Kubernetes源码学习-Scheduler-P2-调度器框架
调度器框架
前言
在上一篇文档中,我们找到了sheduler调度功能主逻辑的入口:
P1-调度器入口篇
那么在本篇,我们基于找到的入口,来进入调度器框架内部,看一看整体的逻辑流程,本篇先跳过调度的算法(Predicates断言选择、Priority优先级排序),只关注pkg/scheduler目录内的scheduler框架相关的逻辑流向,摸清scheduler框架本身的代码结构,调度算法留在后面的文章再谈
框架流程
回顾上一篇篇末,我们找到了调度框架的实际调度工作逻辑的入口位置,pkg/scheduler/scheduler.go:435, scheduleOne()函数内部,定位在pkg/scheduler/scheduler.go:457位置,是通过这个sched.schedule(pod)方法来获取与pod匹配的node的,我们直接跳转2次,来到了这里pkg/scheduler/core/generic_scheduler.go:107



通过注释可以知道,ScheduleAlgorithm interface中的Schedule方法就是用来为pod筛选node的,但这是个接口方法,并不是实际调用的,我们稍微往下,在pkg/scheduler/core/generic_scheduler.go:162这个位置,就可以找到实际调用的Schedule方法:

这个函数里面有4个重要的步骤:
// 调度前预先检查pvc是否创建
pkg/scheduler/core/generic_scheduler.go:166
err := podPassesBasicChecks(pod, g.pvcLister)
// 根据Predicate筛选node
pkg/scheduler/core/generic_scheduler.go:184
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
// 给筛选出的node排出优先级
pkg/scheduler/core/generic_scheduler.go:215
PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
// 选出优先级最高的node作为fit node
pkg/scheduler/core/generic_scheduler.go:226
g.selectHost(priorityList)
本篇我们不看Schedule方法内的具体调度算法细节,在这里标记一下,下一篇我们将从这里开始.
先来逆向回溯代码结构,找到哪里创建了scheduler,调度器的默认初始化配置,默认的调度算法来源等等框架相关的东西。Schedule()方法属于genericScheduler结构体,先查看genericScheduler结构体,再选中结构体名称,crtl + b组合键查看它在哪些地方被引用,找出创建结构体的位置:
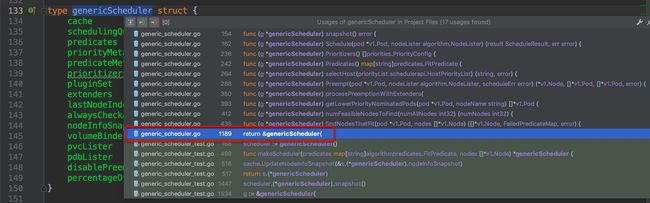
通过缩略代码框,排除test相关的测试文件,很容易找出创建结构体的地方位于pkg/scheduler/core/generic_scheduler.go:1189,点击图中红框圈中位置,跳转过去,果然找到了NewGenericScheduler()方法,这个方法是用来创建一个genericScheduler对象的,那么我们再次crtl + b组合键查看NewGenericScheduler再什么地方被调用:
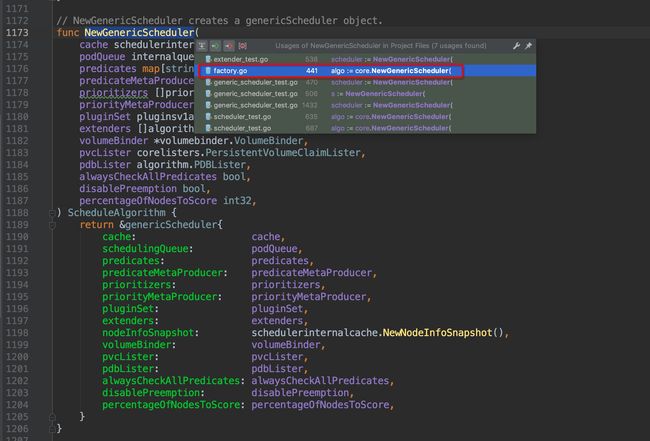
找出了在pkg/scheduler/factory/factory.go:441这个位置上找到了调用入口,这里位于CreateFromKeys()方法中,继续crtl + b查看它的引用,跳转到pkg/scheduler/factory/factory.go:336这个位置:


这里找到了algorithmProviderMap这个变量,顾名思义,这个变量里面包含的应该就是调度算法的来源,点击进去查看,跳转到了pkg/scheduler/factory/plugins.go:86这个位置,组合键查看引用,一眼就可以看出哪个引用为这个map添加了元素:

跳转过去,来到了pkg/scheduler/factory/plugins.go:391这个位置,这个函数的作用是为scheduler的配置指定调度算法,即FitPredicate、Priority这两个算法需要用到的metric或者方法,再次请出组合键,查找哪个地方调用了这个方法:

来到了pkg/scheduler/algorithmprovider/defaults/defaults.go:99,继续组合键向上查找引用,这次引用只有一个,没有弹窗直接跳转过去了pkg/scheduler/algorithmprovider/defaults/defaults.go:36:


我们来看看defaultPredicates(), defaultPriorities()这两个函数具体的内容:

我们随便点击进去一个predicates选项查看其内容:
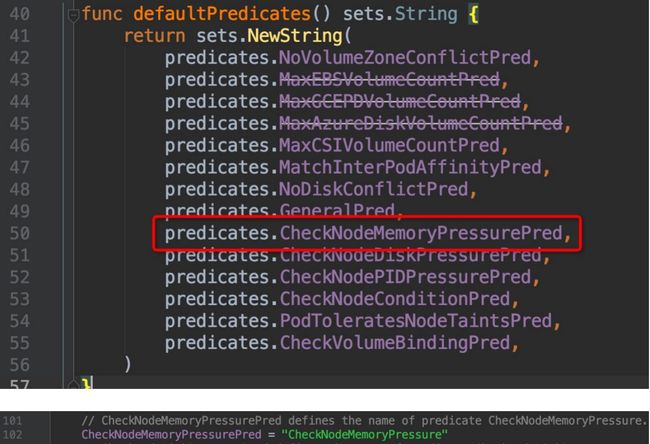
CheckNodeMemoryPressure这个词相应熟悉kubernetes 应用的朋友一定不会陌生,例如在node内存压力大无法调度的pod时,kubectl describe pod xxx就会在状态信息里面看到这个关键词。
让我们回到pkg/scheduler/algorithmprovider/defaults/defaults.go:102这个位置,查看factory.RegisterAlgorithmProvider(factory.DefaultProvider, predSet, priSet)方法的详情,可以看到参数factory.DefaultProvider值为字符串格式的DefaultProvider,先记住这个关键值,进入方法内部:
pkg/scheduler/factory/plugins.go:387:
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys sets.String) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
algorithmProviderMap[name] = AlgorithmProviderConfig{
FitPredicateKeys: predicateKeys,
PriorityFunctionKeys: priorityKeys,
}
return name
}
可以看到,这个方法为DefaultProvider绑定了配置:筛选算法和优先级排序算法的key集合,这些key只是字符串,那么是怎么具体落实到计算的方法过程上去的呢?让我们看看pkg/scheduler/algorithmprovider/defaults/目录下的register_predicates.go,register_priorities.go这两个文件:

它们同样也在init()函数中初始化时使用factory.RegisterFitPredicate()方法做了一些注册操作,这个方法的两个参数,前一个是筛选/计算优先级 的关键key名,后一个是具体计算的功能实现方法,点击factory.RegisterFitPredicate()方法,深入一级,查看内部代码,
// RegisterFitPredicateFactory registers a fit predicate factory with the
// algorithm registry. Returns the name with which the predicate was registered.
func RegisterFitPredicateFactory(name string, predicateFactory FitPredicateFactory) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
fitPredicateMap[name] = predicateFactory
return name
}
可以看出,两者使用map[string]func()的方式关联在了一起,那么在后面实际调用的时候,必定是在map中基于key找出方法并执行。优先级相关的factory.RegisterPriorityFunction2()方法亦是同理。
生成默认配置
还记得刚刚重点圈出的DefaultProvider关键值吗?通过上面我们知道了,所有默认Predicate/priority算法的实现都是绑定在这个默认的AlgorithmProvider身上的,那么,启动scheduler的时候,究竟是如何将DefaultProvider作为默认AlgorithmProvider呢?让我们回到最初的调度器启动命令入口位置cmd/kube-scheduler/app/server.go:62:
opts, err := options.NewOptions()
// 点击NewOptions跳转进入内部,来到了这个位置:cmd/kube-scheduler/app/options/options.go:75
func NewOptions() (*Options, error) {
cfg, err := newDefaultComponentConfig()
if err != nil {
return nil, err
}
... // 省略
}
// 这个newDefaultComponentConfig方法特别有意思,从字面看它是用来为组件填充默认配置的
// 来看看它的内容,点击来到了cmd/kube-scheduler/app/options/options.go:132
func newDefaultComponentConfig() (*kubeschedulerconfig.KubeSchedulerConfiguration, error) {
cfgv1alpha1 := kubeschedulerconfigv1alpha1.KubeSchedulerConfiguration{}
kubeschedulerscheme.Scheme.Default(&cfgv1alpha1)
... // 省略
}
// 点击kubeschedulerscheme.Scheme.Default(&cfgv1alpha1)中的Default跳转进入
// 来到了这里:vendor/k8s.io/apimachinery/pkg/runtime/scheme.go:389
func (s *Scheme) AddTypeDefaultingFunc(srcType Object, fn func(interface{})) {
s.defaulterFuncs[reflect.TypeOf(srcType)] = fn
}
// Default sets defaults on the provided Object.
func (s *Scheme) Default(src Object) {
if fn, ok := s.defaulterFuncs[reflect.TypeOf(src)]; ok {
fn(src)
}
}
// 看看defaulterFuncs的数据类型:
// defaulterFuncs is an array of interfaces to be called with an object to provide defaulting
// the provided object must be a pointer.
defaulterFuncs map[reflect.Type]func(interface{})
// 不难看出,这个Default()方法是通过反射器,获取对象的类型,以类型作为map的key,从而获取该类型
// 对应的defaulterFuncs,也即是该结构体填充默认配置的方法,最后执行该方法
// 那么这个defaulterFuncs map[reflect.Type]func(interface{}),里面的元素时怎么填充的呢?
// 作者很贴心地将添加map元素的方法写在了Default()方法的正上方:
func (s *Scheme) AddTypeDefaultingFunc(srcType Object, fn func(interface{})) {
s.defaulterFuncs[reflect.TypeOf(srcType)] = fn
}
我们选中然后ctrl+b,查找AddTypeDefaultingFunc()的引用,弹窗中你可以看到有非常非常多的对象都引用了该方法,这些不同类型的对象相信无一例外都是通过Default()方法来生成默认配置的,我们找到其中的包含scheduler的方法:
跳转进去,来到了这个位置pkg/scheduler/apis/config/v1alpha1/zz_generated.defaults.go:31(原谅我的灵魂笔法):

进入SetDefaults_KubeSchedulerConfiguration(),来到pkg/scheduler/apis/config/v1alpha1/defaults.go:42:
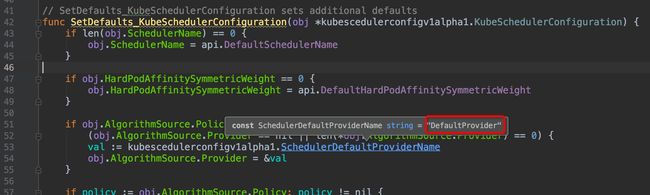
看到了DefaultProvider吗?是不是觉得瞬间豁然开朗,原来是在这里调用指定了scheduler配置的AlgorithmSource.Provider。
调度功能实现的回溯
让我们捋一捋调度器框架运行调度功能相关的流程:
// 1.获取AlgorithmSource.Provider(默认"DefaultProvider"),作为key从map中获取到pkg/scheduler/algorithmprovider包内为其初始化的两种算法key集合
algorithmProviderMap[name] = AlgorithmProviderConfig{
FitPredicateKeys: predicateKeys,
PriorityFunctionKeys: priorityKeys,
}
// 2.填充genericScheduler对象的predicates元素:
// pkg/scheduler/factory/plugins.go:411
func getFitPredicateFunctions(names sets.String, args PluginFactoryArgs) (map[string]predicates.FitPredicate, error) {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
fitPredicates := map[string]predicates.FitPredicate{}
for _, name := range names.List() {
factory, ok := fitPredicateMap[name]
if !ok {
return nil, fmt.Errorf("invalid predicate name %q specified - no corresponding function found", name)
}
fitPredicates[name] = factory(args)
}
// Always include mandatory fit predicates.
for name := range mandatoryFitPredicates {
if factory, found := fitPredicateMap[name]; found {
fitPredicates[name] = factory(args)
}
}
return fitPredicates, nil
}
// 3.对predicates内的每一个key,找到对应的检查方法,执行每一项检查,返回检查结果
// pkg/scheduler/core/generic_scheduler.go:608
func podFitsOnNode(
pod *v1.Pod,
meta predicates.PredicateMetadata,
info *schedulernodeinfo.NodeInfo,
predicateFuncs map[string]predicates.FitPredicate,
queue internalqueue.SchedulingQueue,
alwaysCheckAllPredicates bool,
) (bool, []predicates.PredicateFailureReason, error) {
var failedPredicates []predicates.PredicateFailureReason
podsAdded := false
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
if i == 0 {
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
for _, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []predicates.PredicateFailureReason
err error
)
if predicate, exist := predicateFuncs[predicateKey]; exist {
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
if err != nil {
return false, []predicates.PredicateFailureReason{}, err
}
... // 省略
}
}
}
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}
目录结构总结
最后,对pkg/scheduler路径下的各子目录的功能来一个图文总结吧:
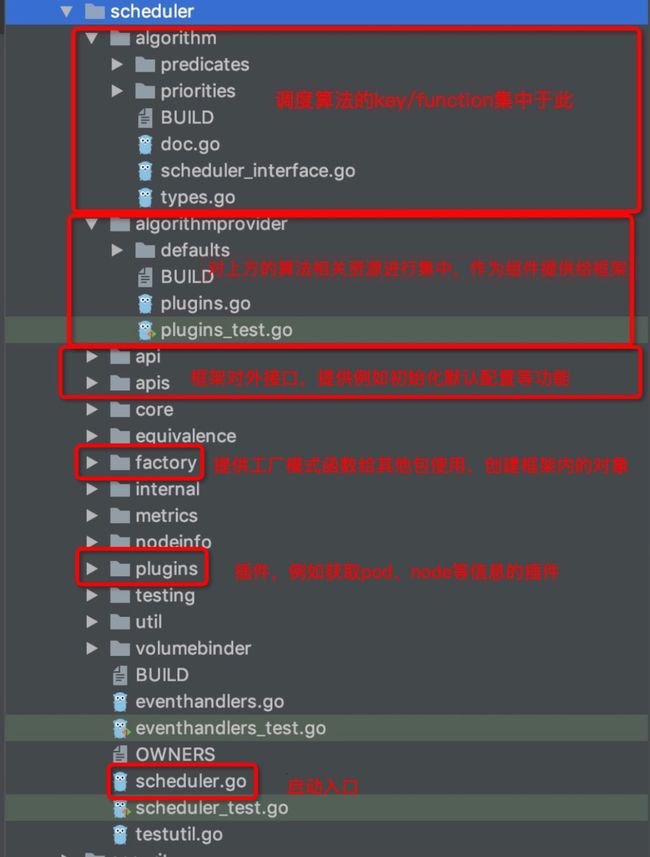
Last
如果有沉下心来阅读代码,结合上面的图文讲解、代码块中的中文注释,相信你对调度器框架包内的代码结构会有一个较为清晰的整体掌握,本篇框架篇到此结束,下一篇来谈谈详细的调度算法的细节