笔者所在的团队今年的重点工作之一,是完善现有验证码的产品形态,改善只有字符输入型验证码的窘境:本文主要旨在横向对比国内外同行产品,为公司自研验证码产品设计提供参考和思路(目前仅关注web端,app端前期复用h5)。部分内容来源于网络。如有错误,欢迎指正
原因是此类验证码易被各图像识别软件、打码平台轻易破解,导致黄牛注册、领券、撞库等成本偏低,公司利益和用户安全难以得到保障。
好的设计从学习开始。调研范围如下,基本涵盖了比较主流的验证码平台:
- Google reCAPTCHA
- 极验
- 阿里云
- 腾讯云
- 点触
- 网易易盾
- 螺丝帽
- FunCaptcha
如果要问笔者心中最好的产品,那无疑是Google reCAPTCHA。
产品背景
reCAPTCHA起初是由CMU(卡耐基梅隆大学)设计,将OCR(光学自动识别)软件无法识别的文字扫描图传给世界各大网站,用以替换原来的验证码图片。那些网站的用户在正确识别出这些文字之后,其答案便会被传回CMU。这样一来既起到了验证码的效果,又可以帮助进行古籍的数字化工作(可以称为人工OCR)。
reCAPTCHA在2009年被Google 收购,Google让reCAPTCHA里显示Google街景的图片。这样经常会从街景里提取如街道名称和交通标志等数据,向Google地图里添加商铺地址和位置等有用信息。
思维超前,做事一举两得,似乎已融入reCAPTCHA的基因
再往后,新版reCAPTCHA又进化为noCAPTCHA——这也是不得已而为之。人工智能飞速发展,据说已经能够解决99.8%的图片字符型验证码,因此扭曲的文本验证方式也不再是一个可靠的方法。noCAPTCHA只提供了一个复选框,里面写着“我不是机器人”。当你打钩之后,Google就能利用“风险分析引擎”进行一系列无缝检查,以此来判断你是否是真人。
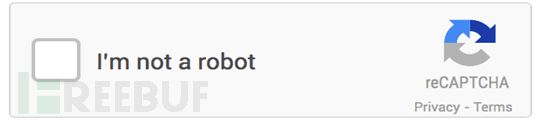
如果noCAPTCHA认为你是真人,那就不用再做什么了;否则会要求你填一个传统的CAPTCHA字符串或更先进的字符串,比如门牌号,或从一组图片中挑选出正确的图片。


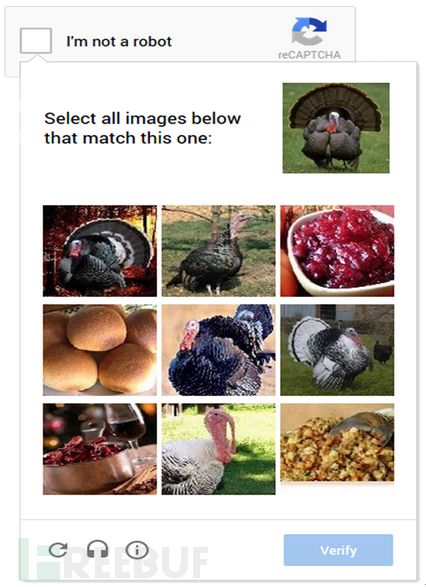
复选框看似更简单,但背后确是Google强大的机器学习技术。基本的原理就是先检测客户端环境,判断使用者是否处于人类的操作环境中。如果检测结果在容错范围内则直接通过测试,否则弹出验证码进行二次认证。
目前国内的验证码产品,只有阿里采用了类似做法。区别只在于一个是复选框,一个是滑动条(后续阿里的部分会讲到)
据统计reCAPTCHA的技术可以大大提高识别准确率,总共可以有效节约用户每天50000小时的上网时间。

reCAPTCHA今年3.13日又升级到了Invisible reCAPTCHA,顾名思义,“隐形验证码”。这样一来,连复选框都不会出现,对普通用户完全透明,用户体验又更进一步。
页面底部将展示一个logo注明当前页面使用到此技术(当然不想要也可以将其隐藏)。
这种黑科技可谓十分霸气,要知道国内目前大多数公司还停留在滑动拼图和图文点选,验证码基本是强制展示——这意味着对所有用户一视同仁,必须输入。不过在赞助商眼中,“汝之毒药,吾之蜜糖”
可以说,reCAPTCHA是一个划时代的产品,如其官网所言:Tough on bots,Easy on humans,是另一种“一举两得”:既优化了用户体验,又推动了机器学习在工程领域的发展。笔者认为,这也是未来验证码这种自带反人类属性产品的发展方向——让普通用户和非法用户,看到两个不同的世界。
reCaptcha虽是免费,但受限于一些众所周知的原因,此产品并没有在国内得到广泛应用。如果在国内广泛应用,那可能google本身就不用墙了,这样一来,动的可不止是国内专业验证码公司的奶酪...所以还是看国内的验证码产品,如何紧跟黑科技老大的步伐吧。
接入方式
官网目前产品主要有两款:reCAPTCHA V2和Invisible reCAPTCHA
reCAPTCHA V2便是noCAPTCHA的最新版(V1版据说官方已不再维护),嵌入式复选框。
Invisible reCAPTCHA为之前提到的隐形验证码。在此只关注它的接入方式(其实和reCAPTCHA V2类似),也算是观摩学习业内标杆。
Invisible reCAPTCHA的调用方式有三种:
Automatically bind the challenge to a button
Programmatically bind the challenge to a button
Programmatically invoke the challenge
其中第1种比较简单,官网的说法是“The easiest method”——其实就是在已有的按钮元素上添加一些属性以绑定reCAPTCHA,由点击自动触发。示例如下:
reCAPTCHA demo: Simple page
这里比较有趣的是在第一个script使用的时候用到了async和defer属性。查阅资料发现,区别如下:
没有
defer或async,浏览器会立即加载并执行指定的脚本,“立即”指的是在渲染该script标签之下的文档元素之前,也就是说不等待后续载入的文档元素,读到就加载并执行。
有
async,加载和渲染后续文档元素的过程将和script.js的加载与执行并行进行(异步)。
有
defer,加载后续文档元素的过程将和script.js的加载并行进行(异步),但是script.js的执行要在所有元素解析完成之后,DOMContentLoaded事件触发之前完成。
一张图说明上面一段讲的是啥:

所以可以看出,最大的差别在于"脚本下载完之后何时执行"——显然
defer是最接近我们对于应用脚本加载和执行的要求的。
async对于应用脚本的用处不大,因为它完全不考虑依赖(哪怕是最低级的顺序执行),不过它对于那些可以不依赖任何脚本或不被任何脚本依赖的脚本来说却是非常合适的,最典型的例子:Google Analytics

那么问题来了。如果async和defer同时使用,会产生什么效果?
对此有专门的规范:
The defer attribute may be specified even if the async attribute is specified, to cause legacy Web browsers that only support defer (and not async) to fall back to the defer behavior instead of the synchronous blocking behavior that is the default.
意思是有些老浏览器就只支持defer不支持async,那么自然就达不到async的效果。这时就要用defer来fallback async,从而避免同步阻塞。
说完第1种,再来看看第2种:自己通过JS代码的方式控制一些属性的传入。示例如下:
reCAPTCHA demo: Explicit render after an onload callback
其中需要注意的是:由于顺序执行的原因,onloadCallback要写在前面,这样最后才能保证onload可以接收到
onloadCallback(否则 async and defer 也是白用了)
When your callback is executed, you can call thegrecaptcha.render
method from the Javascript API.Note: your onload callback function must be defined before the reCAPTCHA API loads. To ensure there are no race conditions:
- order your scripts with the callback first, and then reCAPTCHA
- use the async and defer parameters in thescript tags
第2种方式,代码量相对第1种多了许多,但是却做到了“不污染已有的html元素”
第3种方式,是分配一块页面空间给到reCAPTCHA,从而固定其展示的位置。因为Invisible reCAPTCHA的Invisible并不是绝对的——你可以通过调参使其visible。那么这样就可以秀出“我们是有用验证码的”。
隐形==不存在?不存在的
与第2种相比,同样没有污染已有元素,但是更加customised。示例如下:
注意这里的invoke不是使用render,而是execute。具体的api调用如下:



服务端的地方就不讨论,因为笔者这次主要是关注前端。但是服务端的东西,都大同小异:无非是需要特定的密钥,结合前端callback的内容做二次验证。原因是前端可以被绕过。
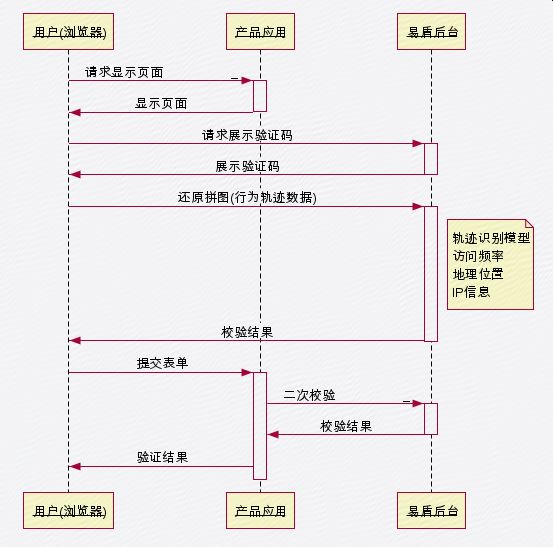
验证流程如下(这里借用网易易盾流程图。其实都差不多):
源码分析
其实不能叫源码——因为能看到的基本都经过压缩和混淆,可读性是非常差的。只能看出一个大概。
reCAPTCHA主要是用到了两个js:api.js和recaptcha__en.js。
都是用原生Js实现,这样不依赖任何框架或插件,对调用方的兼容性最好。
api.js是对外暴露的js,其内部会调用recaptcha__en.js。完整代码如下:
(function () {
if (!(window["___grecaptcha_cfg"])) {
window["___grecaptcha_cfg"] = {};
}
;
if (!(window["___grecaptcha_cfg"]["render"])) {
window["___grecaptcha_cfg"]["render"] = "onload";
}
;
window["__google_recaptcha_client"] = true;
var po = document.createElement("script");
po.type = "text/javascript";
po.async = true;
po.src = "https://www.gstatic.com/recaptcha/api2/r20170613131236/recaptcha__en.js";
var elem = document.querySelector("script[nonce]");
var nonce = elem && ((elem["nonce"]) || (elem.getAttribute("nonce")));
if (nonce) {
po.setAttribute("nonce", nonce);
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(po, s);
})();
其中可以看出,recaptcha__en.js是通过代码parentNode.insertBefore引入的。这样的写法有点类似一个Proxy,接入方可以不必关注具体是用的什么recaptcha__en.js来处理(从r20170613131236/recaptcha__en.js这种写法上看,这个js是有多版本的。很可能会动态变化)。
至于recaptcha__en.js,Idea美化后接近1w行... 加上可读性这座大山,很难短时间分析出太多有价值的东西,只能扫读,找到一些感兴趣的点。
例如笔者想到,reCAPTCHA在校验不通过的时候,一定会弹出常规验证码。那么Widget的内容一定在recaptcha__en.js中(除非再引用专门的Widget.js)。果然包含如下代码:
switch (u(c) ? c.toString() : c) {
case "tileselect":
case "multicaptcha":
var c = "", d = a.label;
switch (u(d) ? d.toString() : d) {
case "Turkeys":
c += "Select all squares with Turkeys.";
break;
case "GiftBoxes":
c += "Select all squares with gift boxes.";
break;
case "Fireworks":
c += "Select all squares with fireworks.";
break;
case "TileSelectionStreetSign":
c += "Select all squares with street signs.";
break;
case "TileSelectionBizView":
c += "Select all squares with business names.";
break;
case "stop_sign":
c += "Select all squares with stop signs.";
break;
case "vehicle":
case "/m/07yv9":
case "/m/0k4j":
c += "Select all squares with vehicles.";
break;
case "road":
case "/m/06gfj":
c += "Select all squares with roads.";
break;
case "house":
case "/m/03jm5":
c +=
"Select all squares with houses.";
break;
case "apparel_and_fashion":
c += "Select all squares with clothing.";
break;
case "bag":
c += "Select all squares with bags.";
break;
case "dress":
c += "Select all squares with dresses.";
break;
case "eye_glasses":
c += "Select all squares with eye glasses.";
break;
case "hat":
c += "Select all squares with hats.";
break;
case "pants":
c += "Select all squares with pants.";
break;
case "shirt":
c += "Select all squares with shirts.";
break;
case "shoe":
c += "Select all squares with shoes.";
break;
case "USER_DEFINED_STRONGLABEL":
c += "Select all squares that match the label: " + W(a.Ld) + ".";
break;
default:
c += "Select all images below that match the one on the right."
}
"multicaptcha" == a.ie && (c += '
If there are none, click skip.');
a = V(c);
b += a;
break;
default:
c = "";
d = a.label;
switch (u(d) ?
d.toString() : d) {
case "romantic":
c += "Select all images that feel romantic for dining.";
break;
case "outdoor_seating_area":
c += "Select all images with outdoor seating areas.";
break;
case "indoor_seating_area":
c += "Select all images with indoor seating areas.";
break;
……//省略类似代码
default:
d = "Select all images that match the label: " + (W(a.Ld) + "."), c += d
}
"dynamic" == a.ie && (c += "
Click verify once there are none left.");
a = V(c);
b += a
}
问题都是固定的,配以的应该是随机的同名却不同内容的图片。
那么就可以推测,这个js应该包含各类验证码的集合。于是发现:
var Fo = function (a) {
switch (a) {
case "default":
return new On;
case "nocaptcha":
return new yo;
case "imageselect":
return new Bn;
case "tileselect":
return new Bn("tileselect");
case "dynamic":
return new Wn;
case "audio":
return new mn;
case "text":
return new Do;
case "multicaptcha":
return new Sn;
case "canvas":
return new Jn;
case "coref":
return new no;
case "prepositional":
return new vo
}
};
所以Google的"军备库"还是很丰富的——甚至远多于国内的验证码公司。每一项是什么不得而知,但能看出有音频和点选。这近1w行代码,可能是一个整包。验证码本身还是有难易之分的,推测Google是靠行为分析来展示出不同难度的验证码给robots。
进而再想到,行为分析一定要收集浏览器信息,或者常用设备,那么必须要用到userAgent。搜索发现,确实有一处:
a:{
var tb = k.navigator;
if (tb) {
var ub = tb.userAgent;
if (ub) {
sb = ub;
break a
}
}
sb = ""
}
但具体如何使用,就需要花时间研究了。有兴趣的读者可以分析一下,欢迎交流。
总结
同国内验证码产品相比,Google reCAPTCHA在接入上,并不强调产品的形态(点选 、滑动等),而是侧重接入的灵活程度。具体的形态由“风险分析引擎”得出,动态展示给调用方。在这想起李小龙的武术哲学:
以无法为有法,以无限为有限
截拳道包罗万象,却不被万象所包罗。Google reCAPTCHA也有点这个意思——大概这就是所谓的强者姿态。