zookeeper和hadoop集群(伪分布式)
1.Zookeeper官网
http://zookeeper.apache.org/
2.安装Zookeeper
解压,配置环境变量,启动
根目录下bin/zkServer.sh start
这里是三台虚拟机,hadoop001,hadoop002,hadoop003
命令行客户端:
[root@hadoop001 bin]# ./zkCli.sh (之后回车)
相关命令:
[zk: localhost:2181(CONNECTED) 2] help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch] (查看)
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path (删除)
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
[zk: localhost:2181(CONNECTED) 3]
3.安装Hadoop
对于三台机器来说,可以先装好一台,然后使用scp -r命令把文件夹和文件传到两外两台上,如果是很多台的话,可以配置shell脚本
4.HDFS HA
4.1对于三台机器,其分别启动的进程有
hadoop001: 192.168.137.200
zk
NN(active) (对于两台NN来说,会有一个是active,另一个是standby)
DN
DFSZKFailoverController(ZKFC) 进程
JN 进程 (journalnode)
hadoop002: 192.168.137.201
zk
NN(standby)
DN
DFSZKFailoverController(ZKFC) 进程
JN 进程
hadoop003: 192.168.137.202
zk
DN
JN 进程
热备(实时备份): 元数据信息想要热备,必然要有一个公共的存储的地方(JN)
4.2这里的zkfc的作用就是选举active
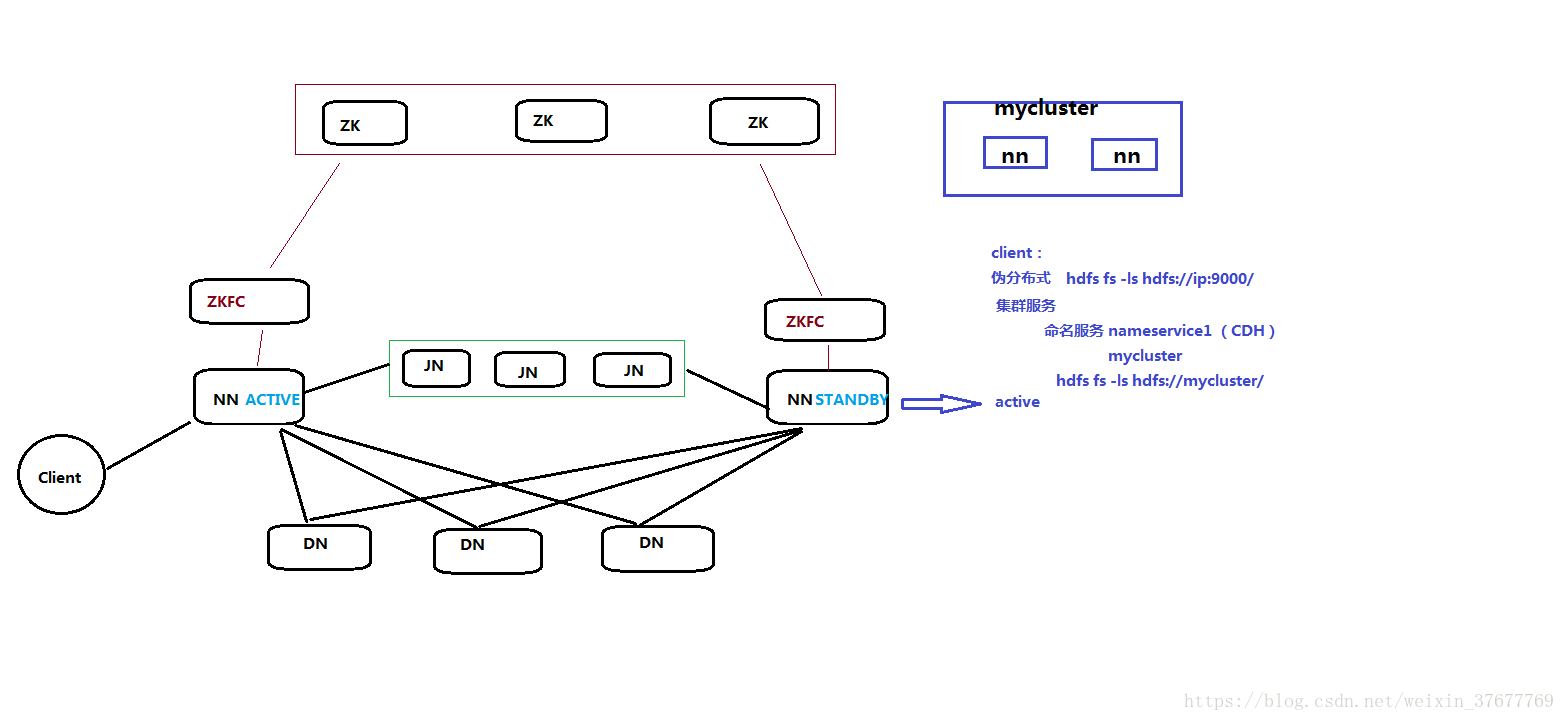
注:DN向NN做的两个工作,一、向两个NN发送心跳(虽然有一个是热备,但是有成为active的可能),二、向NN发送块报告(有多少个块,块有什么问题)
zkfc报告时用的都是RPC请求(好像整个流程都是RPC)
两个NN的元数据放在JN里面(共享存储)
Hadoop2.x里standby1个,而在3.x里standby可以有多个
4.3HA:
命名服务 (CDH):nameservice1 (hadoop001+hadoop002)(这个不关心谁是active,只是去访问命名空间,命名空间是hadoop001+hadoop002,里面有一个是active)
nameservice1在配置文件core-site.xml里面改成了mycluster
fs.defaultFS
hdfs://mycluster
hdfs dfs -ls hdfs://nameservice1/
假设NN1 active:
hdfs dfs -ls hdfs://192.168.137.131:8020/ active 可以的访问, 有读写权限(这个是NN1)
hdfs dfs -ls hdfs://192.168.137.132:8020/ standby 可以, read only(这里的读写指的是对DN的操作)
5.YARN HA
所起的进程(这里的zkfc是线程)
hadoop001: 192.168.137.200
zk
RM(ZKFC 线程)(是RM里的一个子线程,ps -ef看不到)
NM
hadoop002: 192.168.137.201
zk
RM(ZKFC 线程)
NM
hadoop003:
zk
NM
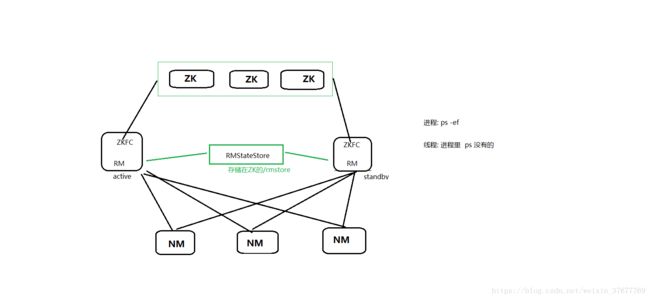
相关知识:
1.DN(数据存储)和NM(计算)部署在同一台: 数据本地化 减少网络消耗,让计算更加的快
2.ZKFC是线程
3.RMStateStore: 在ZK
4.元数据存储在/rmstore 在zk上
6. 集群部署
6.1配置多台互相SSH信任关系(Apache HADOOP)
https://blog.csdn.net/weixin_37677769/article/details/82903881
注:问题: A机器是中心调度机器,B机器shell脚本(某个服务的),A调B的shell,无密码调用的的话,需要谁给谁密钥?
答案: A给B
根据RSA加密的流程,A的公钥给了B才行
6.2部署HDFS HA 和YARN HA
配置文件:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves
根据配置信息执行下面的语句;
mkdir /opt/software/hadoop/tmp && chmod -R 777 /opt/software/hadoop/tmp && mkdir -p /opt/software/hadoop/data/dfs/
6.3启动(第一次启动)(不说明的都是在hadoop001上执行)
把每个zookeeper启动:zkServer.sh start (每台机器)
先全部启动JN, hadoop-daemon.sh start journalnode
然后格式化第一台的namenode:hadoop namenode -format
把data/dfs/name发送到另外两台
然后再hadoop的bin目录下执行:hdfs zkfc -formatZK
查看是否带有successful
然后启动hdfs:start-dfs.sh
启动yarn:start-yarn.sh
但是hadoop002的resourcemanager需要单独启动(hadoop001启动不了hadoop002的)
:yarn-daemon.sh start resourcemanager
6.4关闭:
先关yarn(单独关hadoop002的),再关hdfs,最后把每个zk关掉
6.5再次启动
zkServer.sh start(每台机器,而且都配置了环境变量,不然需要在zookeeper根目录下执行:bin/zkServer.sh start)
start-dfs.sh
start-yarn.sh
yarn-daemon.sh start resourcemanager(hadoop002上执行)
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
6.6监控集群
hdfs dfsadmin -report
HDFS:http://192.168.137.200:50070/
HDFS:http://192.168.137.201:50070/
ResourceManger(Active):http://192.168.137.200:8088
ResourceManger(Standby):http://192.168.137.201:8088/cluster/cluster
JobHistory:http://192.168.137.200:19888/jobhistory