自动驾驶激光雷达物体检测技术
Lidar Obstacle Detection
Github: https://github.com/williamhyin/SFND_Lidar_Obstacle_Detection
Email: [email protected]
知乎专栏: 自动驾驶全栈工程师
Lidar Sensors
激光雷达传感器通过发射成千上万的激光信号, 为我们提供高分辨率的数据. 这些激光被物体反射回传感器, 然后可以通过计算信号返回所需的时间来确定物体的距离. 我们还可以通过测量返回信号的强度来了解一点被J激光击中物体的情况. 每一束激光都处于红外光谱中, 并以不同的角度发射出去, 通常是360度的范围. 尽管激光雷达传感器为我们提供了非常高精度的3 d 世界模型, 但它们目前非常昂贵, 甚至有的高达6万美元.
- 激光雷达以不同的角度发射数千束激光
- 激光被发射出来, 从障碍物上反射出来, 然后用接收器探测到
- 根据激光发射和接收的时间差, 计算出距离
- 接收到的激光强度值可用于评价被激光反射物体的材料性质

这是Velodyne 激光雷达传感器, 由左至右采用 HDL 64, HDL 32, VLP 16. 传感器越大, 分辨率越高. 下面是 HDL 64激光雷达的规格说明. 激光雷达共有64层, 每一层都以与 z 轴不同的角度发射出去, 因此倾斜度也不同. 每一层都覆盖了360度的视角, 角分辨率为0.08度. 激光雷达平均每秒扫描十次. 激光雷达可以探测到远达120米的汽车和树木, 还可以探测到远达50米的人行道.
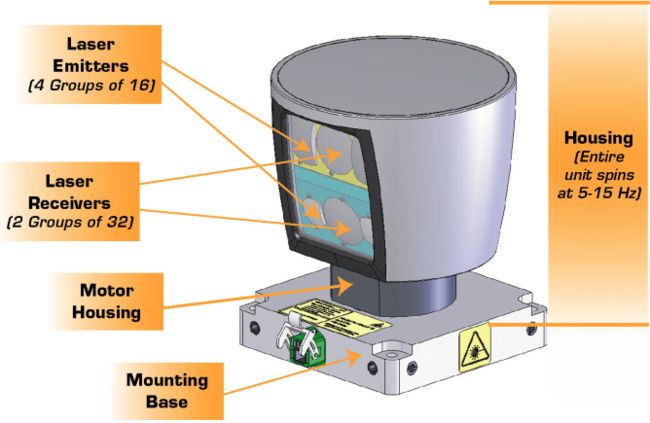
VLP 64示意图, 显示激光雷达发射器、接收器和外壳
这个传感器有64层, 角分辨率为0.09度, 平均更新频率为10Hz, 每秒收集(64x (360 / 0.08) x10)=288万个数据
PCD data
让我们深入研究激光雷达数据是如何存储的. 激光雷达数据以一种称为点云数据(简称 PCD)的格式存储. PCD 文件是(x, y, z)笛卡尔坐标和强度值的列表, 它是在一次扫描之后环境的一个快照. 使用 VLP 64激光雷达, PCD 文件将有大约256,000个(x, y, z, i)点云值.
点云数据的坐标系与汽车的本地坐标系相同. 在这个坐标系中, x 轴指向汽车的前部, y 轴指向汽车的左侧. 此外, z轴指向车的上方.

PCL库 广泛应用于机器人技术领域, 用于处理点云数据, 网上有许多教程可供使用. PCL 中有许多内置的功能可以帮助检测障碍物. 本项目后面会使用 PCL内置的分割、提取和聚类函数. 你在这里可以找到PCL库的文档.
Steps For Obstacle Detection
Stream PCD
首先我们需要流式载入激光点云数据.
template
std::vector ProcessPointClouds::streamPcd(std::string dataPath) {
std::vector paths(boost::filesystem::directory_iterator{dataPath},boost::filesystem::directory_iterator{});
// sort files in accending order so playback is chronological
sort(paths.begin(), paths.end());
return paths;
}
// ####################################################
ProcessPointClouds* pointProcessorI = new ProcessPointClouds();
std::vector stream = pointProcessorI >streamPcd("../src/sensors/data/pcd/data_1");
auto streamIterator = stream.begin();
pcl::PointCloud::Ptr inputCloudI;

真实PCD数据
Point Processing
处理点云数据的第一步就是要创建一个processPointClouds的对象, 这个对象中包含所有处理激光点云数据的模块, 如过滤, 分割, 聚类, 载入、存储PCD数据. 我们需要为不同的点云数据创建一个通用模板: template. 在真实点云数据中, 点云的类型是pcl::PointXYZI. 创建pointProcessor可以建立在Stack上也可以建立在Heap上, 但是建议在Heap上, 毕竟使用指针更加轻便.
// Build PointProcessor on the heap
ProcessPointClouds *pointProcessorI = new ProcessPointClouds();
// Build PointProcessor on the stack
ProcessPointClouds pointProcessorI;
Filtering
值得注意的是点云数据一般有很高的分辨率和相当远的可视距离. 我们希望代码处理管道能够尽可能快地处理点云, 因此需要对点云进行过滤. 这里有两种方法可以用来做到这一点.
-
Voxel Grid
体素网格过滤将创建一个立方体网格, 过滤点云的方法是每个体素立方体内只留下一个点, 因此立方体每一边的长度越大, 点云的分辨率就越低. 但是如果体素网格太大, 就会损失掉物体原本的特征. 具体实现可以查看PCL-voxel grid filtering的文档 .
-
Region of Interest
定义感兴趣区域, 并删除感兴趣区域外的任何点. 感兴趣区域的选择两侧需要尽量覆盖车道的宽度, 而前后的区域要保证你可以及时检测到前后车辆的移动. 具体实现可以查看PCL-region of interest的文档. 在最终结果中, 我们使用
pcl CropBox查找自身车辆车顶的点云数据索引, 然后将这些索引提供给pcl ExtractIndices对象删除, 因为这些对于我们分析点云数据没有用处.
感兴趣区域及体素网格过滤后的结果
以下是Filtering的代码实现:
filterRes是体素网格的大小,minPoint/maxPoint为感兴趣区域的最近点和最远点.我们首先执行VoxelGrid减少点云数量, 然后设置最近和最远点之间的感兴趣区域, 最后再从中删除车顶的点云.
// To note, "using PtCdtr = typename pcl::PointCloud::Ptr;" template PtCdtr ProcessPointClouds ::FilterCloud(PtCdtr cloud, float filterRes, Eigen::Vector4f minPoint,Eigen::Vector4f maxPoint) { // Time segmentation process auto startTime = std::chrono::steady_clock::now(); // TODO:: Fill in the function to do voxel grid point reduction and region based filtering // Create the filtering object: downsample the dataset using a leaf size of .2m pcl::VoxelGrid vg; PtCdtr cloudFiltered(new pcl::PointCloud ); vg.setInputCloud(cloud); vg.setLeafSize(filterRes, filterRes, filterRes); vg.filter(*cloudFiltered); PtCdtr cloudRegion(new pcl::PointCloud ); pcl::CropBox region(true); region.setMin(minPoint); region.setMax(maxPoint); region.setInputCloud(cloudFiltered); region.filter(*cloudRegion); std::vector indices; pcl::CropBox roof(true); roof.setMin(Eigen::Vector4f(-1.5, -1.7, -1, 1)); roof.setMax(Eigen::Vector4f(2.6, 1.7, -0.4, 1)); roof.setInputCloud(cloudRegion); roof.filter(indices); pcl::PointIndices::Ptr inliers{new pcl::PointIndices}; for (int point : indices) { inliers->indices.push_back(point); } pcl::ExtractIndices extract; extract.setInputCloud(cloudRegion); extract.setIndices(inliers); extract.setNegative(true); extract.filter(*cloudRegion); auto endTime = std::chrono::steady_clock::now(); auto elapsedTime = std::chrono::duration_cast
Segmentation
Segmentation的任务是将属于道路的点和属于场景的点分开. 点云分割的具体细节推荐查看PCL的官网文档: Segmentation和Extracting indices .

点云分割的结果
PCL RANSAC Segmentaion
针对本项目, 我创建了两个函数SegmentPlane和SeparateClouds, 分别用来寻找点云中在道路平面的inliers(内联点)和提取点云中的outliers(物体).
以下是主体代码:
// To note, "using PtCdtr = typename pcl::PointCloud::Ptr;"
template
std::pair, PtCdtr>
ProcessPointClouds::SegmentPlane(PtCdtr cloud, int maxIterations, float distanceThreshold) {
// Time segmentation process
auto startTime = std::chrono::steady_clock::now();
// pcl::PointIndices::Ptr inliers; // Build on the stack
pcl::PointIndices::Ptr inliers(new pcl::PointIndices); // Build on the heap
// TODO:: Fill in this function to find inliers for the cloud.
pcl::ModelCoefficients::Ptr coefficient(new pcl::ModelCoefficients);
pcl::SACSegmentation seg;
seg.setOptimizeCoefficients(true);
seg.setModelType(pcl::SACMODEL_PLANE);
seg.setMethodType(pcl::SAC_RANSAC);
seg.setMaxIterations(maxIterations);
seg.setDistanceThreshold(distanceThreshold);
// Segment the largest planar component from the remaining cloud
seg.setInputCloud(cloud);
seg.segment(*inliers, *coefficient);
if (inliers->indices.size() == 0) {
std::cerr << "Could not estimate a planar model for the given dataset" << std::endl;
}
auto endTime = std::chrono::steady_clock::now();
auto elapsedTime = std::chrono::duration_cast(endTime - startTime);
std::cout << "plane segmentation took " << elapsedTime.count() << " milliseconds" << std::endl;
std::pair, PtCdtr> segResult = SeparateClouds(
inliers, cloud);
return segResult;
}
template
std::pair, PtCdtr>
ProcessPointClouds::SeparateClouds(pcl::PointIndices::Ptr inliers, PtCdtr cloud) {
// TODO: Create two new point clouds, one cloud with obstacles and other with segmented plane
PtCdtr obstCloud(new pcl::PointCloud());
PtCdtr planeCloud(new pcl::PointCloud());
for (int index : inliers->indices) {
planeCloud->points.push_back(cloud->points[index]);
}
// create extraction object
pcl::ExtractIndices extract;
extract.setInputCloud(cloud);
extract.setIndices(inliers);
extract.setNegative(true);
extract.filter(*obstCloud);
std::pair, PtCdtr> segResult(obstCloud,
planeCloud);
// std::pair, PtCdtr> segResult(cloud, cloud);
return segResult;
}
在SegmentPlane函数中我们接受点云、最大迭代次数和距离容忍度作为参数, 使用std::pair对象来储存物体和道路路面的点云. SeparateClouds 函数提取点云中的非inliers点, 即obstacles点. 粒子分割是一个迭代的过程, 更多的迭代有机会返回更好的结果, 但同时需要更长的时间. 过大的距离容忍度会导致不是一个物体的点云被当成同一个物体, 而过小的距离容忍度会导致一个较长的物体无法被当成同一个物体, 比如卡车.
Manual RANSAC Segmentation
目前粒子分割主要使用RANSAC算法. RANSAC全称Random Sample Consensus, 即随机样本一致性, 是一种检测数据中异常值的方法. RANSAC通过多次迭代, 返回最佳的模型. 每次迭代随机选取数据的一个子集, 并生成一个模型拟合这个子样本, 例如一条直线或一个平面. 然后具有最多inliers(内联点)或最低噪声的拟合模型被作为最佳模型. 如其中一种RANSAC 算法使用数据的最小可能子集作为拟合对象. 对于直线来说是两点, 对于平面来说是三点. 然后通过迭代每个剩余点并计算其到模型的距离来计算 inliers 的个数. 与模型在一定距离内的点被计算为inliers. 具有最高 inliers 数的迭代模型就是最佳模型. 这是我们在这个项目中的实现版本. 也就是说RANSAC算法通过不断迭代, 找到拟合最多inliers的模型, 而outliers被排除在外. RANSAC 的另一种方法对模型点的某个百分比进行采样, 例如20% 的总点, 然后将其拟合成一条直线. 然后计算该直线的误差, 以误差最小的迭代法为最佳模型. 这种方法的优点在于不需要考虑每次迭代每一点. 以下是使用RANSAC算法拟合一条直线的示意图, 真实激光数据下是对一个平面进行拟合, 从而分离物体和路面. 以下将单独对RANSAC平面算法进行实现.
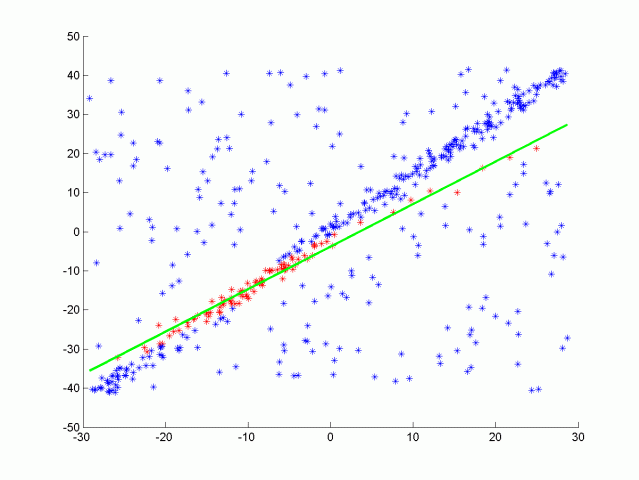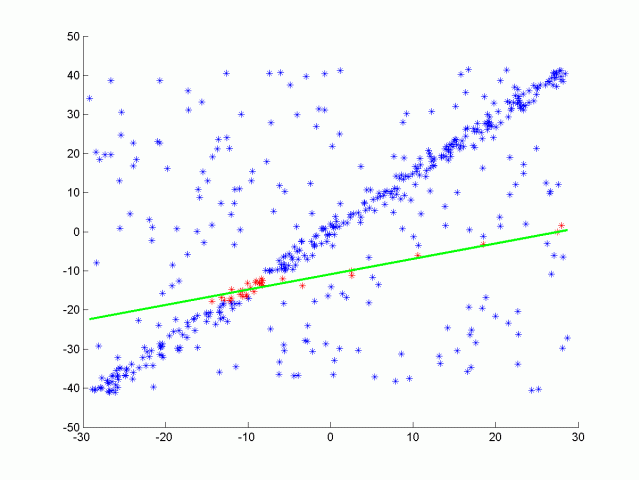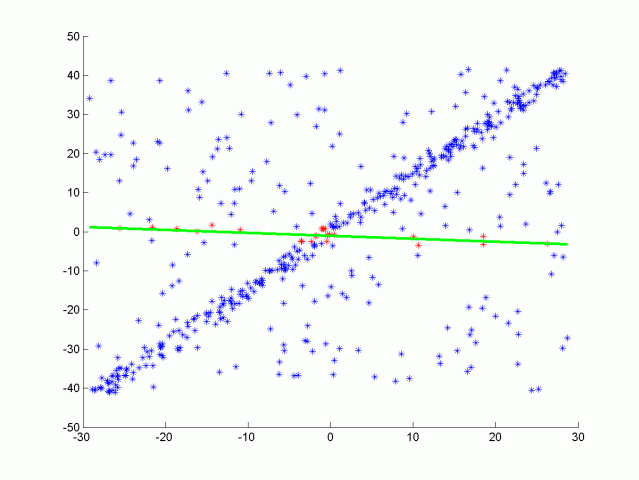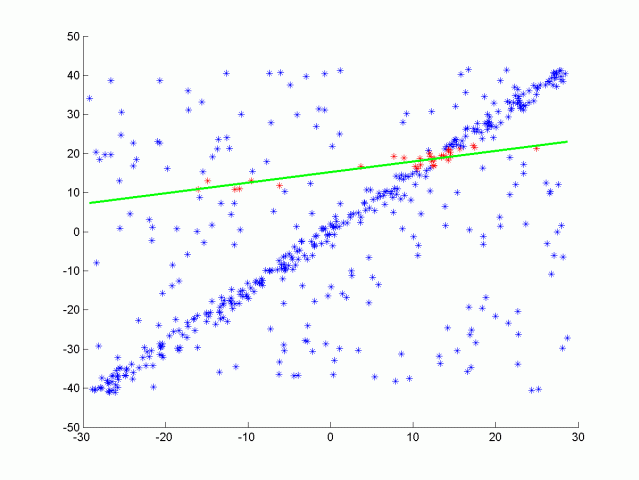
以下将介绍RANSAC的平面计算公式:

然后我们需要计算点 (x,y,z)到平面的距离

以下为平面RANSAC的主体代码
template
std::unordered_set Ransac::Ransac3d(PtCdtr cloud) {
std::unordered_set inliersResult; // unordered_set element has been unique
// For max iterations
while (maxIterations--) {
std::unordered_set inliers;
while (inliers.size() < 3) {
inliers.insert(rand()%num_points);
}
// TO define plane, need 3 points
float x1, y1, z1, x2, y2, z2, x3, y3, z3;
auto itr = inliers.begin();
x1 = cloud->points[*itr].x;
y1 = cloud->points[*itr].y;
z1 = cloud->points[*itr].z;
itr++;
x2 = cloud->points[*itr].x;
y2 = cloud->points[*itr].y;
z2 = cloud->points[*itr].z;
itr++;
x3 = cloud->points[*itr].x;
y3 = cloud->points[*itr].y;
z3 = cloud->points[*itr].z;
// Calulate plane coefficient
float a, b, c, d, sqrt_abc;
a = (y2 - y1) * (z3 - z1) - (z2 - z1) * (y3 - y1);
b = (z2 - z1) * (x3 - x1) - (x2 - x1) * (z3 - z1);
c = (x2 - x1) * (y3 - y1) - (y2 - y1) * (x3 - x1);
d = -(a * x1 + b * y1 + c * z1);
sqrt_abc = sqrt(a * a + b * b + c * c);
// Check distance from point to plane
for (int ind = 0; ind < num_points; ind++) {
if (inliers.count(ind) > 0) { // that means: if the inlier in already exist, we dont need do anymore
continue;
}
PointT point = cloud->points[ind];
float x = point.x;
float y = point.y;
float z = point.z;
float dist = fabs(a * x + b * y + c * z + d) / sqrt_abc; // calculate the distance between other points and plane
if (dist < distanceTol) {
inliers.insert(ind);
}
if (inliers.size() > inliersResult.size()) {
inliersResult = inliers;
}
}
}
return inliersResult;
}
但在实际中PCL已经内置了RANSAC函数, 而且比我写的计算速度更快, 所以直接用内置的就行了.
Clustering
聚类是指把不同物体的点云分别组合聚集起来, 从而能让你跟踪汽车, 行人等多个目标. 其中一种对点云数据进行分组和聚类的方法称为欧氏聚类.
欧式聚类是指将距离紧密度高的点云聚合起来. 为了有效地进行最近邻搜索, 可以使用 KD-Tree 数据结构, 这种结构平均可以加快从 o (n)到 o (log (n))的查找时间. 这是因为Kd-Tree允许你更好地分割你的搜索空间. 通过将点分组到 KD-Tree 中的区域中, 您可以避免计算可能有数千个点的距离, 因为你知道它们不会被考虑在一个紧邻的区域中.

欧氏聚类的结果
PCL Euclidean clustering
首先我们使用PCL内置的欧式聚类函数. 点云聚类的具体细节推荐查看PCL的官网文档Euclidean Cluster.
欧氏聚类对象 ec 具有距离容忍度. 在这个距离之内的任何点都将被组合在一起. 它还有用于表示集群的点数的 min 和 max 参数. 如果一个集群真的很小, 它可能只是噪音, min参数会限制使用这个集群. 而max参数允许我们更好地分解非常大的集群, 如果一个集群非常大, 可能只是许多其他集群重叠, 最大容差可以帮助我们更好地解决对象检测. 欧式聚类的最后一个参数是 Kd-Tree. Kd-Tree是使用输入点云创建和构建的, 这些输入云点是初始点云过滤分割后得到障碍物点云.
以下是PCL内置欧式聚类函数的代码:
// To note, "using PtCdtr = typename pcl::PointCloud::Ptr;"
template
std::vector>
ProcessPointClouds::Clustering(PtCdtr cloud, float clusterTolerance, int minSize, int maxSize) {
// Time clustering process
auto startTime = std::chrono::steady_clock::now();
std::vector> clusters;
// TODO:: Fill in the function to perform euclidean clustering to group detected obstacles
// Build Kd-Tree Object
typename pcl::search::KdTree::Ptr tree(new pcl::search::KdTree);
// Input obstacle point cloud to create KD-tree
tree->setInputCloud(cloud);
std::vector clusterIndices; // this is point cloud indice type
pcl::EuclideanClusterExtraction ec; // clustering object
ec.setClusterTolerance(clusterTolerance);
ec.setMinClusterSize(minSize);
ec.setMaxClusterSize(maxSize);
ec.setSearchMethod(tree);
ec.setInputCloud(cloud); // feed point cloud
ec.extract(clusterIndices);// get all clusters Indice
// For each cluster indice
for (pcl::PointIndices getIndices: clusterIndices) {
PtCdtr cloudCluster(new pcl::PointCloud);
// For each point indice in each cluster
for (int index:getIndices.indices) {
cloudCluster->points.push_back(cloud->points[index]);
}
cloudCluster->width = cloudCluster->points.size();
cloudCluster->height = 1;
cloudCluster->is_dense = true;
clusters.push_back(cloudCluster);
}
auto endTime = std::chrono::steady_clock::now();
auto elapsedTime = std::chrono::duration_cast(endTime - startTime);
std::cout << "clustering took " << elapsedTime.count() << " milliseconds and found " << clusters.size()<< " clusters" << std::endl;
return clusters;
}
Manual Euclidean clustering
除此之外我们也可以直接使用KD-Tree进行欧氏聚类.
在此我们首先对KD-Tree的原理进行介绍. KD-Tree是一个数据结构, 由二进制树表示, 在不同维度之间对插入的点的数值进行交替比较, 通过分割区域来分割空间, 如在3D数据中, 需要交替在X,Y,Z不同轴上比较. 这样会使最近邻搜索可以快得多.
首先我们在试着二维空间上建立KD-Tree, 并讲述欧氏聚类的整个在二维空间上的实现过程, 最终我们将扩展到三维空间.
-
在
KD-Tree中插入点(这是将点云输入到树中创建和构建KD-Tree的步骤)假设我们需要在
KD-Tree中插入4个点(-6.3, 8.4), (-6.2, 7), (-5.2, 7.1), (-5.7, 6.3)首先我们得确定一个根点(-6.2, 7), 第0层为x轴, 需要插入的点为(-6.3, 8.4), (-5.2, 7.1), 因为-6.3<-6.2,(-6.3, 8.4)划分为左子节点, 而-5.2>-6.2, (-5.2, 7.1)划分为右子节点. (-5.7, 6.3)中x轴-5.7>-6.2,所以放在(-5.2, 7.1)节点下, 接下来第1层使用y轴, 6.3<7.1, 因此放在(-5.2, 7.1)的左子节点. 同理, 如果我们想插入第五个点(7.2, 6.1), 你可以交替对比x,y轴数值,
(7.2>-6.2)->(6.1<7.1)->(7.2>-5.7), 第五点应插入到(-5.7, 6.3)的右子节点C.下图是
KD-Tree的结构.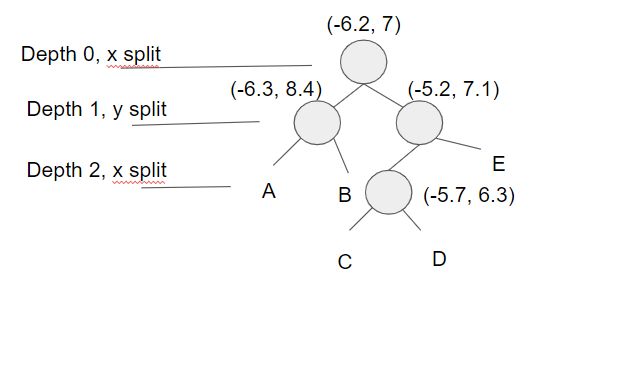
KD-Tree的目的是将空间分成不同的区域, 从而减少最紧邻搜索的时间.

它是通过递归的方式使用新插入点更新节点. 其基本思想是遍历树, 直到它到达的节点为 NULL, 在这种情况下, 将创建一个新节点并替换 NULL 节点. 我们可以使用一个双指针来分配一个节点, 也就是说可以从根开始传递一个指向节点的指针, 然后当你想要替换一个节点时, 您可以解引用双指针并将其分配给新创建的节点.
我们可以通过代码了解在KD-Tree中插入点的思路:
struct Node {
std::vector point;
int id;
Node *left;
Node *right;
Node(std::vector arr, int setId)
: point(arr), id(setId), left(NULL), right(NULL) {}
};
struct KdTree {
Node *root;
KdTree()
: root(NULL) {}
// Kd-Tree insert
void insertHelper(Node **node, uint depth, std::vector point, int id) {
// Tree is empty
if (*node == NULL) {
*node = new Node(point, id);
} else {
// calculate current dim (1 means x axes, 2means y axes)
uint cd = depth % 2;
if (point[cd] < ((*node)->point[cd])) {
insertHelper(&((*node)->left), depth + 1, point, id);
} else {
insertHelper(&((*node)->right), depth + 1, point, id);
}
}
}
void insert(std::vector point, int id) {
// TODO: Fill in this function to insert a new point into the tree
// the function should create a new node and place correctly with in the root
insertHelper(&root, 0, point, id);
}
// #############################################################################################################
// Kd-Tree search
void searchHelper(std::vector target, Node *node, int depth, float distanceTol, std::vector &ids)
{
if (node != NULL)
{
// Check whether the node inside box or not, point[0] means x axes, point[1]means y axes
if ((node->point[0] >= (target[0] - distanceTol) && node->point[0] <= (target[0] + distanceTol)) &&(node->point[1] >= (target[1] - distanceTol) && node->point[1] <= (target[1] + distanceTol)))
{
float distance = sqrt((node->point[0] - target[0]) * (node->point[0] - target[0]) +(node->point[1] - target[1]) * (node->point[1] - target[1]));
if (distance <= distanceTol)
{
ids.push_back(node->id);
}
}
// check across boundary
if ((target[depth % 2] - distanceTol) < node->point[depth % 2])
{
searchHelper(target, node->left, depth + 1, distanceTol, ids);
}
if ((target[depth % 2] + distanceTol) > node->point[depth % 2])
{
searchHelper(target, node->right, depth + 1, distanceTol, ids);
}
}
}
// return a list of point ids in the tree that are within distance of target
std::vector search(std::vector target, float distanceTol)
{
std::vector ids;
searchHelper(target, root, 0, distanceTol, ids);
return ids;
}
};
-
使用KD-Tree分割好的空间进行搜索

Kd-Tree分割区域并允许某些区域被完全排除, 从而加快了寻找近临点的进程
在上图中我们有8个点, 常规的方法是遍历计算每一个点到根点的距离, 在距离容忍度内的点为近邻点. 现在我们已经在Kd-Tree中插入了所有点, 我们建立一个根点周围2 x distanceTol长度的方框, 如果当前节点位于此框中, 则可以直接计算距离, 并查看是否应该将点 id 添加到紧邻点id 列表中, 然后通过查看方框是否跨越节点分割区域, 确定是否需要比较下一个节点. 递归地执行此操作, 其优点是如果框区域不在某个分割区域内, 则完全跳过该区域. 如上如图所示, 左上, 左下和右边分割区域均不在方框区域内, 直接跳过这些区域, 只需要计算方框内的绿点到根点的距离.
上面的代码块中第二部分为基于Kd-Tree的搜索代码.
一旦实现了用于搜索邻近点的Kd-Tree 方法, 就不难实现基于邻近度对单个聚类指标进行分组的欧氏聚类方法.
执行欧氏聚类需要迭代遍历云中的每个点, 并跟踪已经处理过的点. 对于每个点, 将其添加到一个集群(cluster)的点列表中, 然后使用前面的搜索函数获得该点附近所有点的列表. 对于距离很近但尚未处理的每个点, 将其添加到集群中, 并重复调用proximity的过程. 对于第一个集群, 递归停止后, 创建一个新的集群并移动点列表, 对于新的集群重复上面的过程. 一旦处理完所有的点, 就会找到一定数量的集群, 返回一个集群列表.
以下是欧氏聚类的伪代码:
Proximity(point,cluster):
mark point as processed
add point to cluster
nearby points = tree(point)
Iterate through each nearby point
If point has not been processed
Proximity(cluster)
EuclideanCluster():
list of clusters
Iterate through each point
If point has not been processed
Create cluster
Proximity(point, cluster)
cluster add clusters
return clusters
真实代码:
void clusterHelper(int indice, const std::vector> &points, std::vector &cluster,std::vector &processed, KdTree *tree, float distanceTol) {
processed[indice] = true;
cluster.push_back(indice);
std::vector nearest = tree->search(points[indice], distanceTol);
for (int id:nearest) {
if (!processed[id]) {
clusterHelper(id, points, cluster, processed, tree, distanceTol);
}
}
}
std::vector>euclideanCluster(const std::vector> &points, KdTree *tree, float distanceTol) {
// TODO: Fill out this function to return list of indices for each cluster
std::vector> clusters;
std::vector processed(points.size(), false);
int i = 0;
while (i < points.size()) {
if (processed[i]) {
i++;
continue;
}
std::vector cluster;
clusterHelper(i, points, cluster, processed, tree, distanceTol);
clusters.push_back(cluster);
i++;
}
return clusters;
}
以上是在二维空间下欧式聚类的实现, 在真实激光点云数据中我们需要将欧式聚类扩展到三维空间. 具体代码实现可以参考我的GITHUB中的cluster3d/kdtree3d文件. 自己手写欧氏聚类能够增强对概念的理解, 但其实真正项目上直接用PCL内置欧氏聚类函数就行.
Bounding Boxes
在完成点云聚类之后, 我们最后一步需要为点云集添加边界框. 其他物体如车辆, 行人的边界框的体积空间内是禁止进入的, 以免产生碰撞.
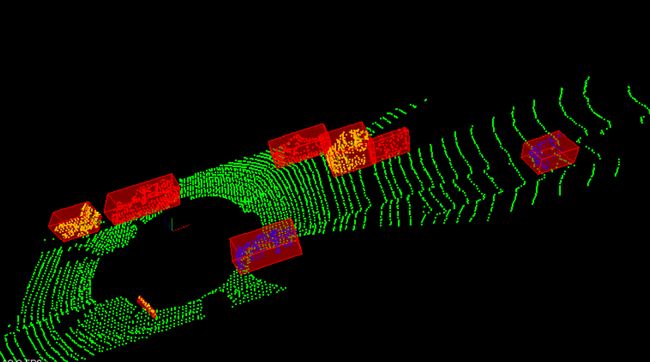
以下是生成边界框的代码实现:
template
Box ProcessPointClouds::BoundingBox(PtCdtr cluster) {
// Find bounding box for one of the clusters
PointT minPoint, maxPoint;
pcl::getMinMax3D(*cluster, minPoint, maxPoint);
Box box;
box.x_min = minPoint.x;
box.y_min = minPoint.y;
box.z_min = minPoint.z;
box.x_max = maxPoint.x;
box.y_max = maxPoint.y;
box.z_max = maxPoint.z;
return box;
}
// Calling Bouding box function and render box
Box box = pointProcessor->BoundingBox(cluster);
renderBox(viewer,box,clusterId);
最终我们通过renderbox函数显示出一个个的Bounding Boxes.
对于Bounding Boxes的生成可以使用PCA主成分分析法生成更小的方框, 实现更高的预测结果精准性. 具体PCL实现可以查看这个链接:PCL-PCA.
现在我们完成了所有的激光点云处理的步骤, 让我们来看看最终成果吧!
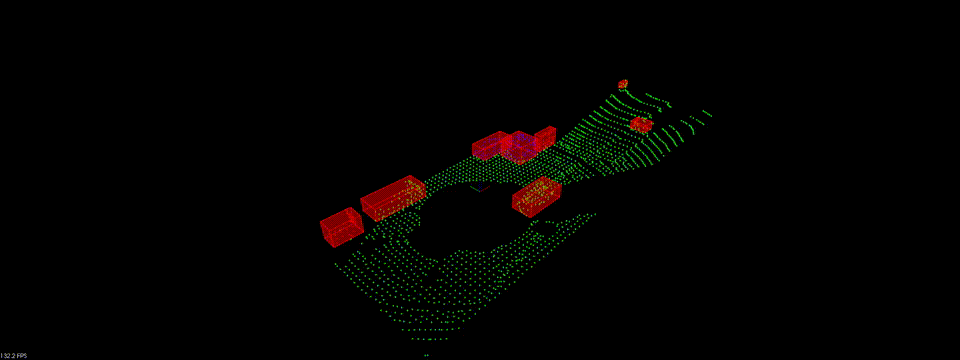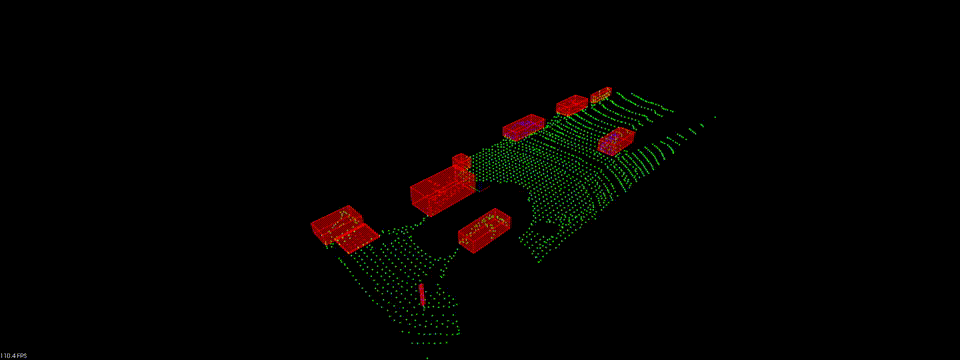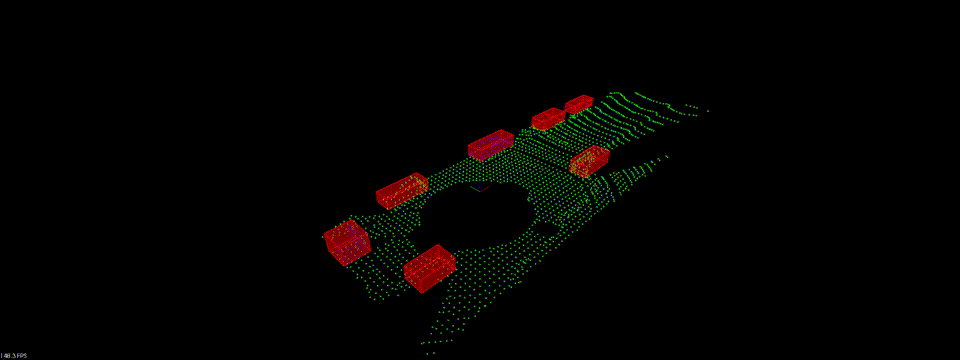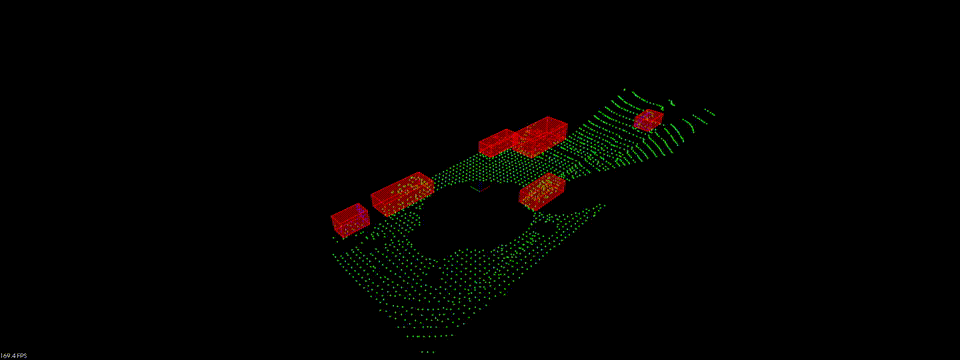
Linkedin: https://linkedin.com/in/williamhyin