为什么80%的码农都做不了架构师?>>> 
背景:
最近在尝试将kafka的数据同步到elasticsearch中,这就用到了confluent的kafka-connect-elasticsearch套件了。一套基于kafka connector思想的数据连接套件。

源码地址:
https://github.com/confluentinc/kafka-connect-elasticsearch
安装部署:
参考官方文档,当然,官方文档是too simple的。实际用的时候还是有些许地方要值得注意的。
手动部署:
1、将confluent-5.2.0-2.12.zip整个包下载下来,虽然比较大有500M+,但是里面的套件比较全面,以后要用到其他套件的话就不用单独下载了。
2、解压:unzip一下即可
3、修改配置:
3-1、etc/schema-registry/connect-avro-standalone.properties 主要确认一下 bootstrap.servers 是否配置正确
bootstrap.servers=xxx.xxx.xxx.xxx:9092
3-2、etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties 主要确认 ES的连接地址和index、type等信息
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=infra-log-tracing
key.ignore=true
connection.url=http://xxx.xxx.xxx.xxx:9200
type.name=trace
topic.index.map=infra-log-tracing:infra_logging_trace详细配置及含义请参考源码:https://github.com/confluentinc/kafka-connect-elasticsearch/blob/c3474f762e5a7d80dd7381b466af540bc6c708ba/src/main/java/io/confluent/connect/elasticsearch/ElasticsearchSinkConnectorConfig.java
值得注意的地方是默认同步数据时,index名会以topic名一致,并且type和mapping不是自己定义的。
如果全部要自己定义的话需要通过topic.index.map配置建立topic和index的映射关系,并通过type.name指定到自己定义的type名
private static final String SCHEMA_IGNORE_CONFIG_DOC =
"Whether to ignore schemas during indexing. When this is set to ``true``, the record "
+ "schema will be ignored for the purpose of registering an Elasticsearch mapping. "
+ "Elasticsearch will infer the mapping from the data (dynamic mapping needs to be enabled "
+ "by the user).\n Note that this is a global config that applies to all topics. Use ``"
+ TOPIC_SCHEMA_IGNORE_CONFIG + "`` to override as ``true`` for specific topics.";通过上面文档说明,topic.schema.ignore默认为false,如果将其设置为true,则为动态创建mapping,我们大多情况下会事先定义好自己的mapping,因为我们会去设计mapping字段的最优类型和分词规则,所以自定义mapping的情况下不要设置为true。
3-3、etc/schema-registry/connect-avro-standalone.properties 这里根据运行模式选择对应配置文件
# Bootstrap Kafka servers. If multiple servers are specified, they should be comma-separated.
bootstrap.servers=localhost:9092
# The converters specify the format of data in Kafka and how to translate it into Connect data.
# Every Connect user will need to configure these based on the format they want their data in
# when loaded from or stored into Kafka
#key.converter=io.confluent.connect.avro.AvroConverter
key.converter=org.apache.kafka.connect.converters.ByteArrayConverter
key.converter.schemas.enable=false
key.converter.schema.registry.url=http://localhost:8081
#value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
# The internal converter used for offsets and config data is configurable and must be specified,
# but most users will always want to use the built-in default. Offset and config data is never
# visible outside of Connect in this format.
#internal.key.converter=org.apache.kafka.connect.json.JsonConverter
#internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter=org.apache.kafka.connect.storage.StringConverter
internal.value.converter=org.apache.kafka.connect.storage.StringConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false这里需要注意bootstrap.servers的地址,除此之外,重点来了,如何选择key.converter和value.converter?
对于此,请参考文章:https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained
能不能说中文(中文版):https://www.mayi888.com/archives/57279
因为我的程序是将json以字节数组的方式将消息发送到kafka的,也就是是topic的消息是字节流。而写ES时则需要json格式的,所以我在没有更改配置运行时,会出现以下异常:
1)Unknown magic byte
2)Compressor detection can only be called on some xcontent bytes or compressed xcontent bytes
这里需要注意从kafka解码需要指定key.converter和value.converter,这里由于topic的消息是字节流,所以直接用value.converter=org.apache.kafka.connect.json.JsonConverter将其转为json字符串。一定要注意value.converter.schemas.enable=false,因为消息中本身是没有包含schema 和 payload 这两个顶级元素,然后设置以下配置
internal.key.converter=org.apache.kafka.connect.storage.StringConverter
internal.value.converter=org.apache.kafka.connect.storage.StringConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
注意:因为已经将topic消息转为json了,所以内部不用再转json了
最后启动
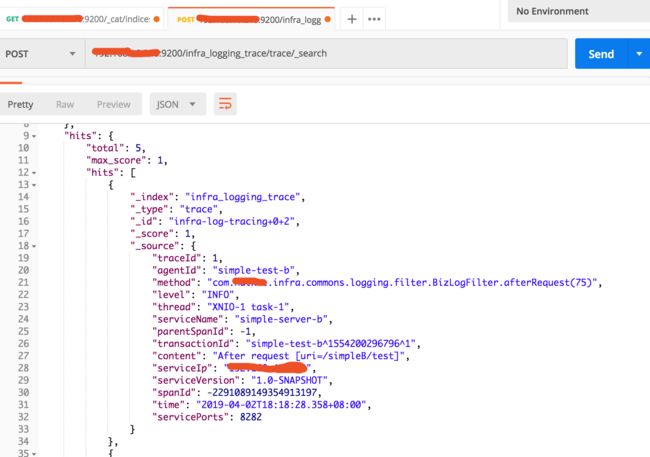
./bin/connect-standalone -daemon etc/schema-registry/connect-avro-standalone.properties etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties检查没有报错。
查看ES数据: