ConcurrentHashMap源码笔记(jdk8)
理解了jdk8 HashMap的源码再来理解ConcurrentHashMap事半功倍,HashMap传送门:https://blog.csdn.net/yzh_1346983557/article/details/105456563
一、ConcurrentHashMap的数据结构图
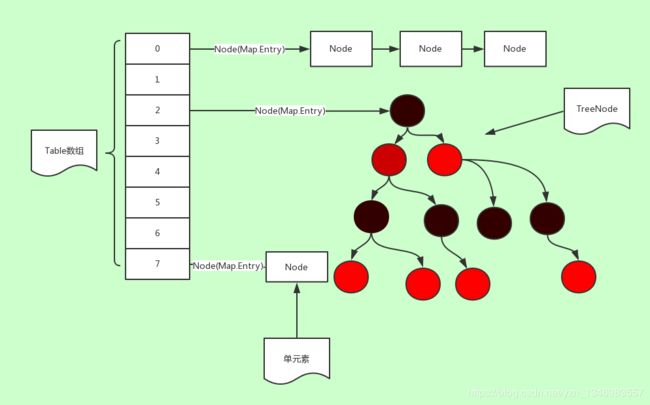
可发现ConcurrentHashMap的数据结构和jdk1.8的HashMap的数据结构基本相同,ConcurrentHashMap实现时极大参考了HashMap的实现。
二、ConcurrentHashMap的成员变量
重点关注核心成员变量transient volatile Node
// Node数组最大容量(2^30=1073741824)
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认初始值(必须是2的幕数)
private static final int DEFAULT_CAPACITY = 16;
// 数组可能最大值
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 并发级别,遗留下来的,为兼容以前的版本
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 负载因子
private static final float LOAD_FACTOR = 0.75f;
// 链表转红黑树阀值( > 8 链表转换为红黑树)
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转链表阀值,小于等于6
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
private static final int MIN_TRANSFER_STRIDE = 16;
private static int RESIZE_STAMP_BITS = 16;
// 2^15-1,help resize的最大线程数
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 32-16=16,sizeCtl中记录size大小的偏移量
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// forwarding nodes的hash值
static final int MOVED = -1;
// 树根节点的hash值
static final int TREEBIN = -2;
// ReservationNode的hash值
static final int RESERVED = -3;
// 可用处理器数量
static final int NCPU = Runtime.getRuntime().availableProcessors();
//存放Node的数组,实际存放数据的地方
transient volatile Node[] table;
/**
*控制标识符,用来控制table数组的初始化和扩容的操作,不同的值有不同的含义
*当为负数时:-1代表正在初始化,-N代表有N-1个线程正在 进行扩容
*当为0时:代表当时的table还没有被初始化
*当为正数时:表示初始化或者下一次进行扩容的大小
*/
private transient volatile int sizeCtl;
//... 三、ConcurrentHashMap的静态内部类Node
static class Node implements Map.Entry {
final int hash;
final K key;//final修饰,不可修改
volatile V val;//volatile修饰,保证并发修改时的可见性
volatile Node next;//volatile修饰,保证并发修改时的可见性
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
} 对比就可发现ConcurrentHashMap的Node结构和HashMap的Node结构基本相同,维护了4个成员变量且成员变量的含义都是相同的,只不过val、next添加了volatile修饰,保证并发修改时数据的可见性。
四、ConcurrentHashMap的构造函数
public ConcurrentHashMap() {
}这里只看一下常使用的无参构造函数,可发现它啥都没有做,即所有成员变量使用其类型默认值。其它4个构造函数不再分析。
五、ConcurrentHashMap.put()方法
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//通过key的原始hashCode计算出Node中的hash值
int hash = spread(key.hashCode());
int binCount = 0;
//一直迭代执行,相当于while(true)
//因为在table的初始化和casTabAt用到了compareAndSwapInt、compareAndSwapObject,并发执行可能会失败,所以这边要加一个for循环,不断的尝试
for (Node[] tab = table; ; ) {
//f:tab[i]对应的链表(或二叉树)首节点
Node f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//table数组未初始化,去初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//i:tab[]数组的下标i,f:tab[i]对应的节点Node对象
//f == null,即当前节点尚未存储数据,直接new Node放入数组tab[i]处(CAS放入)
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
//结束循环
break; // no lock when adding to empty bin
} else if ((fh = f.hash) == MOVED)
//f != null,即当前节点已存储的有数据且hash值为-1,说明该链表正在进行transfer(转移)操作,帮助完成transfer,返回扩容完成后的table。
tab = helpTransfer(tab, f);//helpTransfer():Helps transfer if a resize is in progress.
else {
//f != null且hash值不为-1,即当前节点已存储的有数据且不是正在扩容中
V oldVal = null;
/**
* tab[i]的首节点进行加锁操作,保证并发put()线程安全。不是jdk1.7的segment加锁,Segment extends ReentrantLock
* 用synchronized,不用1.7中CAS锁ReentrantLock原因(主要是1、2):
* 1.只对tab[i]的首节点加锁,锁粒度低。
* 2.1.8的jvm对synchronized执行有优化。低粒度锁时性能可相当CAS锁。CAS锁主要结合Condition,在粗粒度锁时完成细粒度控制方面更优.
* 3.直接用jdk提供的关键字synchronized,在jvm运行时内存分配可能比CAS锁new对象优。
*/
synchronized (f) {
if (tabAt(tab, i) == f) {//再次判断f是否为tab[i]的首节点
if (fh >= 0) {//如果f.hash >= 0,链表结构
binCount = 1;
for (Node e = f; ; ++binCount) {
K ek;
//如果在链表中找到键为key的节点e,用新值覆盖旧值:e.val = value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;//结束循环
}
//如果在链表中不存在键为key的节点e
Node pred = e;//记录当前节点e为上一节点pred
if ((e = e.next) == null) {//更新e = e.next后,如果e为空
//new Node赋予上一节点pred的next
pred.next = new Node(hash, key,
value, null);
break;//结束循环
}
//e.next != null,继续迭代(已更新e = e.next)
}
} else if (f instanceof TreeBin) {
//如果f属于红黑树类型
ConcurrentHashMap.Node p;
binCount = 2;
//调用树的putTreeVal(),将key、value加入树节点中
if ((p = ((TreeBin) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//新节点加入完成后
if (binCount != 0) {
//如果链表长度超过8,将链表转为树treeifyBin().(等于8时不会)
//注意if (fh >= 0)里binCount的计算,binCount初始从1开始计数
//假设当前链表长度为7,迭代到最后一个节点时binCount=7,e.next为null,new Node加入链表后break了,这时链表长度为8但是binCount=7
//所以binCount=8时,链表实际长度是9
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;//结束外部循环体
}
}
}
// 计数count加1,如果表太小且还没有resize,则启动传输transfer操作(扩容)
addCount(1L, binCount);
return null;
}
/**
* 计算出Node中key的hash值
* 位运算,无符号右移16位后 位非 自己,最后 位与 0x7fffffff
* 0x表16进制,每个十六进制数4bit位,因此8个16进制是4个byte字节,刚好是一个int整型
* F的二进制码为 1111,7的二进制码为 0111,这样一来,整个整数 0x7FFFFFFF 的二进制表示就是除了首位是 0,其余都是1。
* 就是说,0x7fffffff是最大的整型数 int(因为第一位是符号位,0 表示正数),即Integer.MAX_VALUE=0x7fffffff=2^31 -1
* 让h的高位也参与了hash值计算,减少了hash碰撞
*/
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
//初始化table数组
private final Node[] initTable() {
Node[] tab;
int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//compareAndSwapInt:CAS操作,乐观锁,Unsafe类的native本地方法,并发执行时只有一个线程能执行成功
//sizeCtl >= 0
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//初始容量16
@SuppressWarnings("unchecked")
Node[] nt = (Node[]) new Node[n];//new一个大小为16的Node数组
table = tab = nt;//新Node数组赋予成员变量table
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;//返回新Node数组
}
//根据下标i得到tab[i]的Node对象
static final Node tabAt(Node[] tab, int i) {
return (Node) U.getObjectVolatile(tab, ((long) i << ASHIFT) + ABASE);//getObjectVolatile:CAS操作,Unsafe类的本地方法
}
//将新Node对象v放入tab[i]处
static final boolean casTabAt(Node[] tab, int i,
Node c, Node v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);//compareAndSwapObject:CAS操作
} 总结:通过源码可发现,jdk1.8ConcurrentHashMap的put()操作是基于一系列的CAS(乐观锁)和synchronized锁住数组table[i]的首节点完成并发的线程安全性。摒弃了jdk1.7ConcurrentHashMap中segment数组的分段锁思想。1.7是segment[]+HashEntry[]+链表,双数组加单链表的数据结构。1.8是Node[]+链表+红黑树,数组加单链表加红黑树(链表长度大于8时)的数据结构。
六、ConcurrentHashMap.get()方法
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
//计算key的hash值
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {//根据hash计算出下标i,定位到e = tab[i]
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
//tab[i]链表首节点定位到直接返回值
return e.val;
}
else if (eh < 0)
//二叉树定位
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
//链表遍历定位
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
} 看懂了put()再来看get(),就很容易理解了:
计算 key 的 hash 值;
根据 hash 值计算出数组下标i,根据i得到tab[i]对象;
tab[i]链表(或二叉树)首节点是否刚好匹配,是则返回首节点value;
如果不匹配,判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据;
如果不是二叉树,遍历链表,直到找到相等(==或equals)的 key。