeper中ZKFC(zookeeper failover controller)对两台NameNode进行健康检测,ZKFC对应NameNode节点会在zookeeper中抢占锁(向zookeeper创建一个 节点,如果已经被创建,说明对方已经抢占锁,自己只能是standby状态)来决定自己处于actived状态还是standby状态
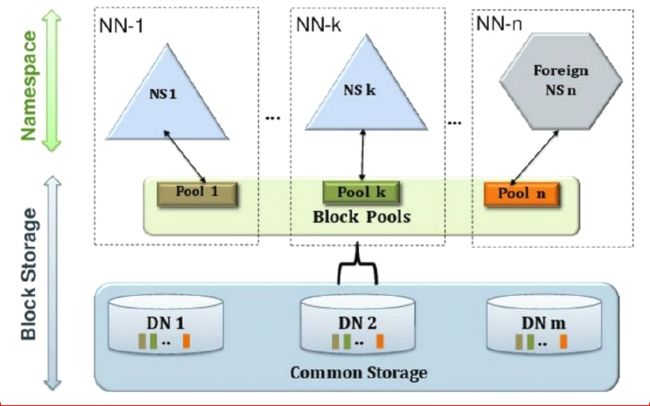
对于内存受限,Hadoop2.X中采用federation(联邦)机制,对NameNode水平扩展,支持多个NameNode,每个NameNode独立管理内部元数据,NameNode之间互不影响;举个例子:NameNode存 储的都是人的元数据信息,NameNode1存储老人元数据,NameNode2存储中年人元数据,NameNode3存储儿童元数据。。。。。。联邦机制有以下两点特点:
1、相互独立:NameNode之间相互独立,不存在元数据交叉,各自维护自己的空间目录树,NameNode1挂机不能被NameNode2替代
2、存储共享:各个NameNode共用同一个DataNode集群,存储共享,DataNode向每个NameNode汇报信息
联邦机制的三大价值:
1、命名空间的扩展:多台NameNode,不同的命名空间,随着集群使用时间的加长,HDFS上存放的数据也将会越来越多.这个时候如果还是将所有的数据都往一个NameNode上存放,这个文件系统 会显得非常的庞大.这时候我们可以进行横向扩展,把一些大的目录分离出去.使得每个NameNode下的数据看起来更加的精简.
2、性能的提升:这个也很好理解.当NameNode所持有的数据量达到了一个非常大规模的量级的时候(比如超过1亿个文件),这个时候NameNode的处理效率可能就会有影响,它可能比较容易的会陷 入一个繁忙的状态.而整个集群将会受限于一个单点NameNode的处理效率,从而影响集群整体的吞吐量.这个时候多NameNode机制显然可以减轻很多这部分的压力.
3、资源的隔离:通过多个命名空间,我们可以将关键数据文件目录移到不同的NameNode上,以此不让这些关键数据的读写操作受到其他普通文件读写操作的影响.也就是说这些NameNode将会只处 理特定的关键的任务所发来的请求,而屏蔽了其他普通任务的文件读写请求,以此做到了资源的隔离
对于联邦机制和HA,目前联邦机制企业中并不多见,需求还不普遍,可能未来会向这个方向靠近,具体配置就不说明了,针对HA有以下需要具体说明一下,实现HadoopHA技术难点是什么?无非就 是两点:主备NameNode数据同步,和NameNode脑裂控制
上面说了Hadoop2.x中实现HA中数据同步,namenode数据分三种:内存镜像、磁盘镜像fsimage,操作日志edits.为什么使用的是QJM方式,接下来会介绍一下QJM运行原理,介绍QJM之前首先说明为什么不用官网上的另一种方式NFS
| In order for the Standby node to keep its state synchronized with the Active node, the current implementation requires that the two nodes both have access to a directory on a shared storage device (eg an NFS mount from a NAS). This restriction will likely be relaxed in future versions. When any namespace modification is performed by the Active node, it durably logs a record of the modification to an edit log file stored in the shared directory. The Standby node is constantly watching this directory for edits, and as it sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the shared storage before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs. |
摘抄自官网一段描述:大意就是让两个NameNode都可以访问同一个共享存储设备目录,actived节点做任何修改更新操作都把操作日志持久化到共享存储设备,standby状态的节点不断监测日志的变 化,自己做同步操作,这样确保两个NameNode之间操作一致达到数据的最终一致性,通过描述,很明显能看出NFS方式弊端:远程文件管理器本身就可能存在单点故障的问题,服务器可能过载导致停止 服务,另外还需要挂载文件夹,硬件设备必须支持NAS,定制隔离脚本,部署麻烦bug多...........接下来看看QJM方式怎么做的
| In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called "JournalNodes" (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the JounalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs. |
同样摘抄自官网:大致原理和NFS原理差不多,都只能实现数据的最终一致性,但是QJM(Quorum Journal Manager)方式实现的中间件是:journalnode(JN),JournalNode属于轻量级的进程,可 以与其他NameNode或者DataNode并行在一个节点,每个JournalNode对外有一个简易的RPC接口,以供NameNode读写EditLog到JN本地磁盘。当写EditLog时,NameNode会同时向所有JournalNode并 行写文件,只要有N/2+1结点写成功则认为此次写操作成功,遵循Paxos协议。
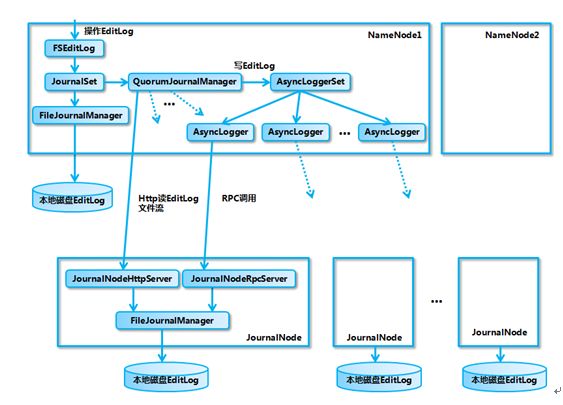
对于NameNode的主备切换机制,Hadoop依赖于zookeeper的选主机制,整个切换过程是由ZKFC来控制的,具体又可分为HealthMonitor、ZKFailoverController和ActiveStandbyElector三个组件。
-
- ZKFailoverController: 是HealthMontior和ActiveStandbyElector的母体,执行具体的切换操作
- HealthMonitor: 监控NameNode健康状态,若状态异常会触发回调ZKFailoverController进行自动主备切换
- ActiveStandbyElector: 通知ZK执行主备选举,若ZK完成变更,会回调ZKFailoverController相应方法进行主备状态切换
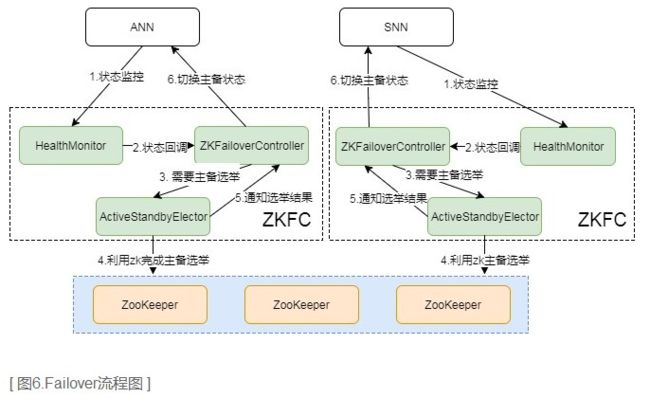
在故障切换期间,ZooKeeper主要是发挥什么作用呢,有以下几点:
-
- 失败保护:集群中每一个NameNode都会在ZooKeeper维护一个持久的session,机器一旦挂掉,session就会过期,故障迁移就会触发
- Active NameNode选择:ZooKeeper有一个选择ActiveNN的机制,一旦现有的ANN宕机,其他NameNode可以向ZooKeeper申请排他成为下一个Active节点
- 防脑裂: ZK本身是强一致和高可用的,可以用它来保证同一时刻只有一个活动节点
归纳起来主要是两块:元数据同步和主备选举。元数据同步依赖于QJM共享存储,主备选举依赖于ZKFC和Zookeeper。
三、配置
*)规划
NN DN ZKFC ZK JN
node211 * * *
node212 * * * * *
node213 * * *
node214 * * *
*)基础设施
先停掉之前的完全分布式程序
*stop-dfs.sh
网络
ssh免密钥:手动输入命令启动程序太麻烦,所以用脚本控制程序启动,但是需要登录各个主机时的用户名和密码,在这里设置免密钥就可以直接登录
除了之前设置node211对其他主机免密之外,这里需要设置两台NameNode之间的相互免密,因为ZKFC会监测对方状态
node212:
cd ~/.ssh
scp ./id_dsa.pub root@node211:`pwd`/node212.pub
node211:
cd ~/.ssh
cat node212.pub >> authorized_keys
接下来就是修改配置文件了:hdfs-site.xml
dfs.nameservices
manzi
dfs.ha.namenodes.manzi
nn1,nn2
dfs.namenode.rpc-address.manzi.nn1
node211:8020
dfs.namenode.rpc-address.manzi.nn2
node212:8020
dfs.namenode.http-address.manzi.nn1
node211:50070
dfs.namenode.http-address.manzi.nn2
node212:50070
dfs.namenode.shared.edits.dir
qjournal://node214:8485;node212:8485;node213:8485/manzi
dfs.client.failover.proxy.provider.manzi
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.journalnode.edits.dir
/var/journal/data
dfs.ha.automatic-failover.enabled
true
core-site.xml:
fs.defaultFS
hdfs://manzi
ha.zookeeper.quorum
node211:2181,node212:2181,node213:2181
hadoop.tmp.dir
/var/manzi/hadoop/
mapred-site.xml
mapreduce.framework.name
yarn
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node213
yarn.resourcemanager.hostname.rm2
node214
yarn.resourcemanager.zk-address
node211:2181,node212:2181,node213:2181
接下来安装zookeeper,tar -xf命令解压到/opt/manzi/(自定义)目录下,
编辑zookeeper配置文件:
cd /opt/manzi/zookeeper/conf cp zoo_sample.cfg zoo.cfg vi zoo.cfg server.1=node211:2888:3888 server.2=node212:2888:3888 server.3=node213:2888:3888
创建myid文件,目录根据配置文件决定:/var/manzi/zookeeper/
mkdir -p /var/manzi/zookeeper cd /var/manzi/zookeeper echo 1 >> myid
复制zookeeper到其他zookeeper节点:
cd /var/manzi/ scp -r ./zookeeper/ node212:`pwd` scp -r ./zookeeper/ node213:`pwd`
cd /opt/manzi/
scp -r ./zookeeper/ node212:`pwd`
scp -r ./zookeeper/ node213:`pwd`
在node212和node213分别操作:
cd /var/manzi/zookeeper
echo 2 > myid --node212
echo 3 > myid --node213
编辑配置文件:
/etc/profile export JAVA_HOME=/usr/java/default export HADOOP_HOME=/opt/manzi/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export ZOOKEEPER_HOME=/opt/manzi/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin
复制profile文件
/etc scp profile node212:`pwd` scp profile node213:`pwd` scp profile node214:`pwd`
统一执行:source /etc/profile
复制Hadoop配置文件:
cd /opt/manzi/hadoop/etc/hadoop scp ./*.xml node213:`pwd` scp ./*.xml node212:`pwd` scp ./*.xml node214:`pwd`
启动journalnode:
node212,node213,node214 hadoop-daemon.sh start journalnode
hdfs格式化并启动主NameNode:
node211 hdfs namenode -format hadoop-daemon.sh start namenode
备NameNode同步数据:
node212 hdfs namenode -bootstrapStandby
格式化ZKFC并启动hdfs:
node211 hdfs zkfc -formatZK start-dfs.sh