小型三维引擎设计实现-渲染层的设计总结
1 设计目标:
1.1: 易于开发,对渲染API做抽象,向上层提供更容易使用的接口, 另外还可以扩充渲染API功能,比如增加自定义GLSL常量, GLSL结构体,GLSL公用函数,自定义GLSL uniforms, 并在每帧渲染时自动拼凑成完整的GLSL代码,并自动为GLSL uniforms赋值, 对上层开发提供了便利性。
1.2: 可移植性,一方面呢可以支持Linux上的OpenGL, 移动平台的OpenGLES。 另外还要能够轻松的升级到新版本,比如 GL3.x 升级至GL4.x。 同时呢还要支持一些新的API扩展, 比如从GL uniforms 到 uniform buffers。但是目前暂时不支持Windows上的Driect3D,因为同时支持Direct3D 和 OpenGL 会对代码抽象产生一定影响, 一个主要问题是Direct3D的HLSL和OpenGL的GLSL,要维护两个版本,虽然这两个着色语言很相似,可以在运行时转换。
1.3: 灵活性,渲染层可以针对不同硬件进行单独的处理,不影响上层使用, 比如在某些硬件上显示列表比VBO更有效率,或者发现一个驱动的bug,这样就可以在渲染层中插入一段代码,进行处理。
1.4:健壮性,渲染层可以提供统计信息或者辅助调试工具,提高整个程序的稳定性,比如统计每帧的draw calls和三角面片数量,保持帧缓冲区内容,显示GL状态,或者用glGetError获取错误反馈。
1.5:提升性能, 渲染层可以避免状态的反复切换,冗余调用,还可以按状态排序,还可以优化Vertex Buffer, Index Buffer, 选择合适的顶点存放方式。
2: 整体结构:
渲染层最根本的职责就是创建和操作GPU资源,并发出渲染命令。
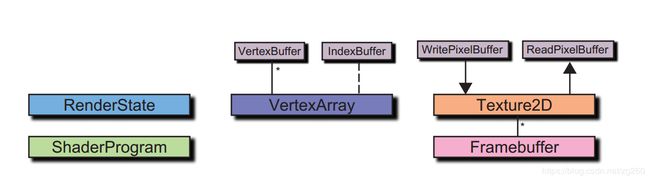
我们把渲染层划分为上述几个类,一是RenderState负责渲染状态的管理,二是ShaderProgram负责定点着色器,片段着色器,几何着色器,和Shader的管理, 三是VertexArray负责顶点熟悉数据以及索引数据的管理,四是Texture2D负责纹理的管理,同时还有了CPU-GPU之间纹理上传下载功能,五是FrameBuffer,它是一个容器负责挂载纹理附件和渲染缓冲区附件。 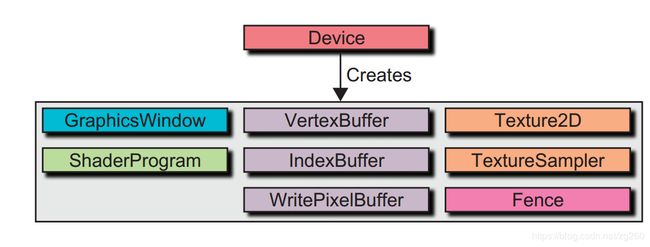
渲染层封装了Device类,并有创建上面资源的方法,首先Device可以创建多个渲染窗口GraphicsWindow,GraphicsWindow里面包含渲染上下文Context,然后上面图中的资源能够在渲染上下文之间共享。
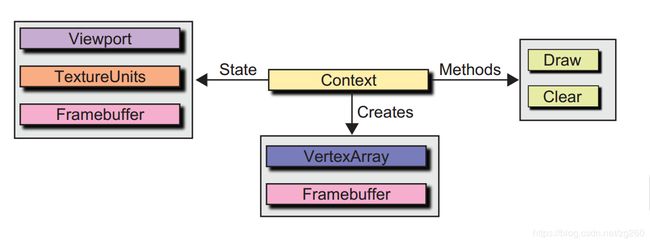
每一个Context提供了两个渲染方法Draw和Clear,这两个方法用于发出渲染命令, 一个Context里面包含一些非共享的渲染状态State,这些渲染状态是Framebuffer, 纹理单元TextureUnit,视口信息ViewPort, 顶点数组对象VertexArray, 像VertexArray, Framebuffer,这都属于轻量级的对象,是容器类的,不需要共享,OpenGL多个上下文之间只需要功能重量级的资源和状态,这个很好理解。
3: 模块划分
3.1 状态管理
状态管理核心职责是,避免状态反复切换,想想我们调用的渲染API和显卡之间隔着一个驱动层,如果频繁调用glGet, glSet, glEnable这样的API,开销比较大, 同时像Shader,Texture这样的状态切换开销就更大, 拿Shader来说,如果切换了,Shader负责存储和恢复它所拥有的Uniforms,Uniforms越多,切换的代价越大,所以要避免不必要的状态切换。
首先在绘制的最开始我们是能够获取OpenGL的初始状态的, 我们把这个状态保持下来,并在CPU端建立一个影子状态,和GPU端保持同步。 另外多个绘制命令可能共享一个状态,这样呢,我们在Context中建立一个哈希表,存储状态对象,每个绘制命令只需这个对象的一个引用就可以了。
状态从总体上分为DrawState 和 ClearState, 一个用于Draw方法, 一个用于Clear方法。
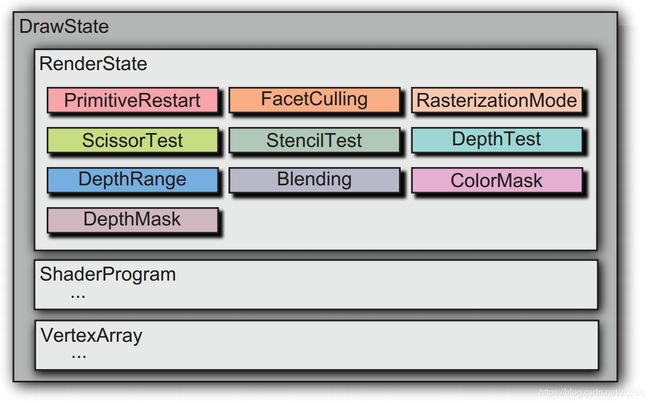
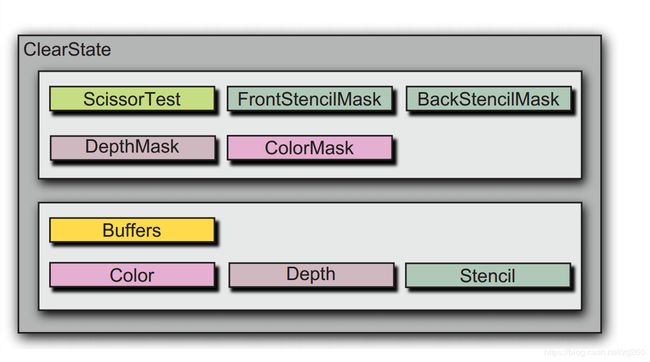
因为我们保存了一份影子状态,就是相当与对GPU当前状态做了个备份,我们在更新状态时,只需要更新差异的部分就可以了,另外状态排序是场景层做的事,可以根据Shader,Texture, Depth, Stencil等排序,那个在场景层时再说。
2.2: 着色器管理
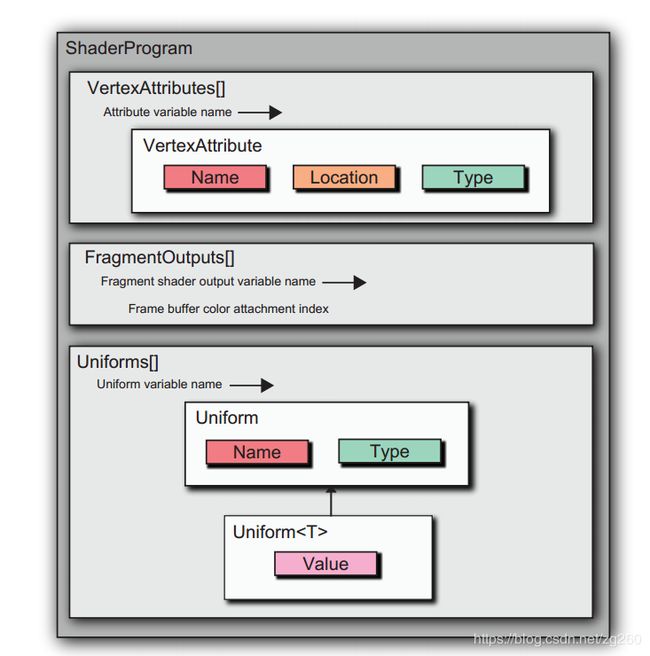
想想一个着色器都包含什么,Shader脚本, VertexAttributes, VaringVariables, Uniforms。 另外ShaderProgram对象需要被缓冲,因为一个对象可能被多个渲染命令使用, Shader的编译链接有需要时间,相同的ShaderProgram只需创建一次就可以了,所以用ShaderCache类来管理,增加引用计数功能。
另外ShaderProgram类支持自定义的GLSL常量,结构体,函数,在编译之前,我们需要把他们拼凑成一个完整的着色器脚本, 另外还要从脚本中分析出所需的Uniforms, 存到哈希表里,以便渲染之前为Uniforms赋值。

在实际使用中呢要知道顶点着色器的处理能力,一般对移动平台GPU来说40M ~ 100M/s,针对每个顶点比较独立的工作呢,还是放到顶点着色器中比较合适。 片段着色器的处理能力100M fr/s ~ 400M fr/s, 开启深度测试和模板测试有助于片段着色器提升效率。
另外GLSL推荐向量操作,一个指令周期可以处理一个向量,我可以把多个标量值打包到一个向量中,提升效率, 片段着色器包含一些计算单元,比如一个指令周期做几次乘累加操作,生成几个Varyings,做几次纹理采样,这个做为优化的参考。
2.3 顶点数据管理
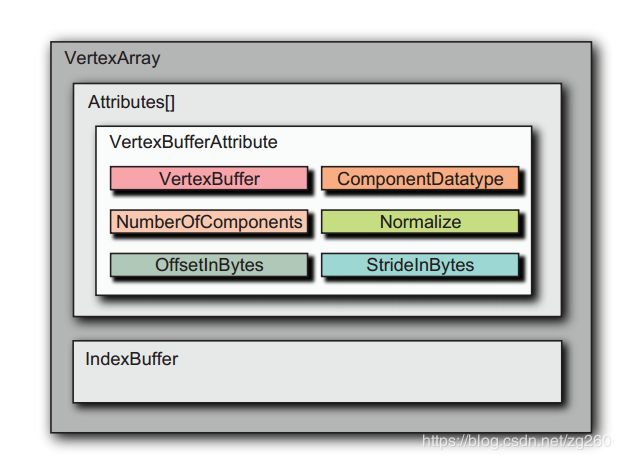
顶点数据主要描述顶点属性,比如位置,法线,纹理坐标等,它通常被送往顶点缓冲区中,顶点缓冲区一块原始的无类型的缓冲区,它可以位于GPU内存,CPU内存,或两者之家共享内存中, 主要有两种VetexBuffer和IndexBuffer。
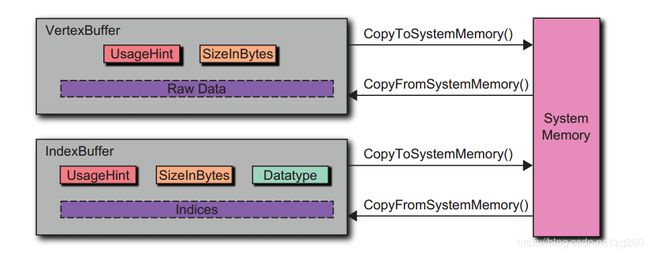 UsageHint 有三种值, 第一个是 StaticDraw 它表示顶点数据拷贝到缓冲区一次,并使用它进行多次绘制。 这适用于静止的物体绘制。 第二个是 StreamDraw 它表示顶点数据拷贝到缓冲区一次,最多只使用它进行几次绘制。 第三个是DynamicDraw,它表示顶点数据拷贝到缓冲区一次,只使用它绘制一次。 所以这个UsageHint参数值,留给场景层赋值,根据不同业务场景设定合适的值。
UsageHint 有三种值, 第一个是 StaticDraw 它表示顶点数据拷贝到缓冲区一次,并使用它进行多次绘制。 这适用于静止的物体绘制。 第二个是 StreamDraw 它表示顶点数据拷贝到缓冲区一次,最多只使用它进行几次绘制。 第三个是DynamicDraw,它表示顶点数据拷贝到缓冲区一次,只使用它绘制一次。 所以这个UsageHint参数值,留给场景层赋值,根据不同业务场景设定合适的值。
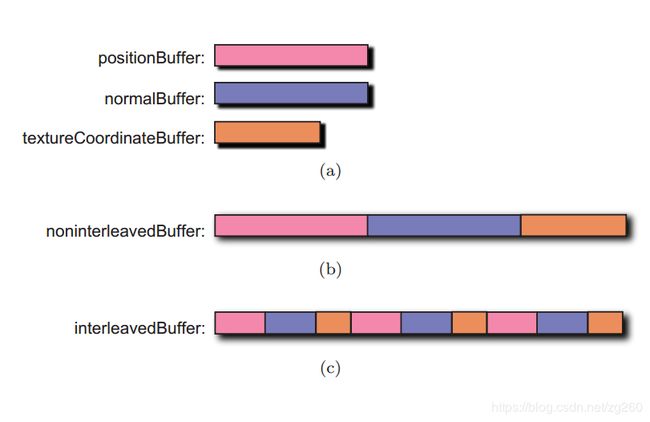
另外顶点属性数据存储分为两种形式, 第一个是交叉存储(c):就是位置,法线,纹理坐标存储在一个缓冲区中。第二个是独立存储(a):就是位置,法线,纹理坐标分别存储到单独的缓冲区中。对于静态网格物体我们推荐交叉存储,动态物体推荐独立存储方式,有时还可以同时使用两种方式 。如图
对于索引缓冲区来说,使用合适的数据类型是必要的,如果顶点个数小于64k,我们要使用usigned short16.
顶点缓冲区和索引缓冲区只是把数据存到的内存中,只是缓冲区,而VertexArray才是负责解释缓冲内容的,他可以包含多个缓冲区,相当于是个容器。
2.4: 纹理
2.4.1纹理属性表示:
纹理表示GPU内存中的数据,它有宽高,格式,和是否生成Mipmaps(自动生成一系列从小到大的图片).
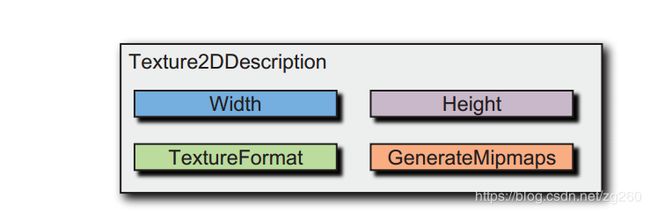
我们通常把纹理的维度是2次幂大小的纹理称为 POT纹理,比如2D纹理的宽高为2的幂次方,与之对应的就是NPOT
纹理,通常来说,POT纹理性能要比NPOT纹理好, 为了最佳的纹理上传性能,建议纹理的宽高都是32的倍数。
纹理Mipmapping有两个优点,第一个是大幅提高纹理缓冲,从而提高程序性能,第二个是在显示模型LOD时弥补欠采样从而提高图形质量。缺点就是多占用了1/3的显存,Mipmapping可以通过显卡厂商提高的工具生成,也可以通过调用glGenerateMipmap生成。
2.4.2纹理数据传输:
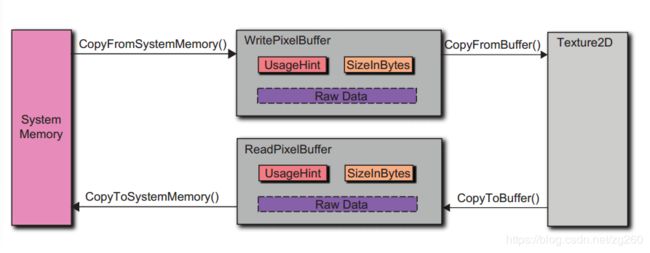
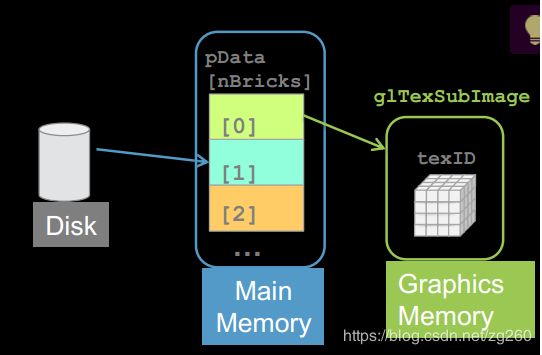
纹理传输细节, 首先看一看一张纹理从CPU内存中传输到GPU内存中,经历几个阶段, 这是个示意图:
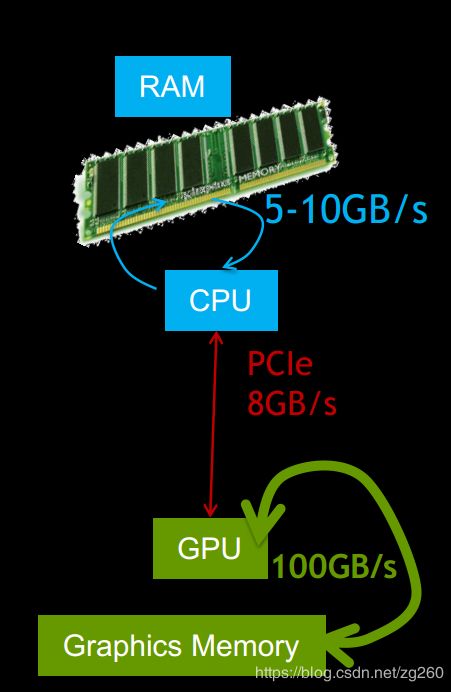
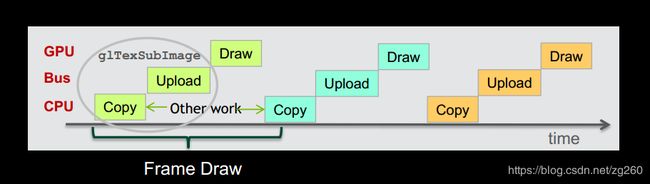
当我们用glTextureSubImage更新纹理时, 把纹理传到GPU内存中的操作个同步的操作,就是必须要等到纹理传到GPU内存后才能返回,细节看下面这幅图,在每帧绘制的时候呢,这里glTextureSubImage包含了Copy 和 Upload两部操作的时间。
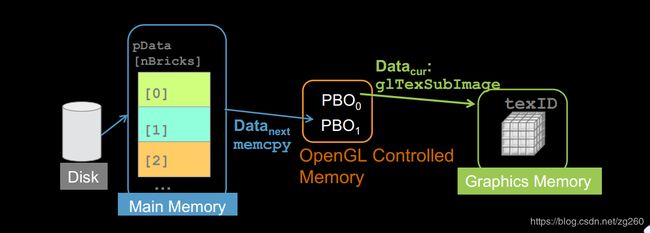
 那么有PBO(Pixel Buffer Objects)之后呢,我们可以先把数据传到PBO中,PBO可以想象成OpenGL驱动程序的一块地址空间,这块地址空间可以由应用程序写入和读取, 注意PBO是OpenGL驱动控制的内存区域,上传这部分操作就交给DMA去做了,对我们是透明的,这样拷贝操作和上传操作可以并行进行,只要我们用两块PBO乒乓模式交替上传纹理内存, 这样glTextureSubImage能很快的返回了。看图:
那么有PBO(Pixel Buffer Objects)之后呢,我们可以先把数据传到PBO中,PBO可以想象成OpenGL驱动程序的一块地址空间,这块地址空间可以由应用程序写入和读取, 注意PBO是OpenGL驱动控制的内存区域,上传这部分操作就交给DMA去做了,对我们是透明的,这样拷贝操作和上传操作可以并行进行,只要我们用两块PBO乒乓模式交替上传纹理内存, 这样glTextureSubImage能很快的返回了。看图:
另外还可以把纹理上传放到单独的线程中做,这需要共享OpenGL上下文和同步,这个在多线程渲染设计中再详细说。
2.4.3纹理采样参数:
当我们渲染的时候,需要对纹理进行采样的各种参数,比如说放大缩小如何对纹理进行采样, 纹理坐标超出范围时怎么对纹理进行采样,这些参数对渲染的图形质量非常有用。
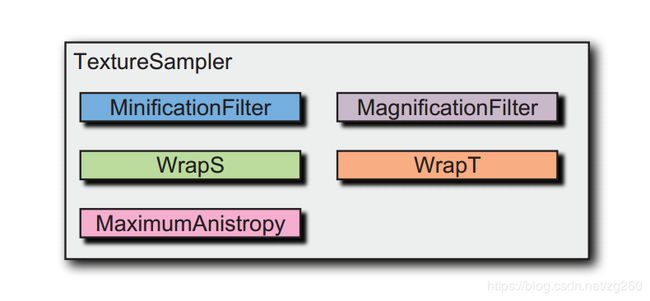
纹理滤波就是在一堆像素中逐个检索,推举出一个最好像素的给片段着色器,滤波函数不同,选举规则不同。检索时需要访问多个值,他们可能来自不同的内存区域,因此会影响缓存性能和内存带宽,负责的滤波操作会让图形处理器花费更多的时间,并访问更多内存,同时也有可能出现当前访问的纹理元素不在缓存中,重新调度。另外应用程序应该在片段着色器执行之前计算好纹理坐标,有益于纹理的缓存,提高采样效率,除非纹理坐标必须在片段着色器中计算。
纹理滤波用于提高场景中的图形质量,但是滤波函数越复杂成本越高,图像质量相对越好,比如 nearest < bilinear < cubic < tri-linear < anisortropic。 如果当前滤波生成的图像质量可以接受,那么我们就不使用更复杂的滤波函数。
注意 GL_LINEAR_MIPMAP_LINEAR能够消除mipmap级别之间裂缝,但它和GL_TEXTURE_MAX_ANISOTROPY都是比较昂贵的纹理过滤模式。
2.4.4 多重纹理
另外在渲染时,多重纹理很常见,比如在一个地形瓦片上面覆盖多层影像数据, 在着色器中使用的都是纹理单元对吧, 我们通过把纹理分别绑定到不同的纹理单元,来实现多重纹理的绘制, 这里有一个技巧:
a: 在创建纹理资源时,我们都是用GL_ TEXTURE0。
b:在渲染时,每一帧,我们遍历Uniforms, 将用到的纹理绑定到不同纹理单元 GL_ TEXTURE0 + i,完成后,返回已绑定的最大纹理单元索引值 maxTextureUintIndex。
c:这帧渲染结束时,我们对 maxTextureUintIndex 循环,对这些纹理单元解绑定。
2.4.5 纹理压缩:
首先看看没有压缩的纹理生成过程, 我们会从BMP,PNG,JPG格式中解压图片,然后拷贝上传的GPU, 这些格式在磁盘上存储的空间比较小,但解压后在内存中空间会很大,解压是昂贵的操作:
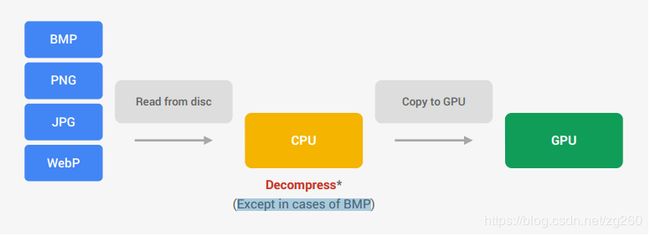
PowerVR, Adreno,Mali, Tegra 这些GPU支持一些纹理压缩格式DXT, S3TC, PVRTC,ASTC, 并提供了转换压缩纹理的工具, OpenGL,OpenGLES规范或扩展中也支持其中的一些格式,并提供了API glCompressedTexImage2D。
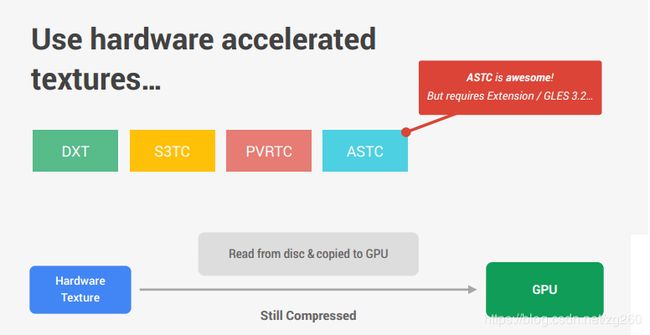
纹理压缩的优势是节省了内存开销,但也有缺点,就是同样一张图片,压缩纹理文件的尺寸要比JGP,PNG的大。
另外在着色器中推荐是用压缩纹理格式, 因为每个像素占用的比特位少啊,这就使我们降低内存带宽,提供程序性能,比如RGB的DXT1和ETC,RGBA的DXT3, DXT5, 这几种格式每个像素才占用4Bits或8Bits,而正常的RGB,RGBA每个像素占用32bits。
2.5:帧缓冲区管理
帧缓冲区可以想象成纹理的容器,主要作用是渲染到纹理,比如我们绑定帧缓冲区,用更高的分辨率来渲染场景,将结果绘制到纹理,或者把延迟着色信息写入到多个纹理,比如深度,法线,材质等,这也称作多渲染目标。
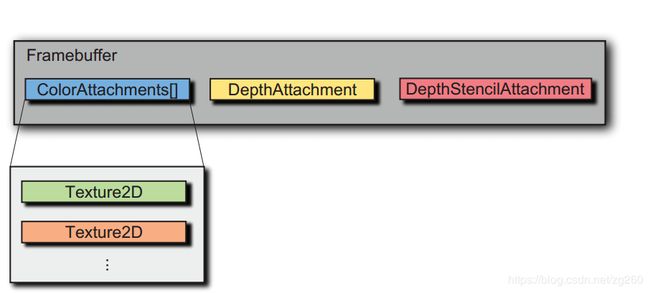
一旦创建了一个帧缓冲区,我们就可以添加多个纹理作为颜色缓冲区和另一种纹理作为深度缓冲区或模板缓冲区。重要的是纹理的格式与framebuffer附件类型兼容。
3:最后用这些模块绘制一个三角形吧:

参考资料:https://www.nvidia.com/en-us/nvdocs/drive/5_1/linux/DRIVE_Linux_AGX_PDK_Development_Guide/Graphics/graphics_OGLES2/