Spring Cloud Sleuth Zipkin + RabbitMQ + MySQL Demo 链路追踪
1. 简介
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案。
1.1 基本术语
Spring Cloud Sleuth借鉴了Dapper的术语。
Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
Spans在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
-
cs- Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始 -
sr- Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟 -
ss- Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间 -
cr- Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间下图显示了Span和Trace在一个系统中使用Zipkin注解的过程图形化:
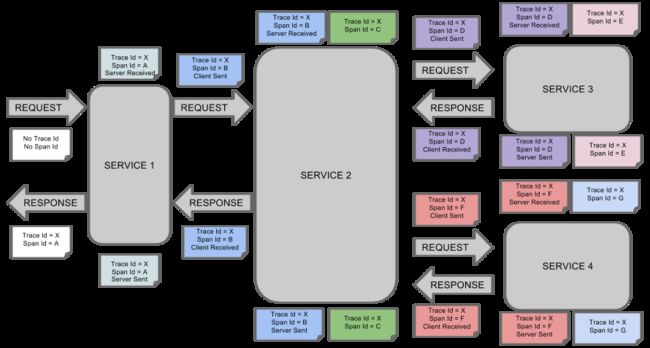
每种颜色表示一个span(有七个span-从A到G)。请考虑以下注意事项:
Trace Id = X
Span Id = D
Client Sent
该说明指出,当前span跟踪编号设定为X和span标识设置为d。此外,Client Sent事件发生了。
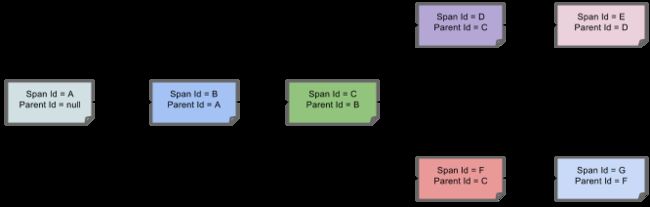
下图显示了跨度的父子关系
Zipkin 和 Config 结构类似,分为服务端 Server,客户端 Client,客户端就是各个微服务应用。
2. 搭建 Zipkin 服务端
在 Spring Boot 2.0 版本之后,官方已不推荐自己搭建定制了,而是直接提供了编译好的 jar 包。详情可以查看官网:https://zipkin.io/pages/quickstart.html
本文介绍的还是自己搭建zipkin-server,原因本人项目上是使用的spring cloud 体系,想结合eureka注册中心统一展示管理
2.1 创建 zipkin-server
引入依赖。pom文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>com.examplegroupId>
<artifactId>spring-cloud-sleuth-zipkin-demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<relativePath/>
parent>
<artifactId>server-zipkinartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>server-zipkinname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.12.2version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.12.2version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmqartifactId>
<version>2.12.2version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
<version>2.12.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
<exclusions>
<exclusion>
<artifactId>logback-classicartifactId>
<groupId>ch.qos.logbackgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.16version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
2.2 配置文件:
#配置服务及端口
server:
port: 9411 #官方用的是9411,咱们也用这个
spring:
main:
allow-bean-definition-overriding: false #zipkin启动报错 解决The bean 'characterEncodingFilter', defined in class path resource [zipkin/autoconfigure/ui/ZipkinUiAutoConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [org/springframework/boot/autoconfigure/web/servlet/HttpEncodingAutoConfiguration.class] and overriding is disabled.Action:
application:
name: server-zipkin
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/zipkin?characterEncoding=utf8&useSSL=true&verifyServerCertificate=false
username: root
password: 123456
management:
metrics:
web:
server:
auto-time-requests: false #zipkin启动报错 解决,Prometheus requires that all meters with the same name have the same set of tag keys. There is already an existing meter named 'http_server_requests_seconds' containing tag keys [exception, method, outcome, status, uri]. The meter you are attempting to register has keys [method, status, uri].
zipkin:
collector:
rabbitmq:
addresses: 192.168.41.16:5672
password: guest
username: guest
virtual-host: /
queue: zipkin
storage:
type: mysql
2.3 启动类:
@EnableZipkinServer
@SpringBootApplication
public class ServerZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ServerZipkinApplication.class, args);
}
@Bean
@Primary
public MySQLStorage mySQLStorage(DataSource datasource) {
return MySQLStorage.newBuilder().datasource(datasource).executor(Runnable::run).build();
}
}
这里注入一个DataSource,需要在数据库建几张表
SQL语句参见:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
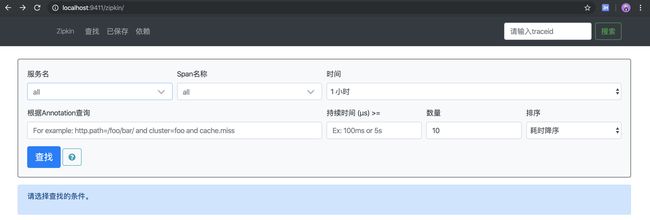
任一方式启动后,访问 http://localhost:9411,可以看到服务端已经搭建成功
3 搭建 Zipkin 客户端
创建两个服务,service-hello、service-hi,service-hello 实现一个 REST 接口 /hello,/hello/hi,该接口里调用/helloe/hi调用 service-hi 应用的接口。
3.1 创建 service-hello
3.2 引入依赖,pom 文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>com.examplegroupId>
<artifactId>spring-cloud-sleuth-zipkin-demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<relativePath/>
parent>
<groupId>com.examplegroupId>
<artifactId>service-helloartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>service-helloname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
<version>2.1.1.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
3.3 配置文件:
server:
port: 8482
spring:
application:
name: service-hello
rabbitmq:
host: 192.168.41.16
port: 5672
username: guest
password: guest
zipkin:
rabbitmq:
queue: zipkin
sleuth:
sampler:
#采样率,推荐0.1,百分之百收集的话存储可能扛不住
probability: 1.0 #Sleuth 默认采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的采样比例为: 0.1,即 10%。我们可以通过 spring.sleuth.sampler.probability 来设置,所设置的值介于 0 到 1 之间,1 则表示全部采集
3.4 启动类
@SpringBootApplication
@RestController
public class ServiceHelloApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceHelloApplication.class, args);
}
private static final Logger LOG = Logger.getLogger(ServiceHelloApplication.class.getName());
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String home(){
LOG.log(Level.INFO, "hello is being called");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
throw new RuntimeException("测试异常");
// return "hi i'm service-hello!";
}
@RequestMapping(value = "/hello/hi", method = RequestMethod.GET)
public String info(){
LOG.log(Level.INFO, "hello/hi is being called");
return restTemplate.getForObject("http://localhost:8483/hi",String.class);
}
@Autowired
private RestTemplate restTemplate;
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
4. 创建 service-hi
4.1 service-hi 的 pom.xml 文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>com.examplegroupId>
<artifactId>spring-cloud-sleuth-zipkin-demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<relativePath/>
parent>
<artifactId>service-hiartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>service-hiname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
<version>2.1.1.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
4.2 配置文件如下:
server:
port: 8482
spring:
application:
name: service-hi
rabbitmq:
host: 192.168.41.16
port: 5672
username: guest
password: guest
zipkin:
rabbitmq:
queue: zipkin
sleuth:
sampler:
#采样率,推荐0.1,百分之百收集的话存储可能扛不住
probability: 1.0 #Sleuth 默认采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的采样比例为: 0.1,即 10%。我们可以通过 spring.sleuth.sampler.probability 来设置,所设置的值介于 0 到 1 之间,1 则表示全部采集
4.3 启动类如下:
@SpringBootApplication
@RestController
public class ServiceHiApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceHiApplication.class, args);
}
private static final Logger LOG = Logger.getLogger(ServiceHiApplication.class.getName());
@Autowired
private RestTemplate restTemplate;
@Bean
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
@RequestMapping(value = "/hi", method = RequestMethod.GET)
public String info() {
LOG.log(Level.INFO, "calling trace service-hi ");
return "i'm service-hi";
}
@RequestMapping(value = "/hi/hello", method = RequestMethod.GET)
public String callHome() {
LOG.log(Level.INFO, "calling trace service-hello ");
return restTemplate.getForObject("http://localhost:8481/hello", String.class);
}
}
5. 验证
依次启动 zipkin-server、service-hello、service-hi,
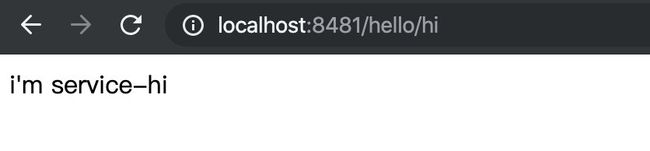
访问 http://localhost:8481/hello/hi
访问 http://localhost:8482/hi/hello
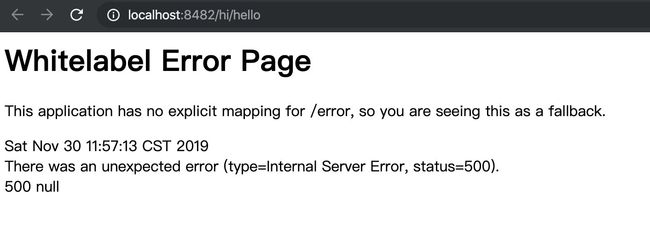
6. 特性
接口访问已经成功,此时,我们查看一下控制台的日志输出:

从上面的控制台输出内容中,我们可以看到多了一些如注意[appname,traceId,spanId,exportable] 的日志信息,而这些元素正是实现分布式服务跟踪的重要组成部分,每个值的含义如下:
-
appname:service-hello,它记录了应用的名称 -
traceId:3c15adfc71e4da46,是 Spring Cloud Sleuth 生成的一个 ID,称为 Trace ID,它用来标识一请求链路。一条请求链路中包含一个 Trace ID,多个 Span ID。
-
spanId:266c1eb7011e3baf,是 Spring Cloud Sleuth 生成的另外一个 ID,称为 Span ID,它表示一个基本的工作单元,比如发送一个 HTTP 请求。 -
exportable:true,它表示是否要将该信息输出到 Zipkin Server 中来收集和展示。
上面四个值中的 Trace ID 和 Span ID 是 Spring Cloud Sleuth 实现分布式服务跟踪的核心。在一次请求中,会保持并传递同一个 Trace ID,从而将整个分布于不同微服务进程中的请求跟踪信息串联起来。
下面我们访问 Zipkin Server 端,http://localhost:9411/
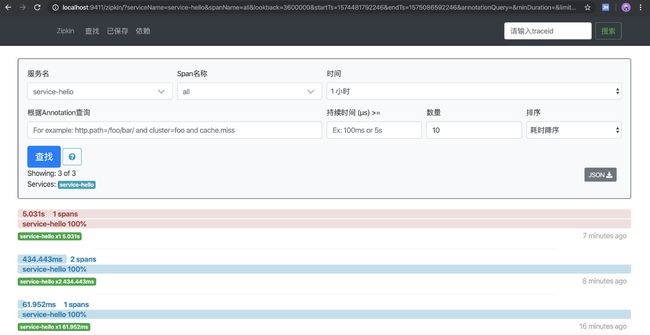
有些小伙伴第一次进来发现服务名下并没有看到我们的应用,这是为什么呢?
这是因为 Spring Cloud Sleuth 采用了抽样收集的方式来为跟踪信息打上收集标记,也就是上面看到的第四个值。为什么要使用抽样收集呢?理论上应该是收集的跟踪信息越多越好,可以更好的反映出系统的实际运行情况,但是在高并发的分布式系统运行时,大量请求调用会产生海量的跟踪日志信息,如果过多的收集,会对系统性能造成一定的影响,所以 Spring Cloud Sleuth 采用了抽样收集的方式。
既然如此,那么我们就需要把上面第四个值改为 true,开发过程中,我们一般都是收集全部信息。
Sleuth 默认采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的采样比例为: 0.1,即 10%。我们可以通过 spring.sleuth.sampler.probability 来设置,所设置的值介于 0 到 1 之间,1 则表示全部采集
本文是直接设置spring.sleuth.sampler.probability=1.0,采样率100%
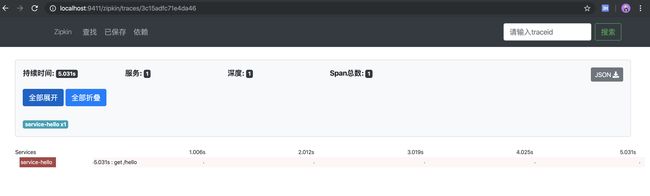
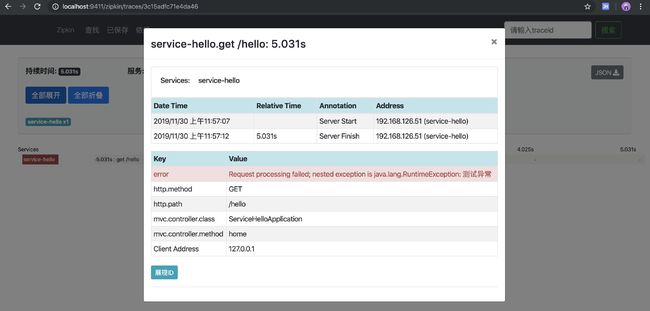
链路追踪详情
7. demo源码地址:
https://github.com/yanzhaoyao/spring-cloud-sleuth-zipkin-demo
具体的参考资料如下,推荐看spring cloud 官网的文档,下面第一个
8. 参考资料:
https://cloud.spring.io/spring-cloud-sleuth/reference/html[推荐]
https://github.com/openzipkin/zipkin/tree/master/zipkin-server[推荐]
https://blog.csdn.net/hubo_88/article/details/80878632
https://blog.csdn.net/hubo_88/article/details/80889973
https://www.jianshu.com/p/4b9bf5a311fe
https://www.jianshu.com/p/4ea093c29c0e
https://www.cnblogs.com/lifeone/p/9040336.html