感觉每一篇总结文章不适合放太多的内容,否则读起来的话,有些累,而且会比较索然无味。(当然可能也和自己写的文章水平有关吧,哈哈哈)
接着上篇的总结,继续再总结、梳理几个问题:
目录
1.行/列数据库 关系型/非关系型数据库
2.SOA和微服务架构
3.网络I/O模型
1.行/列数据库 关系/非关系型数据库
1.1 行/列数据库
1.1.1 什么是行/列数据库
简单理解这两个概念:
行存储:一次写入一个完整的数据实体(包含了各种字段)
列存储:一次写入所有数据的一个属性
然后结合数据库软件,计算机磁盘来理解这两个概念:无非就是数据库软件能够对外(即对操作者)提供相应的行/列数据库的设计接口,甚至是可视化界面接口。然后对内(即对计算机磁盘)进行行/列式的存储,即是按照每个实体来存储还是按照每个字段来存储。
1.1.2 它们各自的优缺点
行存储的优缺点:优点是对一个实体数据的写入/改修 性能很高,缺点是如果要对很多实体的某一属性进行操作,则会产生其他实体数据属性的冗余,而且在操作上的性能也很低
列存储的优缺点:优点是能操作很多实体的某些属性性能很高,但是对于完整实体的操作性能很低
1.1.3 它们的应用场景
应用场景则是根据它们各自的优缺点来进行灵活确定的。
但是目前对于大数据库的存储,操作主流做法都是基于列示存储的。
1.1.4 数据库代表
行式数据库的代表包括:传统的RDBMS
列式数据库的代表包括:SAP HANA、Amazon Redshift、Sybase IQ、ParAccel、Sand/DNA Analytics、Vertica、Aster Data Systems和greenplum等。
1.1.5 参考文章:
大数据存取的选择:行存储还是列存储?
数据库的方向 - 行vs列
对列式数据库的一点总结和展望
列式数据库-维基百科
1.2 关系/非关系型数据库
1.2.1 什么是关系/非关系型数据库
关系型数据库,即RDBMS,每个表是按照实体来设计的,是一个二维表格模型,并且需要遵循许多的设计约束
非关系型数据库,也叫做NOSQL数据库,它不要求每一条记录都是一个完整的实体,所以相对来说字段可以自由变化、扩展。
这两类就是不同数据库的规定,可以有关系,也可以没有关系(但并不绝对)。
1.2.2 它们各自的优缺点
关系型数据库:符合约束规范设计,能够很好地保证数据的完整性,一致性,减少数据冗余。
但是对于并发性能不好(主要原因就在于磁盘IO),对海量数据的操作息效率很低,扩展性较差(表具有固定的结构)。
非关系型数据库:以键值对存储,可以随意扩展,支持高并发,可以海量数据的访问,支持分布式扩展
但是不能很好地支持事务(即不具备完整的ACID)
1.2.3 它们的应用场景
关系型数据库:对事务要求高的,不用经常扩展的,并发量不高,对海量数据操作少。
非关系型数据库:高并发,海量数据操作,分布式架构
1.2.4 它们各自的代表
关系型数据库: Oracle, Sql Server, Access, Mysql
非关系型数据库: redis,mongoDB,memcached,
1.2.5 参考文章:
关系型数据库和非关系型数据库
2.SOA和微服务架构
首先来看一张它们的演变图:

2.1 传统SOA架构:
2.1.1 为什么会有传统SOA架构的产生
早期大型系统,比如ERP,OA,CRM等难以进行集成,故产生了SOA架构
2.1.2 传统SOA架构是怎样的

该架构有一个企业服务总线ESB,它的作用就是对外提供支持各种协议、粗粒度的服务接口,对内映射相应的服务。
2.1.3 传统SOA架构有什么优缺点
1.存在多种通讯协议,通讯方式复杂
2.ESB存在单点故障 隐患
3.开发代价很大
2.2 新型的SOA架构:
应用->服务,即应用直接调用外部服务,通讯协议一般为HTTP,数据格式一般为JSON
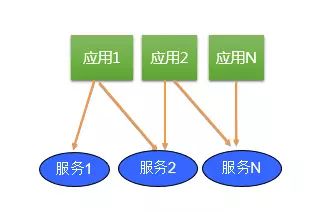
2.3 微服务
优点:
简单连接:一般为HTTP + JSON
分散管理:可以单独编译,部署。
支持自由扩展
系统容错性高
微服务遇到的问题:
1.复杂的分布式系统通
2.分布式事务一致性
2.4 参考文章
重新理解微服务
每天都在谈SOA和微服务,但你真的理解什么是服务吗?
基于微服务的软件架构模式
3.网络I/O模型
总体来说分为两大类:同步和异步模型。
- 同步模型
- 阻塞I/O
- 非阻塞I/O
- 多路复用I/O
- 信号驱动式I/O
- 异步IO
网络I/O模型的过程:
网络I/O的本质是socket的读取,socket在linux系统被抽象为流,I/O可以理解为对流的操作。这个操作又分为两个阶段:
- 等待流数据准备(wating for the data to be ready)。
- 从内核向进程复制数据(copying the data from the kernel to the process)。
对于socket流而言:
第一步通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
第二步把数据从内核缓冲区复制到应用进程缓冲区。
- 阻塞I/O
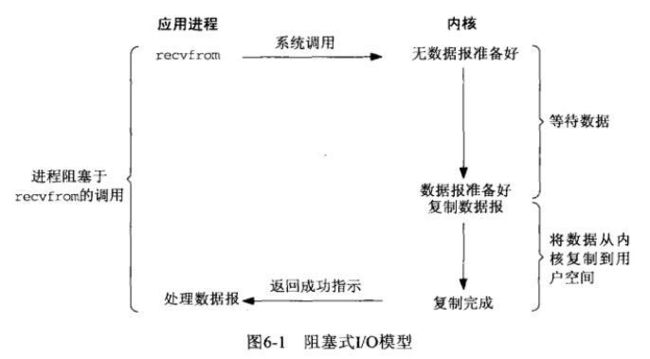
首先用户空间的一个进程调用了recvfrom(系统调用方法),然后该方法被转移到内核空间中执行。注意当用户空间的进程执行了该方法,便进入阻塞状态。内核空间执行该方法,开始接受相应的数据,直接数据在内核空间准备就绪,这个时候将数据复制到用户空间,最后用户空间从recvfrom返回。
- 非阻塞I/O
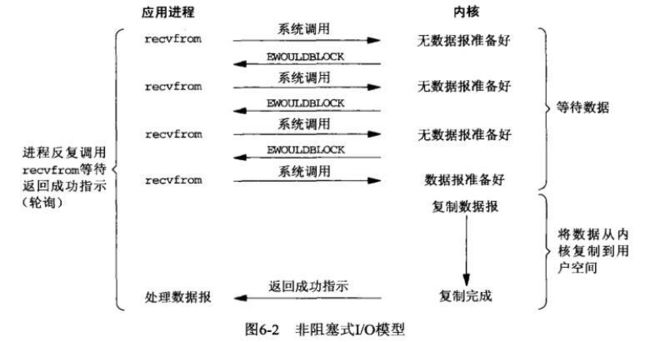
内核中数据准备好之前,用户空间的进程不会阻塞,而是采用轮询方式来访问。
- 多路复用I/O

用户空间进程调用select后阻塞,直到内核空间返回目前可用的可读条件,接着再读取内核空间的数据,此时又为阻塞。(需要注意的是内核空间返回的还可能是可写或异常条件)
- 异步IO

对于异步IO来说,感觉一切都显得那么简单残暴。用户空间调用read方法,然后内核直接返回,此时用户空间继续执行接下来的代码,而不用阻塞在这里。当用户空间数据准备就绪,就从内核返回一个信号通知最后的结果。
个人对同步/异步,阻塞/非阻塞的理解
对于阻塞/非阻塞的描述对象,指的是进程/线程的,准确一点说是它的状态。
对于同步/异步,个人认为,与阻塞/非阻塞没有任何关系。它指的是如果当前方法想要得到一个最终的结果值,那么该方法就是同步的。同步意味着什么?每一条语句的执行都是依赖上一条一个确定的执行结果,整个执行过程是可以追踪,有迹可循的。而对于异步来说,当前语句并不关心返回的是否是最终结果,而一旦最终执行结果出来了,那么可以通过一种”信号“机制来告知当前进程。所以异步能够阻止进程的阻塞,从而进一步提高系统的响应速度。但是异步也有缺点,那就是如果要对代码执行进行追踪,则相对来说比较困难,因为并不清楚每一个异步操作的返回值是何时返回的。
参考文章:
简明网络I/O模型---同步异步阻塞非阻塞之惑