记一次超万亿规模的hadoop NameNode性能故障排查过程
近日客户反馈录信数据库LSQL突然性能变差,之前秒级响应的数据查询与检索,现在却总是在“转圈”,卡住不动了。因为是突然发生的现象,现场先排除了业务变动,并未发现问题。作为数据库厂家,我立马奔赴现场,万亿级别大项目不敢小觑。
先来介绍一下该平台架构,底层采用hadoop进行分布式存储,中间数据库采用的录信lsql,数据实时导入采用kafka进行。每天的数据规模是500亿,数据存储周期为90天,一共有4000多张数据表,其中最大的单表数据规模近2万亿条记录,总数据规模将近5万亿,存储空间占8PB。
数据平台支撑的基本使用主要包括数据的全文检索、多维查询,以及地理位置检索、数据碰撞等操作。也会有部分业务会进行数据的统计和分析,会有极少量的数据导出与多表关联操作。
-
去之前信心满满
创业之前在腾讯做Hermes系统,每日接入的实时数据量就已经达到了3600亿/天,之后更是达到了每日近万亿条数据的实时导入。因为有了处理超大集群的经历,难免有些自负。面对当前每日500-1000亿规模的系统,完全没觉得自己会搞不定。
去之前跟现场要了一些日志和jstack,初步定位是hadoop NameNode的瓶颈,而NN的优化我们此前也做了很多次。所以自信满满出发,扬言一天搞定问题,两天必回,决不拖3.0版本开发日程的后腿。
下图为当时堆栈的分析情况,估计在座诸位看了都会信心满满,这很明显就是hadoop卡顿。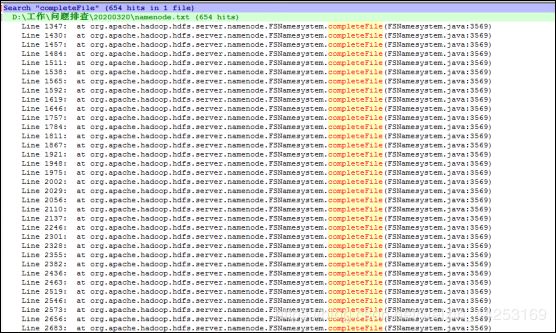
-
第一天:调整log4j---有效果但依然卡
我到现场后第一件事情就是不断的抓 hadoop Namenode的堆栈Jstack。从中得到的结论是问题确实是卡顿在NN上。此处NN是一个全局锁,所有的读写操作都在排序等待,详情如下图所示: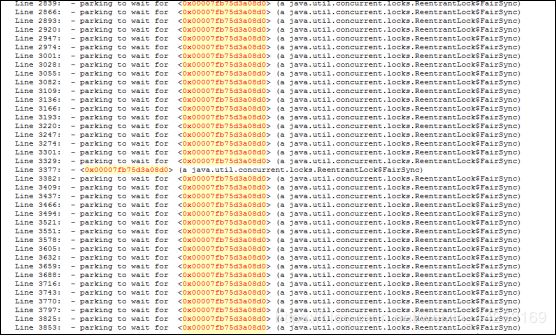
1.卡在哪里
这个锁的等待个数竟然长达1000多个,不卡才怪呢,我们再细看一下,当前拥有这个锁的线程在做什么?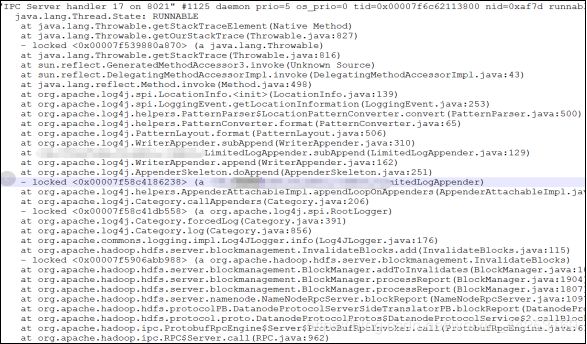
2.问题分析
很明显,在记录log上存在瓶颈,阻塞的时间太久。
- 记录的log4j不应该加【%L】,它会创建Throwable对象,而这个在java里是一个重对象。
- 日志记录太频繁,刷盘刷不动。
- log4j有全局锁,会影响吞吐量。
3.调整方案
客户的hadoop版本采用的是2.6.0版本,该版本的hadoop,在日志处理上存在诸多问题,故我们将官方明确表示存在问题的patch打了进来
https://issues.apache.org/jira/browse/HDFS-8245 因日志原因导致nn慢
https://issues.apache.org/jira/browse/HDFS-7503 将日志记录到锁外,避免卡锁
https://issues.apache.org/jira/browse/HDFS-7213 processIncrementalBlockReport 导致的记录日志问题,严重影响NN性能
禁用namenode所有info级别的日志
观察发现当有大量日志输出的时候,全局锁会阻塞NN。
目前修改方式是屏蔽到log4j的日志输出,禁用namenode所有info级别的日志。
log4j 的日志输出去掉【%L】参数
这个参数会为了得到行号而创建new Throwable对象,这个对象对性能影响很大,大量创建会影响吞吐量。
启用异步审计日志
dfs.namenode.audit.log.async 设置为true,将审计日志改为异步。
4.优化效果
优化之后,确实因log4j导致的卡顿问题不存在了,但hadoop的吞吐量依然卡,仍旧卡在lock上
-
第二天上午:优化du
1.在解决了log4j的问题后,继续抓jstack,抓到如下位置: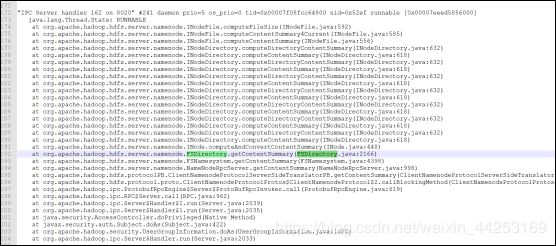
2.通过代码进行分析,发现确实此处有锁,证实此处会引起所有访问阻塞: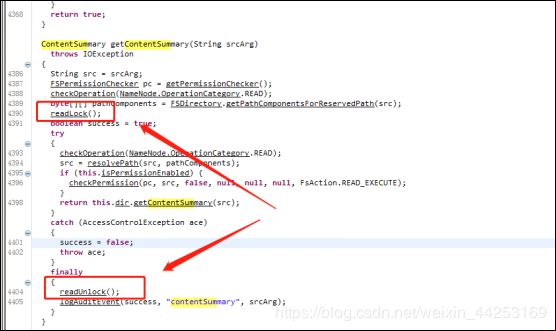
3.继续深入研读代码,发现受如下参数控制:
(2.6.5版本这个默认值是5000,已经不存在这个问题了)
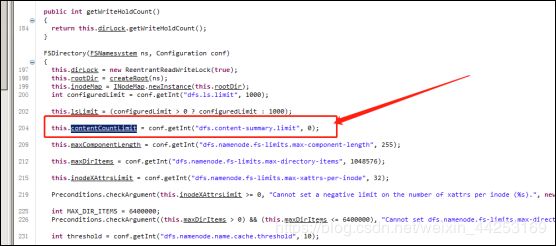
这个参数的核心逻辑是,如果配置上大于零的值,它会间隔一定文件数量,释放锁,让别的程序得以继续执行,该问题只会在hadoop2.6.0的版本里存在,之后的版本里已经对此做了修复。
4.解决办法
- 打上官方patch https://issues.apache.org/jira/browse/HDFS-8046
- lsql内部移除所有关于hadoop du的使用
5.为什么要打patch
2.6.5版本中,可以自己定义休眠时间,默认休眠时间为500ms,而2.6.0休眠时间为1ms,我担心太短,会出现问题。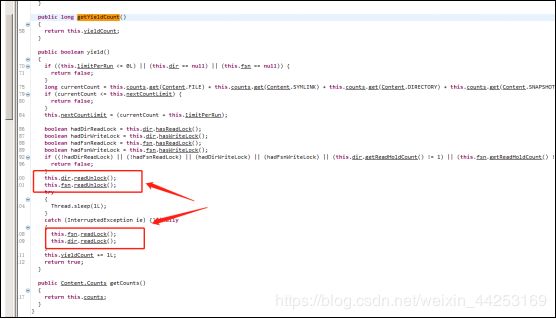
-
第二天下午:解决所有能抓到的卡顿
继续按照原先思路,排查所有的jstack 。将所有涉及卡顿的地方都一一解决掉,至此hadoop通过jstack已经抓不到任何的活动线程,但是依然卡顿在读写锁的切换上,这说明:
1:namenode内部的每个函数已经最优,jstack基本抓不到了。
2:堆栈调用只能看到近1000个读写锁在不断切换,说明nn的请求并发非常高,多线程之间锁的上下文切换已经成为了主要瓶颈。
所以当下主要思路应该落在如何减少nn的调用频率上面。
-
第三天 :想尽一切办法,减少nn的请求频率,熬到凌晨5点,黔驴技穷
1.启用录信数据库lsql的不同表不同分片功能
考虑到现场有4000多张表,每张表有1000多个并发写入分片,有可能是同时写入的文件数太多,导致的nn请求频率太高,故考虑将那些小表,进行分片合并,写入的文件数量少了,请求频率自然而然就降低了。
2.与现场人员配合,清理不必要的数据,减少hadoop集群的压力。清理后hadoop集群的文件块数由将近2亿,降低到1.3亿,清理力度足够大。
3.调整一系列与nn有关交互的心跳的频率:如blockmanager等相关参数。
4.调整nn内部锁的类型:由公平锁调整为非公平锁。
本次调整涉及的参数有:
1) dfs.blockreport.intervalMsec 由21600000L调整为259200000L (3天),全量心跳
2) dfs.blockreport.incremental.intervalMsec 增量数据心跳由0改为300,尽量批量一次上报 (老版本无该参数)
3) dfs.namenode.replication.interval 由3秒调整为60秒,减少心跳频率
4) dfs.heartbeat.interval 心跳时间由默认3秒调整为60秒,减少心跳频率
5) dfs.namenode.invalidate.work.pct.per.iteration 由0.32调整为0.15 (15%个节点),减少扫描节点数量
本次调整涉及的堆栈:
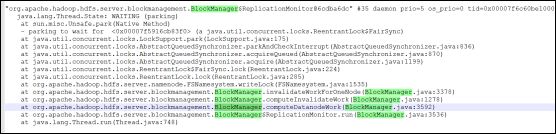
最终结果卡顿问题依然存在。本人已经黔驴技穷,人已经懵了,不知道该如何处理。
-
第四天白天:差一点就放弃
第二天早上,跟公司和客户汇报排查具体情况,也直接说了没有任何的思路。希望启用B方案:
1:启用hadoop联邦方案,靠多个namenode解决当下问题。
2:立即修改录信lsql数据库,在一个lsql数据库内适配hadoop多集群方案,也就是搭建两个完全一样的集群,录信数据库启动600个进程,300个进程请求旧集群,300个进程分流到新集群,以达到减轻压力的目的。
家里(公司)的意见是先回去睡觉,头脑清醒时再做决定。
客户这边也建议继续排查,因为系统已经稳定运行一年多了,没道理突然就不行了,还是希望深入研究一下。
回酒店睡觉~~~~~
睡醒给老同事hadoop大牛高高打了个电话,高高是我们组专门负责hdfs的(腾讯内部分工很明确,不像我出来创业啥都要搞),他对hadoop可谓精通,而且上万台大集群的优化经验,可遇而不可求,我想如果他也不能点播一二,恐怕就没人搞得定了,我也不必白费力气。
高高首先询问了集群的基本情况,并给我多项有效建议。最让我振奋的是根据高高的分析,我们的集群绝对没有达到性能的上限。
-
第四天晚上:对调用nn的锁的每个函数进行调用次数和调用时间分析
这次没有直接看jmx信息,担心不准确。采用的是btrace这个工具,排查具体是哪个线程频繁给nn加锁,导致nn负载如此之高。
花费了三个小时分析,最终令人惊喜的是发现processIncrementalBlockReport这个线程请求频率非常高,远远高于其他线程。而这个线程不是datanode (dn)节点增量心跳的逻辑吗?为什么频率如此之高?心跳频率我不是都改掉了吗?难道都没生效么?
仔细查看hadoop代码,发现这个逻辑确实有问题,每次写数据和删数据都会立即调用,而我设置的那些心跳参数在客户的这个版本的hadoop集群里并没有这方面优化,设置了也没用,于是紧急在网上寻找patch的方法,最终找到了这个,它不仅仅解决了心跳频率的问题,还解决了加锁频率问题,通过减少锁的使用次数,从而减少上下文切换的次数,进而提升nn的吞吐量。
迅速打上此patch, 明显发现nn吞吐量上来了,而且不仅仅是访问nn不卡了,实时kafka的消费速度也一下子由原先的每小时处理40亿,上升至每小时处理100亿,入库性能也跟着翻倍。打上patch后,此问题得到了根本的解决。
究其根本原因在于HDFS NameNode内部的单一锁设计,使得这个锁显得极为的“重”。持有这个锁需要付出的代价很高。每个请求需要拿到这个锁,然后让NN 去处理这个请求,这里面就包含了很激烈的锁竞争。因此一旦NN的这个锁被一些大规模的导入/删除操作,容易使NameNode一下子处理大量请求,其它用户的任务会马上受到影响。这次patch的主要作用就是增量汇报的锁修改为异步的锁——让删除、上报等操作不影响查询。
具体详细描述与改法参考这里:
https://blog.csdn.net/androidlushangderen/article/details/101643921
-
最后的总结
1:不要轻言放弃
如果这次不是客户与家里的坚持,要排查出具体原因,可能我就采用备选方案了。
2:最最重要的建议,千万不要使用hadoop2.6.0这个版本!!!
用hadoop官方的话来讲,别的版本都是存在a few of bug ,而这个版本存在a lot of bug ,所以回去后第一件事要督促客户尽快升级换版本。
3:为什么最近才出现这个状况,之前没事
涉及的具体原因:
删除了大量文件,造成hadoop压力增大
- 近期硬盘快要满了,集中清理了一批数据
- 最近hadoop不稳定,集中释放了一大批文件。
近期明显的日常数据量暴增
对hadoop调优后,重入数据,按日志进行数据条数统计,最近的数据规模增加很多。
此前消费没有积压,这次积压了很多条
本次调优过程中,由于数据积压了很多天,导致kafka一直在满速消费数据。而在满速消费的情况下,会对nn造成较大的冲击。
为什么快照和mover会对hadoop造成冲击
- 清理快照的时候,会释放大量的数据块,造成数据的删除。
- mover会新增大量的数据块,也会删除大量的ssd上的文件块。且因节点数很多,心跳频繁,瞬时都进行processIncrementalBlockReport对NN造成较大的压力导致。
一定要了解的hadoop原理,这也是本次hadoop调优的关键点:
- 当我们在HDFS中删除文件时:namenode只是把目录入口删掉,然后把需要删除的数据块记录到pending deletion blocks列表。当下一次datanode向namenode发送心跳时,namenode再把删除命令和这个列表发送到datanode端,所以这个pending deletion blocks列表很长很长,导致了timeout。
- 当我们导入数据时:客户端会将数据写入到datanode里,而datanode在接到数据块后,会立即调用processIncrementalBlockReport给NN汇报,写入数据量越多,越频繁,机器数量越多,进程越多,调用NN就会越频繁。所以本次的异步锁patch,在这里才会有效果。
