深度学习之PSPnet用于语义分割
工程主页:https://github.com/hszhao/PSPNet
1 摘要
- rank 1 on PASCAL VOC 2012 等多个benchmark(信息截止2016.12.16)
http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?cls=mean&challengeid=11&compid=6&submid=8822#KEY_PSPNet - 利用了global context information by different-region-based context aggregation (借助金字塔池化)
1 Introduction
dataset :
LMO dataset [22]
PASCAL context datasets [8, 29]
ADE20K dataset [43]
主流的场景解析算法基于FCN(全卷积网络),存在的问题是没有利用整体的场景信息
本文提出的是 pyramid scene parsing network (PSPNet)
基于dilated FCN [3,40] ,(pixel-level )
主要贡献:
提出pyramid scene parsing network
提出effective optimization strategy for deep ResNet [13] based on deeply supervised loss
建立一个系统
2 相关工作
发展过程:先是将FC换成了conv,再是提出了dilated conv[3,40] , deconvolution实现的从粗到细[30]
本文的工作是基于FCN和dilated work【3,26】
相关工作一路是基于多尺度(因为高层一般对应的是语义信息而低层对应的事位置信息),另一路是structure prediction[3],采用CRF作为后处理。
[24] 指出global average pooling with FCN 可以改善分割效果,但本文发现在复杂场景下并不有效,因此提出了different-region-based context aggregation。
3 Pyramid Scene Parsing Network
基本框架:
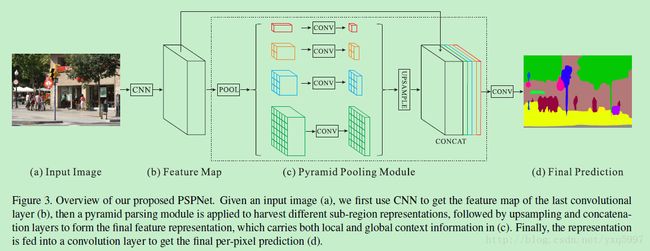
全局平均池化[ 34,13,24] 仍有一定的局限。
金字塔池化模块:4层
最粗的一层是global pooling,得到一个single bin,其他的层得到的是sub-region,这样池化之后得到的feature map是不同尺寸的。
接下来对每个金字塔level 做一个一个1*1 卷积,将context representation的维度变成原来的1/N,N是金字塔的层数。
然后直接对低维的feature map进行上采样,得到原图尺寸。
最后,不同层的feature连接后经过卷积conv输出。
3.3 网络架构
采用一个pre-trained网络ResNet [13],并加入dilated network来提取feature map,得到的feature map的尺寸是原始图的1/8(这在Deeplab在解释过)。
采用4层金字塔模型,最后通过卷积后连接起来。
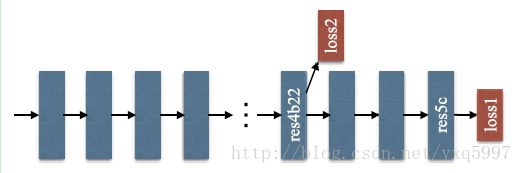
4 Deep Supervision for ResNet-Based FCN
大家都知道残差网络借助skip conntection来减小深层网络的一些优化问题,后面的层主要是学习前面的层的残差。
而本篇工作,作者提出加入一个额外的loss,and learning the residue afterwards with the final loss.(还不是很理解) 这样网络可分为两个相对简单的优化部分了。
5 实验
5.1 实现
基于Caffe
-“poly” learning rate policy : (1-iter/maxiter)^power
其中base lr=0.01 power=0.9
- Momentum =0.9
- weight decay=0.0001
- data augmentation:随机镜像,resize(0.5~2),旋转:-10~10°
- batchsize:16
- auxiliary loss: weight=0.4
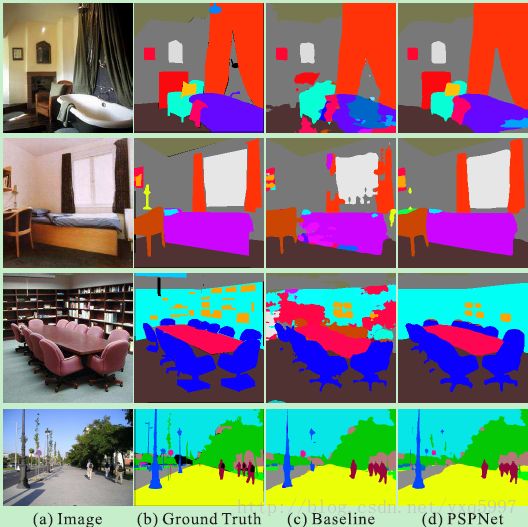
效果杠杠的。
参考文献
[3] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. CoRR, abs/1412.7062, 2014.
[4] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected
crfs. CoRR, abs/1606.00915, 2016. 5
[12] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, pages 346–361, 2014. 1, 3
[24] W. Liu, A. Rabinovich, and A. C. Berg. Parsenet: Looking wider to see better. CoRR, abs/1506.04579, 2015
[26] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015
[40] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. CoRR, abs/1511.07122, 2015