高文院士:学习人工智能专业,能成为大师吗?
| 2020-04-03 15:01 |
导语:目前为止,人工智能还不是一个完整的学科

第二十届全国图象图形学学术会议(NCIG2020)将于6月28~30日在新疆乌鲁木齐市召开,大会将汇聚国内图像图形及相关领域领军人才,聚焦领域热点问题,多角度全方位洞见未来发展趋势。北京大学高文院士确认出席大会并将作题为《数字视网膜– 城市大脑从云计算走向端边云混合的体系架构》的特邀报告。
作为合作媒体,近期,AI 科技评论有幸与高文院士做了简短对话,包括三个主题,分别为:
1)对图像图形未来研究走向的判断;
2)对当下人工智能专业的看法;
3)目前在产学研结合的路上如何平衡基础研究和应用研究。
针对图像图形研究的未来走向,高文院士认为,我们做图像视频研究从一开始就做错了一点,即人的眼睛看世界并不是一帧一帧看,而是先对视觉信息进行特征提取和编码压缩,然后送到大脑;而我们目前的相机、摄像机却并不是,这是造成当前视觉数据量急剧增大,而又难以检索的主要原因。他指出,从长远来看,这种形式必然会被抛弃。
其次,针对当下广泛开设的人工智能专业,高文院士认为,社会有强烈需求,开设此类专业可以补充人才空缺;然而人工智能本身是一个交叉学科,若想在这个领域取得先进的研究成果,需要首先知道自己的“根”在哪,也即有一个作为根本的其他学科的深厚背景,否则将是无根浮萍,难以成为“大师”。
伴随着当下企业做人工智能研发进入深水区,高文院士指出,不能天真地认为企业会做基础研究,企业所做研究一定是应用研究,一定是为其产品服务的;所不同的是,这些应用研究面向的是未来五年、十年还是二十年的产品。
以下为对话内容:
1、图像视频研究,一开始我们做错了什么?
问:图像图形作为人工智能的一个重要的窗口,高老师也是这一领域的领军泰斗,能否谈下图像图形未来的研究走向?
高文:首先我要说一下为什么我要做数字视网膜。现在城市大脑把所有的注意力都放在城市云计算系统上面。而摄像头本身的功能就只是纯粹做视频压缩。或者准确来说有两类摄像头,一类只做压缩;另外一类除了压缩外,还会把人脸、车、车牌号等目标都识别出来。基本上就这两类摄像头。
基于这种摄像头所构建的「城市大脑」其实是有问题的,因为这个系统本身是一个头重脚轻的系统,它并不是一个功能搭配合理的系统。
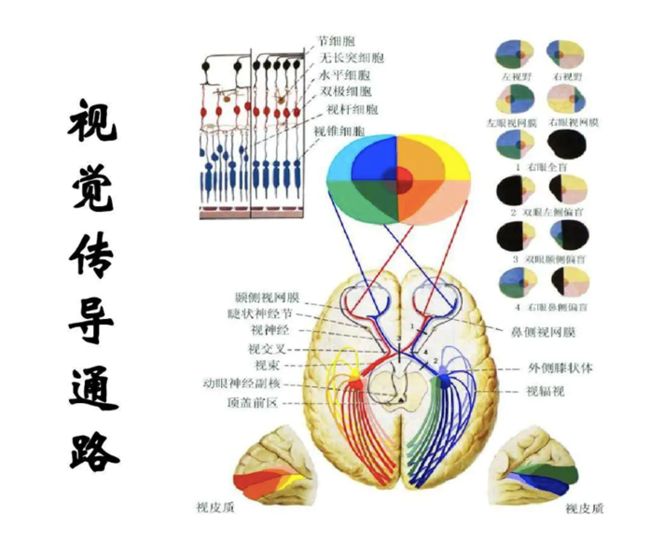
我们来看看人的识别系统。人有眼睛,眼睛后面就是视网膜,然后从视网膜到整个视觉系统中间的连接,叫做视觉通路(Visual passway)。其实视网膜收集完信息以后,视觉通道在向大脑传输信息时,做了视觉编码,这种编码和我们通常说的图像编码不一样,它叫视觉编码,视觉编码做的事情是特征抽取和特征压缩。
现在一般的图像视频分析里面只做特征抽取,所以和人的系统是不一样。
为什么我要做数字视网膜?实际上是自然界给我们提供了一个非常好的参照,就是人的视觉系统。我们就要做一个类似人的视觉系统,把它数字化,所以就叫数字化视网膜。

这个系统搭配好了以后,首先云端计算资源不需要消耗那么多,而且整个系统不管是响应速度、识别率,还是识别精度,都会比现在的系统提高很多。所以从系统优化的角度,数字视网膜模型是城市大脑进化的一个比较好的模型。
那么说到图像图形未来的研究走向,我觉得这个问题有点大,我这里仅说一点。
图像和视频本身是因为有了照相机、摄像机而产生的一个领域。但是对于照相机和摄像机的数据,我们如何使用和储存呢?
我们的思路是:摄像头采集了很多信息,而这些信息的量又太大,所以要压缩一下;另外传输、存储时应该组织一下,然后在分析的时候去抽取这些信息。
但实际上我们一开始就有一件事做错了,被照相机数字化图像的结果印到了歧路上,当然这是没有办法的,存在即合理。因为人看世界的时候,不是一帧一帧看的,但现在摄像机、照相机是按帧去采样,最后结果就产生了超大量的数据,从而给后续的数据存储、处理带来了很多问题。但如果把前面摄像机和照相机的机制给变掉,可能就会不一样了,当然这个是开脑洞的一种说法了。
但对于这个领域的研究者而言,现在还不能把前提推翻。
那么我们在现有的前提下,在有了一帧一帧的图像和视频的前提下,怎么来处理这些数据呢?现在基本上就是按数字视网膜这种思路在处理了。
目前这样的系统还会继续研究,还会变得越来越复杂,还会花很多投资在这里面。但是从长远来说,此前的那种思路可能慢慢地就会被抛弃掉。当然至于多长时间就不知道了,这可能十几年、几十年,乃至几百年后才会从根本解决。
2、学习人工智能专业,能成为大师吗?
问:在图像和视频领域,与其他学科存在很多的交叉,包括跟脑、心理学、数学等各个方面的交叉。现在人工智能在视觉领域的发展虽然看起来很蓬勃,但是未来10年后会走到什么方向上去呢?现在很多的前沿科学家们也都给出了各种各样的预期,但是对于我们学者来说,我们希望能够脚踏实地的去把这些交叉的领域给做起来,那么从您的角度上面来看,包括您提出来数字视网膜,包括现在我们在图像图形跟脑科学、心理科学的交叉,基础研究科学上可能会在哪些方面更值得我们去关注或者说去突破?
高文:目前为止,人工智能本身并不是一个完整的学科。「人工智能学科」本身这个说法是容易误导人的,因为人工智能是一个交叉学科,涉及到很多基础,包括计算机科学、数学,另外比如像脑科学、神经科学,电子学等等,它实际上是一个多学科交叉的领域。
任何一个经过这些分支领域培训的人,如果他愿意再多一点精力来学习人工智能,他就能够学会,并且能够进入人工智能领域去从事研究。
现在教育部批准成立人工智能专业,是因为人工智能这个方向比较热,很多地方、企业、国家机关需要,所以设出一个专业,专门有意识地培养这方面的人,我认为这更多的可能是从满足社会需求的角度来这样做,我认为这是无可厚非的。
但是如果你要想成为一个顶级的人工智能研究学者,直接学人工智能是成不了大家的。你要想成大家,还要从刚才说的那些具体的学科学起。比如说你如果想要基于哪个领域往别的领域去交叉,首先要把自己这个领域搞深搞透,然后再去做一些交叉的事,这就有可能成为大家。作为一个“大家”,首先要知道“根”是什么。
所以我认为直接进到人工智能学科的学生,将来很有可能像前些年的管理学本科专业出来的人一样,这些人真正去做管理学的研究往往做不好,因为管理的基础不是管理,而是各个不同的细分领域。所以从这个意义上说,做交叉研究首先要把自己最“根本”的基础打牢,然后再往其他的领域去交叉,这样才能把人工智能的研究做好。
所以教育部怎么做我都认为是可以的,有社会需求,教育机构就应该做培养人才的这种投入或引导,我觉得都是可以的,没什么问题,但是做研究就要头脑清醒一点。
3、产学研结合的路上,如何平衡好基础研究和应用研究?
问:人工智能在理论上还有很多待探索的问题,应用上也有很多需求,可以说是一个机遇和危机并存的研究领域。而现在也有很多产业介入到人工智能的科学研究上,可能会有一定的迷失,到底如何平衡好基础理论和具体应用这两个方向的研究?既能够落地,又能够在理论上取得突破,其实现在还有很长的一段路,具体要怎么走?
高文:企业一定做的是应用研究。有一些企业做纯粹自由探索的基础研究,可能是那个企业资金比较充裕比较灵活,老板愿意投资去做,这是有可能的,但是大多数企业其实还是有他自己的追求目标。
这种应用研究是分阶段,可能是5年以后要变成产品,也可能是10年或者15年、20年要出成果,这就叫应用研究。
而真正的基础研究,到底什么时候变成产品或者最后到底能不能用上,都不确定。基础研究就是要探索一些未知,回答的是“为什么”,回答完了,任务也就完成了,而不需要告诉我们说这件事有什么用,或者这件事什么时候能用。
基础研究,企业是不会真的投入去做;尽管有,那也是极少数、极个别的,那么基础研究应该是谁做?一定是大学、国家研究所去做。因为他们是由政府资助。当然以前也有很多私人基金会做基础研究,或者是有钱人的孩子自己做点探索。
所有企业做的研究都不是基础研究,而就算做应用研究,也要看他准备的是前瞻多少年的应用研究,比如像无人驾驶,就是前瞻了大概10年左右的应用研究。我觉得无人驾驶在有约束条件下,10年之内是有可能在很多地方出现的,都用起来,这是完全可能的。所谓有约束条件,就是说,不是在任何情况下都会出现,而是在某些条件下它才会出现,才可能被大量用起来。
很多企业看到10年之内可能会有市场机会,就把钱砸进去,然后投入一些人去做研究,做开发,这是可以的。但可能他们一开始把话说过头了,把这个约束条件全都给忽略了,那做着做着就完全不对了,可能根本做不出来。所以现在很多企业开始往后退,这都是很正常。
所以人工智能的基础研究应该由大学、研究机构去做。而企业做的应用研究基本上也是设定了一个定期的目标。
由中国图象图形学学会主办,新疆大学承办的第二十届全国图象图形学学术会议(NCIG 2020)将于2020年6月28-20日在新疆乌鲁木齐举办。高文院士将作为特邀讲者[16],再次为我们带来数字视网膜的最新研究报告,该会议将汇聚国内图像图形及相关领域领军人才,聚焦领域热点问题,多角度全方位洞见未来发展趋势,包含3个特邀报告,2个讲习班,4个论坛,5个竞赛,1个优秀博士论坛,多个展览,是国内图像图形领域专家学者合作交流的平台,值得期待!
NCIG 2020 官方网站:http://ncig2020.csig.org.cn

高文院士简介
高文,北京大学博雅讲席教授。1982年于哈科大获得学士学位,1985年于哈工大获得硕士学位,1988年和1991分别获得哈工大计算机应用博士学位和东京大学电子工程博士学位。1991至1996年就职于哈尔滨工业大学,1996至2006就职于中国科学院计算技术研究所,2006年2月至今就职于北京大学。IEEE Fellow、ACM Fellow、中国工程院院士。他的研究领域为多媒体和计算机视觉,包括视频编码、视频分析、多媒体检索、人脸识别、多模态接口和虚拟现实。他最常被引用的工作是基于模型的视频编码与基于特征的对象表达。他先后出版著作七本,合作发表300余篇期刊论文、700余篇国际会议论文。先后多次获得国家科技进步奖、国家技术发明奖、国家自然科学奖等学术奖励。