redis学习笔记2-数据结构
1. 几个全局命令
查看所有键:keys * //需要遍历所有键,性能差
键总数:dbsize //直接返回redis键总数变量,不会遍历所有键
键是否存在:exists key //存在返回1
删除键:del key [key...] //无论值是什么类型都能删除 返回删除键的个数
键过期:expire key seconds //设置键过期时间,过期后自动删除,如果某个键设置了过期时间后又更新了值,那么会自动取消过期时间
键对应的值的类型:type key //返回值类型如字符串、hash、集合、列表等,如果键不存在,返回none
键重命名:rename key newkey
随机返回一个键:randomkey
设置键且键在N秒后过期:setex key n
2. 数据结构的内部编码
指令:object encoding key
3. 单线程架构
客户端提交指令给redis的任务队列,redis从任务队列中取出指令进行执行,执行完成后放到返回队列。
优点:
纯内存访问
非阻塞I/O,redis利用I/O多路复用技术实现
单线程避免线程切换以及竞态消耗
缺点:如果有命令执行时间过长,则会造成其他命令阻塞
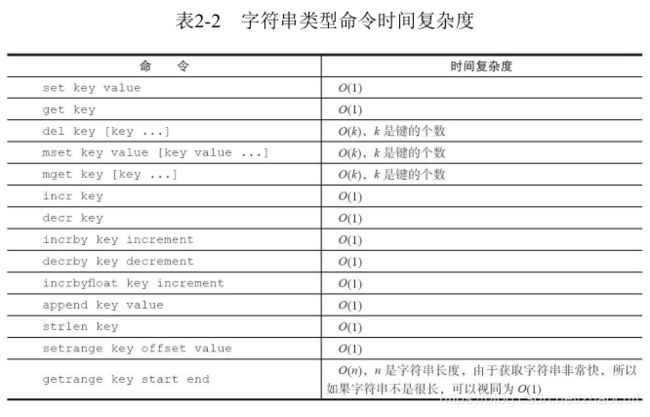
4. 字符串 string
字符串可以是简单字符串、复杂字符串(json、xml)、数字(整数、浮点数)、二进制数据,最多不能超过512M
常用命令:
set key value [ex seconds][px milliseconds][nx|xx]
ex seconds:秒级过期时间
px milliseconds:毫秒级过期时间
nx:key不存在时设置,类似增加,和setnx 指令效果一样,可用于分布式锁的实现方案(redis单线程)
xx:key存在时设置,类似更新,和setxx指令效果一样
get key :获取key对应的值,如果值不存在返回nil
mset key value [key value]:批量设置键值对
mget key [key]:批量获取值,如果某个值不存在,则该值对应的返回为nil,原子操作
注意:
mset和mget如果数量过多,可能引起网络阻塞或redis阻塞
和pipeline不同,这个是原子操作
计数:
incr key //如果值不是整数则报错,值不存在则按值为0自增
decr key //自减
incrby ke //自增指定数字
decrby key //自减指定数字
incrbyfloat key //自增浮点数
总结:
谨慎使用复杂度高的批量操作指令,即批量时个数需要限制
内部编码:
·int:8个字节的长整型。
·embstr:小于等于39个字节的字符串。
·raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
使用场景:
缓存功能、计数、共享session、限速(比如同个用户在1秒内不能请求多次同一个URL)
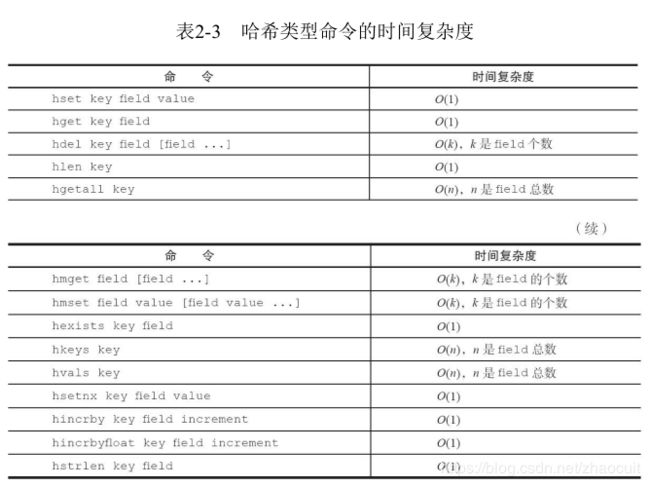
5. 哈希 hash
redis的hash类似于Java中的Map
常用命令:
hset key field value:成功返回1,失败返回0
hget key field:获取值,如果key或field不存在,返回nil
hdel key field [field..]:删除key对应的一个或多个field,返回成功删除的个数
hlen key:返回key对应的field字段数
hmget key field[field..]:批量获取key的字段对应的值
hmset key field value[field value]:批量设置key的字段和值
hexists key field:判断某个key对应的field是否存在,返回1表示存在
hkeys key:获取key对应的所有field
hvals key:获取key对应的所有value
hgetall key:获取key对应的所有的字段及其值
总结:
注意批量操作的几个指令的复杂度
内部编码:
·ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
·hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
例子:
当field个数比较少且没有大的value时,内部编码为ziplist
当有value大于64字节,内部编码会由ziplist变为hashtable
当field个数超过512,内部编码也会由ziplist变为hashtable
使用场景:
缓存某个对象实例
使用原生字符串类型:
如:set user:1:name "zhangsan" set user:1:age 23
优点:简单直观,每个属性都支持更新操作
缺点:占用过多的键,内存占用量大,对象内聚性差
总结:生产环境一般不用
序列化字符串类型:
如将value值序列化成json对象
优点:简化编程,可以提高内存使用率
缺点:序列化、反序列化有一定的开销,每次更新属性都需要经历反序列化、更新、序列化、提交给redis
总结:如果数据为只读或不常更新,可以使用
哈希类型:
优点:简单直观,合理使用可以提高内存使用率
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存
总结:使用,但需要注意字段个数和字段值大小(即汉字不要超过64/3)
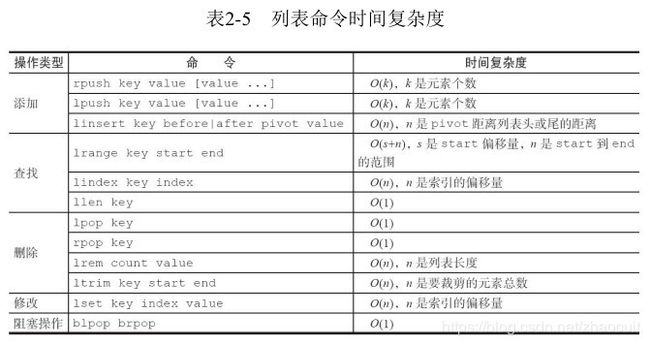
6. 列表 list
一个列表最多可以存储2的32次方-1个元素,在redis中可以对列表进行2端插入和2端弹出,可以用来当栈和队列使用。列表中的元素是有序的,可以通过下标获取,元素可以重复,类似Java中的List,但其底层实现为双向链表。
内部编码:
·ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
·linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
例子:
当元素个数较少且没有大元素时,内部编码为ziplist
当元素个数超过512个,内部编码变为linkedlist
当某个元素超过64字节,内部编码会变为linkedlist
使用场景:
·lpush+lpop=Stack(栈)
·lpush+rpop=Queue(队列)
·lpsh+ltrim=Capped Collection(有限集合)
·lpush+brpop=Message Queue(消息队列)
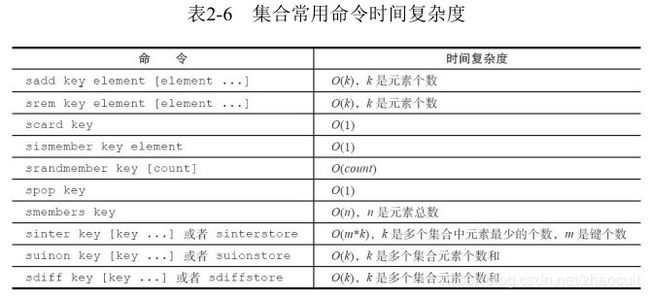
7. 集合 set
和Java中的set类似,不允许重复、无序,和列表一样,最多可以存储2的31次方减1个元素
常用指令:
sadd key element[element..]
srem key element [element...]
scard key :获取元素个数,返回内部计数变量
sismember key element:元素是否在集合中,1为是
srandmember key [count]:随机从集合中返回count个元素
spop key [count]:随机从集合中弹出count个元素
smembers key:获取所有元素
sinter key [key...]:求多个集合的交集
suinon key [key... ]:求多个集合的并集
sdiff key [key...]:求多个集合的差集
sinterstore newkey key[key...]:求多个集合的交集并保存到newkey集合中
suinonstore newkey key[key...]: 求多个集合的并集并保存到newkey集合中
sdiffstore newkey key[key...]: 求多个集合的差集并保存到newkey集合中
内部编码:
·intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
·hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
当元素个数较少且都为整数时,内部编码为intset
当元素个数超过512个,内部编码变为hashtable
当某个元素不为整数时,内部编码也会变为hashtable
使用场景:
·sadd=Tagging(添加标签)
·spop/srandmember=Random item(生成随机数,比如抽奖)
8. 有序集合
和set一样元素不能重复,每个元素都有一个分数属性,根据分数进行排序,分数可以重复。
常用指令:
zadd key score member [nx|xx|ch|incr] [score member...]:向key集合添加元素
·nx:member必须不存在,才可以设置成功,用于添加。
·xx:member必须存在,才可以设置成功,用于更新。
·ch:返回此次操作后,有序集合元素和分数发生变化的个数
·incr:对score做增加,相当于后面介绍的zincrby。
zcard key:返回成员个数
zscore key member:返回某个成员的分数
zrank/zrevrank key member:计算某个成员的排名,升序/降序
zrem key member [member...]:删除成员
zincrby key scores member:为成员增加scores分数
zrang/zrevrange key startindex endindex [withscores]:返回升序/降序排列从start开始到end结束
zrangebyscore key min max [withscores] [limit offset count]:按照分数从低到高返回,[limit offset count]选项可以限制输出的起始位置和个数
zcount key min max:返回指定分数范围的成员个数
zremrangebyrank key start end:删除指定排名内的升序元素
zremrangebyscore key min max:删除指定分数范围的成员
总结:
有序集合和集合相比,很多功能都要耗时些。
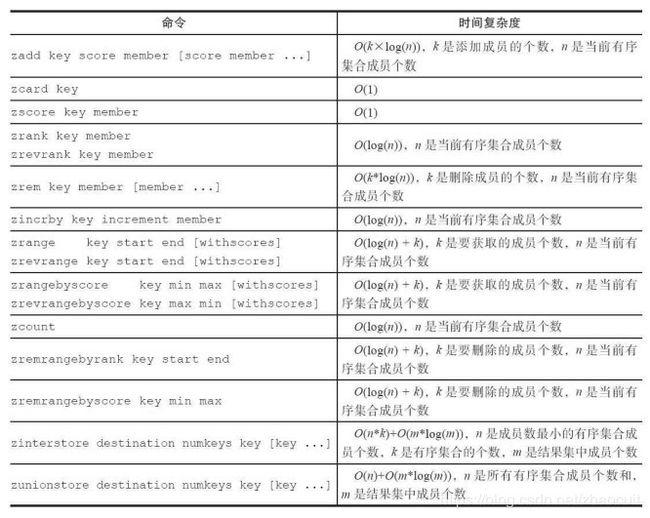
内部编码:
·ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时
·skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现
当元素个数较少且每个元素较小时,内部编码为skiplist
当元素个数超过128个,内部编码变为ziplist
当某个元素大于64字节时,内部编码也会变为hashtable
使用场景:
添加或减少分数
分数排行榜