高性能MySQL06-查询优化(慢查询)
一、分析原因
SQL语句慢查询的原因有多种,如:
1)数据方面:
需要查询的表数据量太大导致性能下降;
是否向数据库请求了不需要的数据行或数据列;
MySQL是否在扫描额外的记录
2)SQL语句太过于冗余
3)等
下面我们列出一下分析SQL查询慢的一些方法:
1、记录慢查询日志
分析查询日志,不要直接打开慢查询日志进行分析,这样比较浪费时间和精力,可以使用pt-query-digest工具进行分析。
2、使用show profile
使用步骤:
1)开启,服务器上执行的所有语句会检测消耗的时间,存到临时表中
set profiling = 1;
2)进行需要分析的SQL查询
...
3)show profiles
4)show profile for query 临时表id
如:
mysql> set profiling = 1;
Query OK, 0 rows affected (0.00 sec)
mysql> show profiles;
Empty set (0.00 sec)
mysql> select * from a;
+------+--------+
| id | name |
+------+--------+
| 1 | nosee |
| 2 | chan |
| 3 | cheese |
| 4 | xyz |
+------+--------+
4 rows in set (0.00 sec)
mysql> show profiles;
+----------+------------+-----------------+
| Query_ID | Duration | Query |
+----------+------------+-----------------+
| 1 | 0.00054875 | select * from a |
+----------+------------+-----------------+
1 row in set (0.00 sec)
mysql> show profile for query 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000063 |
| checking permissions | 0.000013 |
| Opening tables | 0.000050 |
| System lock | 0.000018 |
| init | 0.000023 |
| optimizing | 0.000007 |
| statistics | 0.000018 |
| preparing | 0.000010 |
| executing | 0.000004 |
| Sending data | 0.000104 |
| end | 0.000006 |
| query end | 0.000004 |
| closing tables | 0.000008 |
| freeing items | 0.000196 |
| logging slow query | 0.000022 |
| cleaning up | 0.000006 |
+----------------------+----------+
16 rows in set (0.00 sec)
3、使用show status
show status会返回一些计数器,show global status 查看服务器级别的所有计数。有时根据这些计数,可以猜测出哪些操作代价较高或消耗时间多。
4、使用explain
explain命令用于分析单条SQL语句,是查看优化器如何决定执行查询的主要方法。
如:
mysql> explain select id from a where id =3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: a
type: ref
possible_keys: id
key: id
key_len: 5
ref: const
rows: 1
Extra: Using where; Using index
1 row in set (0.00 sec)
关于EXPLAIN更详细的内容请查看下一篇文章。
二、查询执行原理
当希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的。
当我们向MySQL发送一个请求时,MySQL到底做了些什么,下面我们通过一个简单的图解来进行分析:
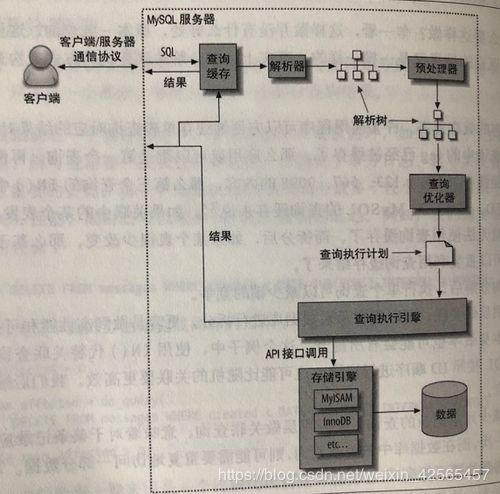
1)客户端发送一条查询给服务器。
2)服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段。
3)服务器进行SQL解析、预处理,再由优化器生成对应的执行计划。
4)MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5)将结果返回给客户端。
上面的每一步都比想象的要复杂,这里将不深入讨论。
三、优化查询过程中的数据访问
1、定位问题
访问数据太多导致查询性能下降。
确定应用程序是否在检索大量超过需要的数据,可能是太多行或列。确认MySQL服务器是否在分析大量不必要的数据行。
2、避免使用如下SQL语句
1)查询不需要的数据,使用limit解决
2)多表关联返回全部列,指定如A.id, A.name, B.age
3)总是取出全部列,SELECT *会让优化器无法完成索引覆盖扫描的优化
4)重复查询相同的数据,可以缓存数据,下次直接读取缓存
3、是否在扫描额外的记录
使用explain来进行分析,如果发现查询需要扫描大量的数据但只返回少数的行,可以通过如下技巧去优化:
1)使用索引覆盖扫描,把所有用的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果
2)改变数据库和表的结构,修改数据表范式
3)重写SQL语句,让优化器可以以更优的方式执行查询
四、优化长难的查询语句
MySQL内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多。使用尽可能少的查询是最好的,但有时将一个大的查询分解为多个小的查询也是很有必要的。
1、切分查询
将一个大的查询分为多个小的相同的查询。如一次性删除1000万的数据,要比一次删除1万暂停一会的方案更加损耗服务器开销。
2、分解关联查询
1)可以将一条关联语句分解成多条SQL来执行
2)执行单个查询可以减少锁的竞争
3)在应用层做关联可以更容易对数据库进行拆分
五、优化特定类型的查询语句
1、优化count()查询
1)count(*)中的*会忽略所有的列,直接统计所有列数,因此不要使用count(列名)。MyISAM中,没有任何WHERE条件的count(*)非常快。
2)可以使用explain查询近似值,用近似值替代count(*)
3)增加汇总表
4)使用缓存
2、优化关联查询
1)确定ON或USING子句的列上有索引
2)确保GROUP BY和ORDER BY中只有一个表中的列,这样MySQL才有可能使用索引
3、优化子查询
尽可能使用关联查询来替代
4、优化GROUP BY和DISTINCY
1)这两种查询均可使用索引来优化,是最有效的优化方法
2)关联查询中,使用标识列进行分组的效率会更高
3)如果不需要ORDER BY,进行GROUP BY时使用ORDER BY NULL,MySQL不会进行文件排序
4)WITH ROLLUP超级聚合,可以挪到应用程序处理
5、优化LIMIT分页
LIMIT偏移量大的时候,查询效率较低。可以记录上次查询的最大ID,下次查询时直接根据该ID来查询。
6、优化UNION查询
UNION ALL的效率高于UNION。
经典实例
1、请简述项目中优化SQL语句执行效率的方法,从哪些方面,SQL语句性能如何分析?
考官考点:
1)查找分析查询速度慢的原因
2)优化查询过程中的数据访问
3)优化长难的查询语句
4)优化特定类型的查询语句
对于此类问题,先说明如何定位低效率SQL语句,然后根据SQL语句可能低效的原因做排查,先从索引着手,如果索引没问题,考虑以上几个方面:数据访问的问题、长难查询句的问题、还是一些特定类型优化的问题,逐步排除。
参考
1、《高性能MySQL》 [美]Baron Scbwartz, Peter Zaitsev, Vadim Tkacbenko 著
2、 蹲厕所的熊:MySQL索引原理以及慢查询优化
3、 蹲厕所的熊:MySQL优化之EXPLAIN详解