美国高校开源迄今为止最大新冠肺炎CT数据集!
点击上方“视学算法”,选择“星标”
快速获得最新干货
本文转载自:新智元
编辑:元子、白峰
【导读】胸部计算机断层扫描(CT)图像在对新冠肺炎(COVID-19)提供准确、快速、廉价的筛查和检测方面很有前景。在本文中,研究团队构建了一个开源的COVID-CT数据集,其中包含275个COVID-19检测呈阳性的CT图像,有助于使用深度学习方法分析病人的CT图像并预测其是否患有新冠的相关研究和发展。
胸部计算机断层扫描(CT)图像在对新冠肺炎(COVID-19)提供准确、快速、廉价的筛查和检测方面很有前景。
在本文中,研究者构建了一个开源的COVID-CT数据集,其中包含275个COVID-19检测呈阳性的CT图像,有助于使用深度学习方法分析病人的CT图像并预测其是否患有新冠的相关研究和发展。
研究者在该数据集上训练了一个深度卷积神经网络,F1值达到0.85,这个结果达到了研究团队的期待,但仍需进一步改进。
相关数据和代码:
https://github.com/UCSD-AI4H/COVID-CT
核酸检测的最大问题:速度慢且稀缺,追不上新冠肺炎的传播速度
截至2020年3月30日,在全世界范围内已有775306人感染新冠肺炎,37083人死亡。对此疾病检测的低效和缺乏成为控制其传播的主要障碍。
目前的检测主要基于逆转录聚合酶链反应(RT-PCR),需要4到6个小时才能获得结果。与新冠肺炎可怕的传播速度相比,这远不够快。除了效率低下之外,RT-PCR检测试剂盒也非常短缺。
这促使研究团队去研究替代的检测方式。这些方式可能更快,比RT-PCR便宜,更容易获得,但与RT-PCR一样准确。在众多可能性中,研究团队对CT图像尤其感兴趣。
有几篇著作研究了CT图像在筛选和检测新冠肺炎时的效果,结果鼓舞人心。然而,出于对隐私的保护,这些研究中所使用的CT图像并不会公之于众,这极大地阻碍了基于CT图像的精准检测新冠肺炎先进人工智能方法的研发。
构建COVID-CT数据集,训练深度学习模型诊断新冠肺炎
为了解决这个问题,研究团队构建了一个COVID-CT数据集,其中包含275个新冠肺炎检测呈阳性的CT图像,并向公众开放,以助于基于CT图像的新冠肺炎检测的研发。
研究团队从760个关于新冠肺炎的medRxiv和bioRxiv预印本中提取了 CT图像,并通过阅读这些图像的标题人工筛选出具有新冠肺炎临床病症的图像。基于183个新冠肺炎 CT图像和146个非新冠肺炎 CT图像,研究团队训练了一个深度学习模型,以预测一个CT图像是否呈新冠肺炎阳性。
在35个新冠肺炎 CT图像和34个非新冠肺炎 CT图像上进行了测试,研究团队的模型F1值为0.85。结果表明,CT扫描有望用于筛选和检测新冠肺炎,然而还需要更先进的方法来进一步提高准确性。
确诊新冠肺炎的患者入院时的CT图像。
A,2020年2月2日,一名39岁男性的胸部CT扫描结果,显示双侧毛玻璃混浊。
B,2020年2月6日,一名45岁男性的胸部CT扫描结果,显示双侧毛玻璃混浊。
C,2020年1月27日,一名48岁男性(在治疗后第9天出院)的胸部CT扫描结果,显示斑片状阴影。
D,2020年1月23日,一名34岁男性(在治疗后第11天出院)的胸部CT扫描结果,显示斑片状阴影。
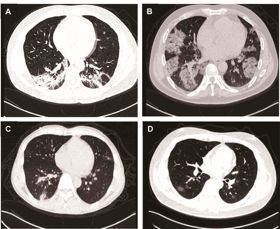
图1:对于包含多个CT子图像的图像,研究团队将其手动拆分为单个CT图像。
如何创建数据集
在本节中,研究团队描述了如何构建COVID-CT数据集。研究团队首先收集了760个于1月19日 至3月25日期间在medRxiv1和bioRxiv2上发布的的关于新冠肺炎的预印本。
这些预印本中有许多报告了新冠患者病例并且其中一些展示了患者的CT图像。
这些 CT图像附有描述其临床病症的标题。研究团队使用了PyMuPDF3提取预印本PDF文件的底层结构信息并定位到所有嵌入的图表。这些图表的质量(包括分辨率,大小等)大都保存完好。
根据结构信息,研究团队还识别出所有图表的标题。基于提取的图表和标题,研究团队首先手动选出所有CT扫描图像。
然后对于每个CT图像,阅读其对应的标题从而判断它对新冠肺炎是否呈阳性。如果无法通过标题判断,则在预印本中找到分析此图的文字以做出决定。对于包含多个CT子图像的图像,研究团队将其手动拆分为单个CT图像,如图1所示。
最后,研究团队获得了27个CT扫描图像,标记为新冠肺炎阳性。这些图像大小不同,最小,平均和最大高度分别为153、491和1853;最小,平均和最大宽度分别为124、383和1485。这些扫描来自143例患者。图2 显示了新冠肺炎CT扫描图像的一些示例。
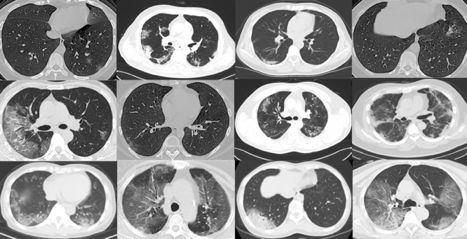
图2:新冠肺炎阳性的CT扫描图像示例
两种方式:迁移学习和数据扩充
研究团队基于这个数据集开发了一个基线方法,希望有兴趣的学者可以对其进行基准测试。
尽管研究团队所使用的关于新冠肺炎的CT图像数据集是目前最大的公开可使用的CT图像数据集,然而它依旧较难达到训练模型所需的数据量。
因为在如此小的数据集上训练深度学习模型十分容易导致过度拟合:模型在训练数据上表现良好,但是在测试数据上泛化不理想。因此,研究团队采用了两种不同的方法来解决这个问题:迁移学习和数据扩充。
其中,迁移学习的目的是利用来自相关领域的大量数据来辅助模型的训练与学习。具体来说,研究团队使用大量的胸部X光图像来预先训练一个深度卷积神经网络,然后在COVID-CT数据集上对训练好的网络进行微调。
数据扩充的目的是组合近似正确的图像-标签组,例如,在大多数组合的图像标签组中,标签是对图像的正确注释。
迁移学习
为了解决训练数据不足的问题,研究团队采用了迁移学习的方法。具体来讲,研究团队使用NIH发布的ChestX-ray14 数据集来预训练DenseNet,然后在COVID-CT数据集上对预训练后的DenseNet进行微调。
数据扩充
另一种解决数据不足的方法是数据扩充:即从有限的训练数据中,创建新的图像-标签组,并将合成后的组添加到原本的训练集中。在创建新的组时,研究团队采用了随机仿射变换、随机裁剪和翻转来扩充每个训练图像。随机仿射变换包括平移和旋转(角度依次为5,15,25)。
实验设计以及结果
研究团队收集了195个检测新冠肺炎呈阴性的CT扫描数据,来训练一个二分类模型用于预测一个CT图像是新冠阳性还是阴性。
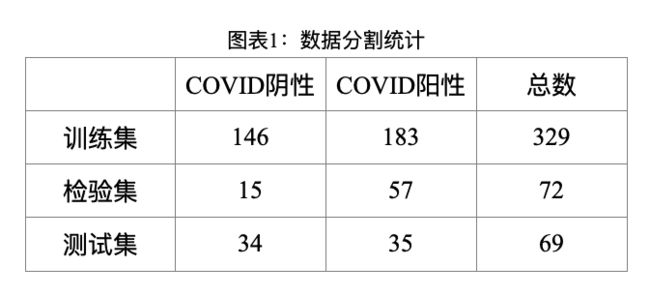
其中,研究团队根据患者数据将其分为训练集,检验集和测试集,图表1总结了每个数据集中新冠阳性和新冠阴性图像的数量,每个CT图像的大小都调整为224*224,并通过验证集对超参数进行调优。
再者,通过使用学习率为0.0001,余弦调度和最小批处理大小为4的Adam,研究团队对网络中的权重参数进行了优化。最后,研究团队使用五个指标来评估研究团队的方法:(1)准确性; (2)精度; (3)召回率; (4)F1指数; (5)ROC曲线面积(AUC)。对于这些指标,越高越好。
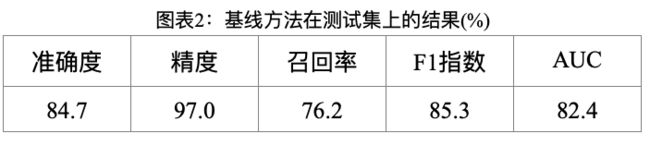
上图展示了这个基线方法的准确度、精密度、召回率、F1指数和AUC。尽管精度较高,然而召回率的结果并不令人满意,因此,需要使用更先进的方法来提高召回率。
总结
研究团队建立了一个关于新冠肺炎的公开CT扫描数据集,来促进通过读取CT图像进而筛选和检测新冠肺炎患者的AI技术的发展。
此数据集包含275个CT扫描结果为阳性的新冠肺炎患者的CT图像。
研究团队使用该数据集训练了一个深度学习模型,并获得了0.85的F1值。下一步,研究团队将继续改进方法以达到更好的精度。
论文链接:
https://arxiv.org/abs/2003.13865
数据集:
https://github.com/UCSD-AI4H/COVID-CT