Spark 常用算子详解(转换算子、行动算子、控制算子)
Spark简介
Spark是专为大规模数据处理而设计的快速通用的计算引擎;
Spark拥有Hadoop MapReduce所具有的优点,但是运行速度却比MapReduce有很大的提升,特别是在数据挖掘、机器学习等需要迭代的领域可提升100x倍的速度:
- Spark是基于内存进行数据处理的,MapReduce是基于磁盘进行数据处理的;
- Spark中具有DAG有向无环图,DAG有向无环图在此过程中减少了shuffle以及落地磁盘的次数;
Spark流程
- Spark Application的运行环境:创建SparkConf对象
-
- 可以设置Application name;
- 可以设置运行模式及资源需求;
- 创建SparkContext对象;
-
- SparkContext向资源管理器申请运行Executor资源,并启动StandaloneExecutorbackend;
- Executor向SparkContext申请Task;
- SparkContext将程序分发给Executor;
- SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行;
- Task在Excutor上运行,运行完释放所有的资源;
- 基于Spark的上下文创建一个RDD,对RDD进行处理;
- 应用程序中y有Action累算子来触发Transformation类算子执行;
- 关闭Spark上下文对象SparkContext;
value 类型
| 细类型 | 算子 |
|---|---|
| 输入分区与输出分区一对一型 | map flatMap mapPartitions glom |
| 输入分区与输出分区多对一型 | union cartesain |
| 输入分区与输出分区多对多型 | groupBy |
| 输出分区为输入分区子集型 | filter distinct substract sample takeSample |
| Cache型 | cache persist |
key-value类型
| 细类型 | 算子 |
|---|---|
| 输入分区与输出分区一对一 | mapValues |
| 对单个RDD或两个RDD聚集 | 单个RDD聚集: combineByKey reduceByKey partitionBy; 两个RDD聚集: Cogroup |
| 连接 | join leftOutJoin和 rightOutJoin |
Action算子
| 细类型 | 算子 |
|---|---|
| 无输出 | foreach |
| HDFS | saveAsTextFile saveAsObjectFile |
| Scala集合和数据类型 | collect collectAsMap reduceByKeyLocally lookup count top reduce fold aggregate |
转换算子(Transformations)
不触发提交作业,只是完成作业中间过程处理;Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。Transformation参数类型为value或者key-value的形式;
转换算子是延迟执行的,也叫懒加载执行
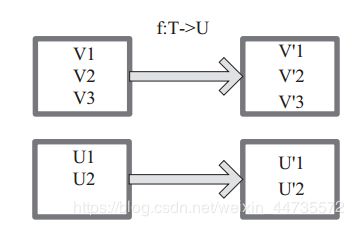
map
将原来RDD的每个数据通过map中的用户自定义函数映射为一个新的元素,源码中map算子相当于初始化一个RDD --------- f(x)=x -> y
- scala源码
def map[U: ClassTag](f: T => U): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF)) }
flatMap
将原来 RDD 中的每个元素通过函数 f 转换为新的元素,并将生成的 RDD 的每个集合中的元素合并为一个集合,内部创建 FlatMappedRDD(this,sc.clean(f))。 ------ f: T => TraversableOnce[U]
-
scala源码
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF)) } -
例子
lines.flatMap{lines => { lines.split(" ")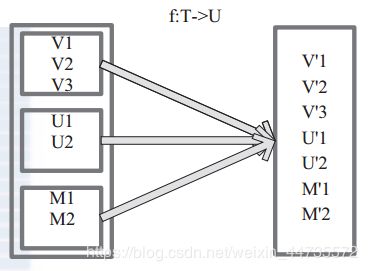
mapPartitions
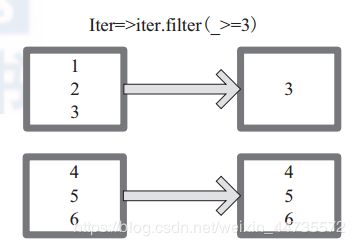
mapPartitions 函 数 获 取 到 每 个 分 区 的 迭 代器,在 函 数 中 通 过 这 个 分 区 整 体 的 迭 代 器 对整 个 分 区 的 元 素 进 行 操 作。 内 部 实 现 是 生 成 -------f (iter)=>iter.f ilter(_>=3)
-
scala源码
def filter(f: T => Boolean): RDD[T] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[T, T]( this, (context, pid, iter) => iter.filter(cleanF), preservesPartitioning = true) }
glom
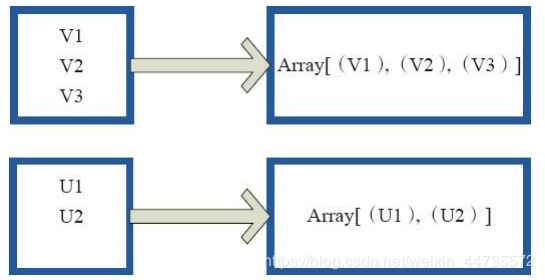
glom函数将每个分区形成一个数组,内部实现是返回的GlommedRDD。 图4中的每个方框代表一个RDD分区。图4中的方框代表一个分区。 该图表示含有V1、 V2、 V3的分区通过函数glom形成一数组Array[(V1),(V2),(V3)]
-
scala源码
def glom(): RDD[Array[T]] = withScope { new MapPartitionsRDD[Array[T], T](this, (context, pid, iter) => Iterator(iter.toArray)) }
union
使用 union 函数时需要保证两个 RDD 元素的数据类型相同,返回的 RDD 数据类型和被合并的 RDD 元素数据类型相同,并不进行去重操作,保存所有元素。如果想去重可以使用 distinct()(并集)
-
scala源码
def union(other: RDD[T]): RDD[T] = withScope { sc.union(this, other) }

cartesian
对 两 个 RDD 内 的 所 有 元 素 进 行 笛 卡 尔 积 操 作。 操 作 后, 内 部 实 现 返 回CartesianRDD。图6中左侧大方框代表两个 RDD,大方框内的小方框代表 RDD 的分区。右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。图6中的大方框代表RDD,大方框中的小方框代表RDD分区。
-
scala源码
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope { new CartesianRDD(sc, this, other) }
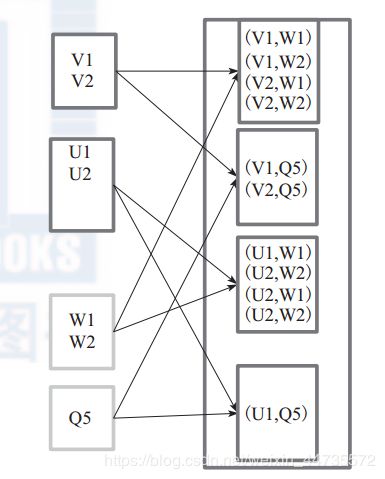
groupBy
将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
函数实现如下:
1)将用户函数预处理:
val cleanF = sc.clean(f)
2)对数据 map 进行函数操作,最后再进行 groupByKey 分组操作。
this.map(t => (cleanF(t), t)).groupByKey(p)
-
scala源码
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope { groupBy[K](f, defaultPartitioner(this)) }
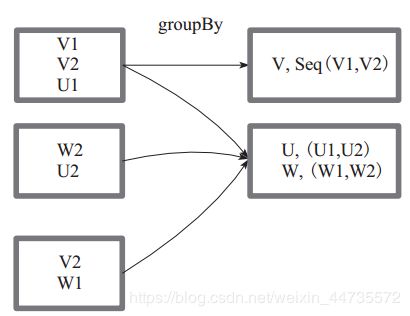
distinct
对数据进行去重
-
scala源码
/** * Return a new RDD containing the distinct elements in this RDD. */ def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1) } /** * Return a new RDD containing the distinct elements in this RDD. */ def distinct(): RDD[T] = withScope { distinct(partitions.length) }
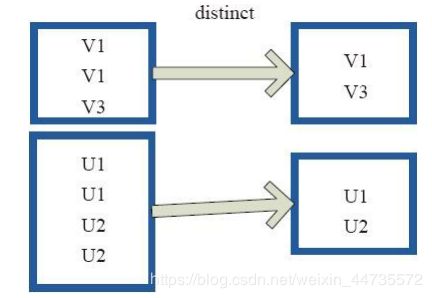
subtract
subtract相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素;
-
scala源码
/** * Return an RDD with the elements from `this` that are not in `other`. * * Uses `this` partitioner/partition size, because even if `other` is huge, the resulting * RDD will be <= us. */ def subtract(other: RDD[T]): RDD[T] = withScope { subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.length))) } /** * Return an RDD with the elements from `this` that are not in `other`. */ def subtract(other: RDD[T], numPartitions: Int): RDD[T] = withScope { subtract(other, new HashPartitioner(numPartitions)) } /** * Return an RDD with the elements from `this` that are not in `other`. */ def subtract( other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope { if (partitioner == Some(p)) { // Our partitioner knows how to handle T (which, since we have a partitioner, is // really (K, V)) so make a new Partitioner that will de-tuple our fake tuples val p2 = new Partitioner() { override def numPartitions: Int = p.numPartitions override def getPartition(k: Any): Int = p.getPartition(k.asInstanceOf[(Any, _)]._1) }
sample
sample 将 RDD 这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。内部实现是生成 SampledRDD(withReplacement, fraction, seed)。
函数参数设置:
withReplacement=true,表示有放回的抽样。
withReplacement=false,表示无放回的抽样。
- scala源码
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = {
require(fraction >= 0,
s"Fraction must be nonnegative, but got ${fraction}")
withScope {
require(fraction >= 0.0, "Negative fraction value: " + fraction)
if (withReplacement) {
new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)
} else {
new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)
}
}
}
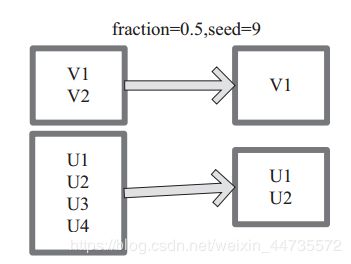
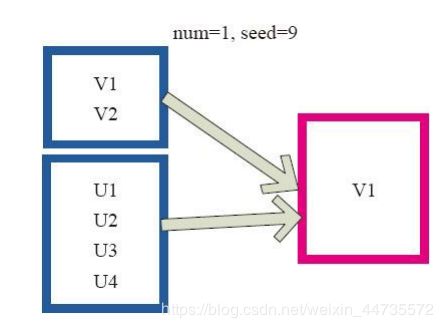
takeSample
takeSample()函数和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行Collect(),返回结果集为单机的数组
- scala源码
//返回集为数组
def takeSample(
withReplacement: Boolean,
num: Int,
seed: Long = Utils.random.nextLong): Array[T] = withScope {
val numStDev = 10.0
require(num >= 0, "Negative number of elements requested")
require(num <= (Int.MaxValue - (numStDev * math.sqrt(Int.MaxValue)).toInt),
"Cannot support a sample size > Int.MaxValue - " +
s"$numStDev * math.sqrt(Int.MaxValue)")
if (num == 0) {
new Array[T](0)
} else {
val initialCount = this.count()
if (initialCount == 0) {
new Array[T](0)
} else {
val rand = new Random(seed)
if (!withReplacement && num >= initialCount) {
Utils.randomizeInPlace(this.collect(), rand)
} else {
val fraction = SamplingUtils.computeFractionForSampleSize(num, initialCount,
withReplacement)
var samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()
// If the first sample didn't turn out large enough, keep trying to take samples;
// this shouldn't happen often because we use a big multiplier for the initial size
var numIters = 0
while (samples.length < num) {
logWarning(s"Needed to re-sample due to insufficient sample size. Repeat #$numIters")
samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()
numIters += 1
}
Utils.randomizeInPlace(samples, rand).take(num)
}
}
}
}
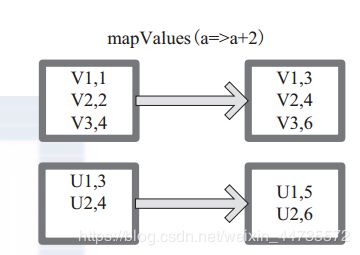
mapValues
针对(key, Value)型数据中的value进行map操作,而不对key进行处理
- scala源码
/**
* Pass each value in the key-value pair RDD through a map function without changing the keys;
* this also retains the original RDD's partitioning.
*/
def mapValues[U](f: V => U): RDD[(K, U)] = self.withScope {
val cleanF = self.context.clean(f)
new MapPartitionsRDD[(K, U), (K, V)](self,
(context, pid, iter) => iter.map { case (k, v) => (k, cleanF(v)) },
preservesPartitioning = true)
}
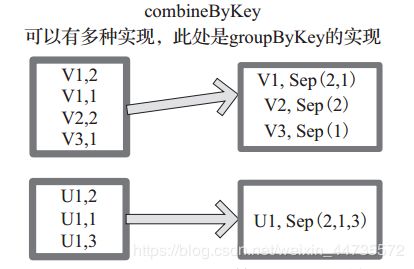
combineByKey
- scala源码
def combineByKey[C](
createCombiner: V => C, //C不存在的情况下,比如通过V创建seq C
mergeValue: (C, V) => C, //当C已经存在的情况下需要merge,比如把item V加入到seq C中,或者叠加
mergeCombiners: (C, C) => C, //合并两个C
partitioner: Partitioner, //Partitioner,Shuffle时需要的Partitioner
mapSideCombine: Boolean = true, //为了减小传输量,很多 combine 可以在 map端先做,比如叠加,可以先在一个 partition 中把所有相同的 key 的 value 叠加,再 shuff le。
//传输需要序列化,用户可以自定义序列化类
serializer: Serializer = null): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners,
partitioner, mapSideCombine, serializer)(null)
}
reduceByKey
reduceByKey是比combineByKey更简单的一种情况,只是两个值合并成一个值
-------- *(Int,Int V) >> (Int, IntC)*
- scala源码
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with numPartitions partitions.
*/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope {
reduceByKey(new HashPartitioner(numPartitions), func)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
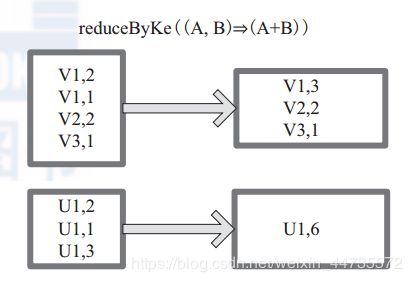
partitionBy
partitionBy函数对RDD进行分区操作;------ partitionBy(partitioner:Partitioner)
- scala源码
/**
* Return a copy of the RDD partitioned using the specified partitioner.
*/
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}
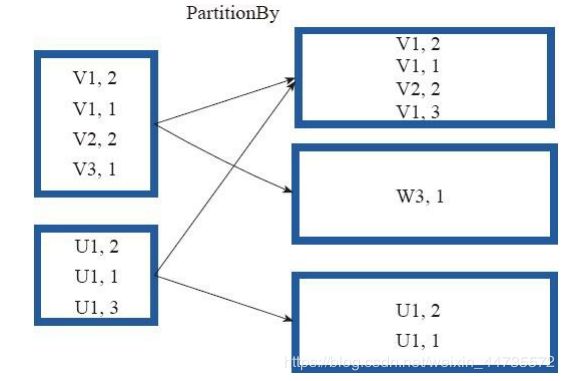
cogroup
cogroup函数将两个RDD进行协同划分,对两个RDD中的key-valuel类型的元素,每个RDD相同key的元素风别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器
- scala源码
def cogroup[W1, W2, W3](other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)],
partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other1, other2, other3), partitioner)
cg.mapValues { case Array(vs, w1s, w2s, w3s) =>
(vs.asInstanceOf[Iterable[V]],
w1s.asInstanceOf[Iterable[W1]],
w2s.asInstanceOf[Iterable[W2]],
w3s.asInstanceOf[Iterable[W3]])
}
}
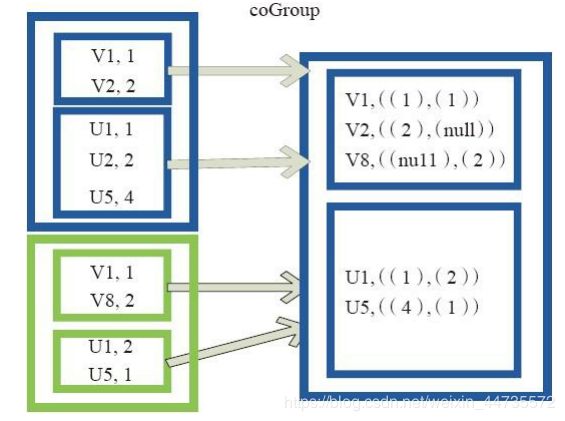
join
join 对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
- scala源码
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
sortyByKey(sortBy)
作用再(Key, Value)格式的数据上,根据Key进行升序或降序排序
- scala源码
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
Action算子(行动算子)
本质上在Action算子中通过SparkContext触发SparkContext提交job作业。Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
foreach
foreach对RDD中的每个元素都应用f函数操作,不返回RDD和Array,而返回Uint;(遍历)
- scala源码
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}

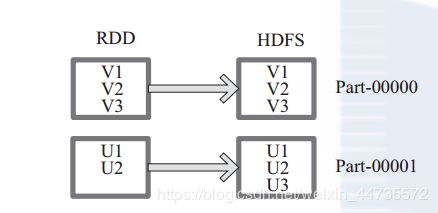
saveAsTextFile
函数将数据输出,存储到HDFS的制定目录下
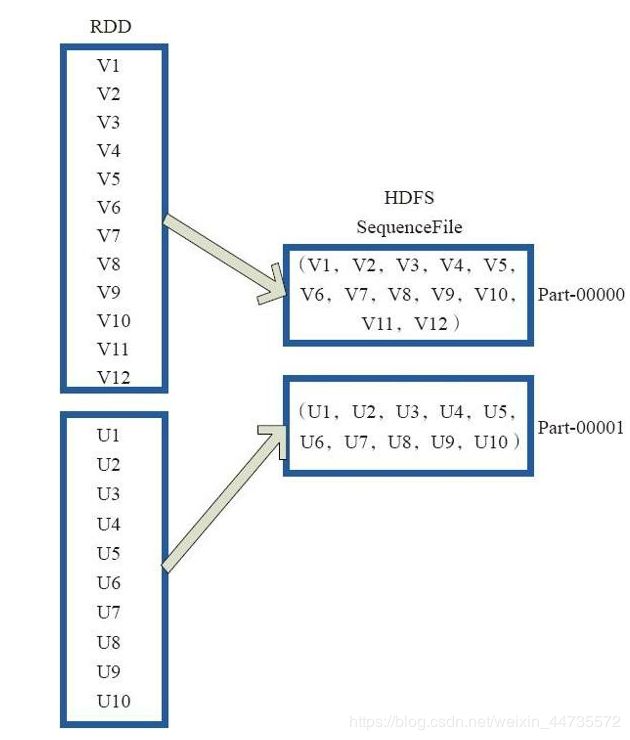
saveAsObjectFile
将风趣中的每10个元素组成一个Array,然后将这个Array序列化,映射为Null,BytesWritable(Y)的元素,写入HDFS为SequenceFile的格式;
map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x))))
colloect
相当于toArray,collect将分布式的RDD返回为一个单机的scala Array数组,在这个数组上运用scala的函数式操作;
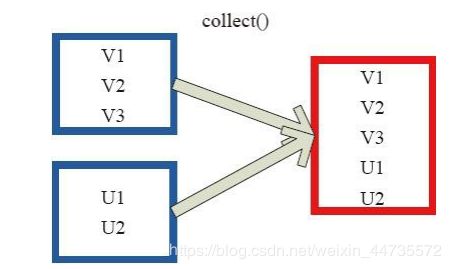
左侧方框代表 RDD 分区,右侧方框代表单机内存中的数组。通过函数操作,将结果返回到 Driver 程序所在的节点,以数组形式存储。
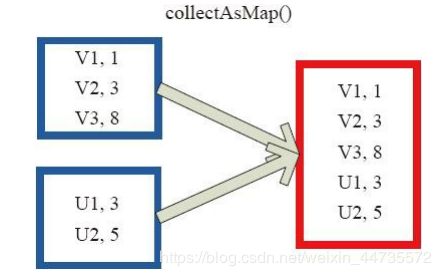
collectAsMap
collectAsMap对(K,V)型的RDD数据返回一个单机HashMap;
对于重复K的RDD元素,后面的元素覆盖前面的元素
lookup
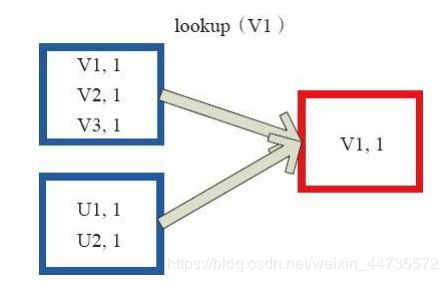
Lookup函数对(Key,Value)型的RDD操作,返回指定Key对应的元素形成的Seq。 这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。 如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。 ------- lookup(key:K):Seq[V]
count
count(计数器)返回整个RDD的元素个数
defcount():Long=sc.runJob(this,Utils.getIteratorSize_).sum

top
top可返回最大的k个元素
top(num:Int)(implicit ord:Ordering[T]):Array[T]
- top返回最大的k个元素。
- take返回最小的k个元素。
- takeOrdered返回最小的k个元素,并且在返回的数组中保持元素的顺序。
- first相当于top(1)返回整个RDD中的前k个元素,可以定义排序的方式Ordering[T],返回的是一个含前k个元素的数组.
reduce
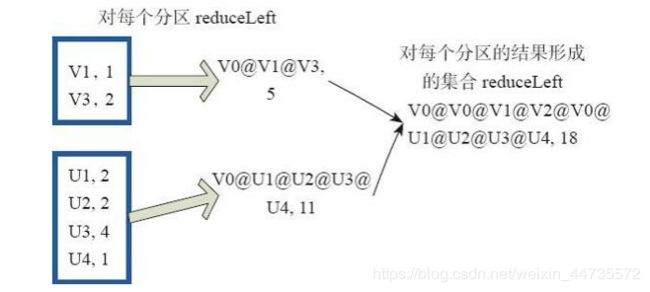
reduce函数相当于对RDD中的元素进行reduceLeft函数的操作; ---- Some(iter.reduceLeft(cleanF))
reduceLeft先对两个元素

fold
fold和reduce的原理相同,但是与reduce不同,相当于每个reduce时,迭代器取的第一个元素是zeroValue;
控制算子
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系;
cache
cache默认将RDD的数据持久化到内存中,相当与persist(MEMORY_ONLY)函数的功能;
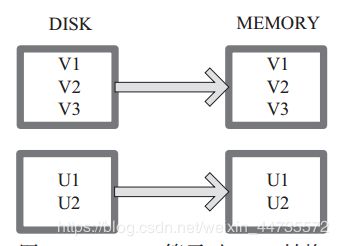
chche () = persist()=persist(StorageLevel.Memory_Only)
persist
可以指定持久话的级别,最常用的是MEMORY_ONLTY和MEMORY_AND_DISK;"_2"表示副本数;
持久化有如下级别:

cache和persist的注意事项
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition
- cache和persist算子后不能立即紧跟action算子。
checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系
-
checkpoint 的执行原理:
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
-
优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝导HDFS上就可以,省去重新计算这一步;
例如:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("checkpoint");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setCheckpointDir("./checkpoint");
JavaRDD parallelize = sc.parallelize(Arrays.asList(1,2,3));
parallelize.checkpoint();
parallelize.count();
sc.stop();