mysql学习7:MySQL数据库事物与存储过程
一、 事务存储
1. 事务的概念
事务就是针对数据库的一组操作它可以由一条或者多条SQL语句组成,同一个事务的操作具备同步的特点,如果其中有一条语句无法执行,那么所有的语句都不会执行,也就是说,事务中的语句要么都执行,要么都不执行。
(1) 在数据库中使用事务时,必须先开启事务,开启事务的语句具体如下:
Start transaction;
(2) 事务开启之后就可以执行SQL语句,SQL语句执行成功后,需要使用相应语句提交事务,提交事务的具体语句如下:
Commit;
需注意的是,mysql中直接书写的sql语句都是自动提交的,而事物操作语句都需要使用commit语句手动提交,只有事务提交后其中的操作才会生效。
(3) 如果不想提交当前事务还可以使用相关语句取消事务(也称回滚),具体语句如下:
rollback;
需注意的是,rollback语句只能针对未提交的事务执行回滚操作,已提交的事务不能回滚。
(4) 示例:下面两条update语句如果任意一条语句出现错误就会导致事务不会提交。
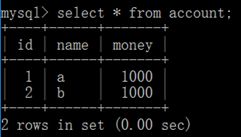


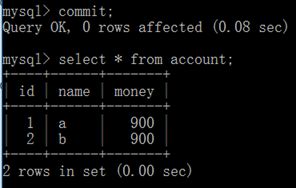
(5) 事务有很严格的定义,它必须满足4个特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),也就是人民俗称的ACID标准,接下来就是针对这四个特性进行讲解。
Ø 原子性:指一个事务必须被视为一个不可分割的最小工作单元,只有食物中所有的数据库操作都执行成功,才算整个事务执行成功,事务中如果有任何一个SQL语句执行失败,已经执行成功的SQL语句也必须撤销,数据库的状态退回到执行事务前的状态。
Ø 一致性:指事务将数据库从一种状态转变为下一种一致性的状态。
Ø 隔离性:还可以称为并发控制、可串行化、锁等,当多个用户并发访问数据库时,数据库为每一个用户开启的事务不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
Ø 持久性:事务一旦提交,其所做的修改就会永久保存到数据库中,即使数据库发生故障也不应该对其有任何影响。
2. 事务的提交
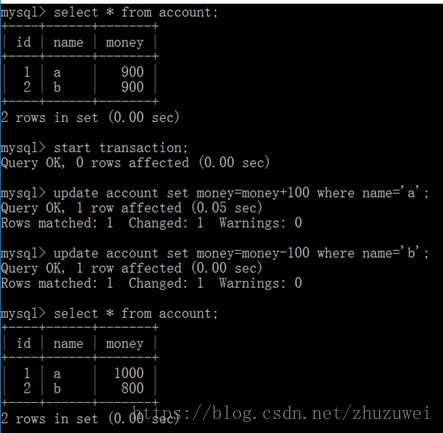
从上述结果可以看出,在事务中实现了转账功能。此时退出数据库然后重新登陆,并查询数据库中各账户的余额信息,查询结果如下:
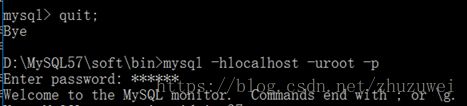
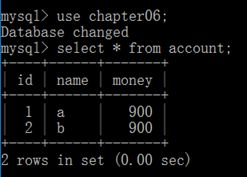
从上述结果看出,实物中的转账操作没有成功,这是因为在实物中转账成功后还没有提交事务就退出数据库了。
再次执行上述语句,然后使用commit语句来提交事务,操作成功提交。

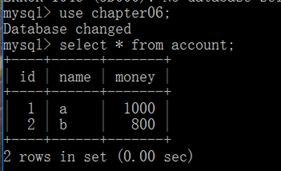
3. 操作的回滚


4. 事务的隔离级别:mysql中有4中隔离级别
(1) read uncommitted (读未提交): 是事务中最低的级别,该级别下事务可以读取到另一个事务中未提交的数据,也被成为脏读取(Dirty Read),这是相当危险的,一般很少使用。
(2) read committed(读提交):大多数数据库管理系统的默认隔离级别都是read committed,该级别下的事务只能读取其他事务已经提交的内容,可以避免脏读,但不能避免重读和幻读。
重复读就是在事务内重复读取了别的线程已经提交的数据,但两次读取的结果不一致,原因是查询的过程中其他事务做了更新的操作。
幻读是指在一个事务内两次查询中数据条数不一致,原因是查询过程中其他事务做了添加操作。
(3) Repeatable read(可重复读)是mysql默认的事务隔离级别,它可以避免脏读、不可重复读的问题,确保同一事务的多个实例在并发读取事务时,会看到同样的数据行。但理论上,该级别会出现幻读的情况,不过mysql的存储引擎通过多个版本并发控制机制解决了该问题,因此该级别是可以避免幻读的。
(4) Serializable(可串行化)是事务的最高隔离级别,它会强制对事务进行排序,使之不会发生冲突,从而解决脏读、幻读、重复读的问题。实际上,就是在每个读的数据行上加锁。这个级别,可能导致大量的超时现象和锁竞争,实际应用中很少使用。
(5) 示例
脏读:
打开两个命令行窗口,设置b账户中事务的隔离级别。Session表示当前会话。
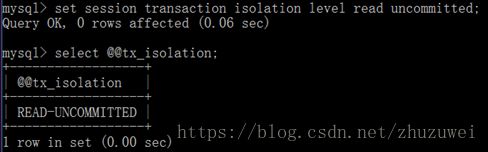
演示脏读:
在b账户中开启一个事务,并在该事务中查询当前账户的余额信息
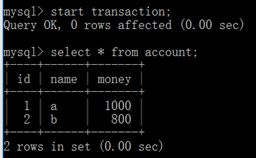
在a账户开启一个事务,并在当前窗口中执行转账功能,但是不提交事务。
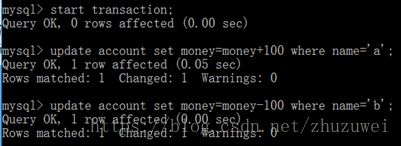
A账户完成转账语句后,b账户查询当前账户。可以看出,b账户误以为a账户已经转账成功了,出现了脏读。
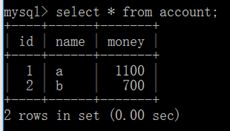
不可重复读:和脏读有些类似,但是脏读是读取前一个事务未提交的脏数据,而不可重复读是在事务内重复读取了别的线程已提交的数据。
演示不可重复读
要先设置隔离级别

先在b账户开启一个事务,在当前事务中查询余额
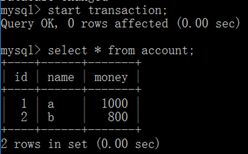
在a账户中不用开启事务,直接update

在b中的再次查询结果改变
幻读(phantomread)由被称为虚读。
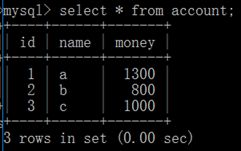
设置b账户的隔离级别,查询余额信息

在a账户中进行添加信息

当a账户添加记录成功后,查询b中的account
可串行化:是事务的最高隔离级别。
先设置b账户中事务的隔离级别
![]()
演示可串行化
B账户开启事务并查询
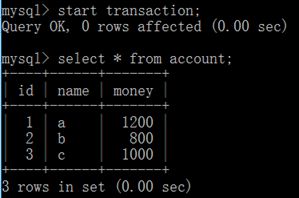
A账户开启一个事务,并执行插入操作

可以看出,当b账户正在事务中查询余额信息时,a账户中的操作是不能立即执行的。
B账户查询完之后,提交当前事务
![]()
二、 存储过程的创建
存储过程就是一条或多条SQL语句的集合,当对数据库进行一系列复杂操作时,存储过程可以将这些复杂操作封装成一个代码块,以便重复使用,大大减少数据库开发人员的工作量。
1. 创建存储过程
Create procedure sp_name([proc_parameter])[characteristics…] routine_body
上述语法格式中,create procedure为用来创建存储过程的关键字;sp_name为存储过程的名称;proc_parameter为指定存储过程的参数列表,该参数列表的形式如下:
[in|out|inout] param_name type
其中in表示输入参数,out表示输出参数,inout表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型,它可以是mysql数据库中的任意类型。
Characteristics用于指定存储过程的特性,它的取值说明具体如下:
(1) language sql: 说明routinue_body部分是由sql语句组成的,当前系统支持的语言为sql,sql搜索language的唯一值;
(2) [not] deterministic:指明存储过程的结果是否确定。Deterministic表示结果是确定的。每次执行存储过程时,相同的输入会得到相同的输出;not deterministic表示结果是不确定的,相同的输入可能得到不同的输出。如果没有指定任意一个值,默认为not deterministic.
(3) {contains sql | no sql | reads sql data | modifies sql data}:指明子程序使用sql语句的限制。Contains sql表明子程序包含sql语句,但是不包含读写数据的语句;no sql表名子程序不包含sql语句;reads sql data说明子程序包含读写数据的语句;modifies sql data表明子程序包含写数据的语句。默认情况为contains sql.
(4) Sql security {definer |invoker}:指明谁有权限来执行。Definer表明只有定义者才能执行。Invoker表示拥有权限的调用者可以执行。默认为definer.
(5) Comment'string’:注释信息,可以用来描述存储过程。
Routine_body是sql代码的内容,可以用begin…end来表示sql代码块的开始和结束。
案例演示:


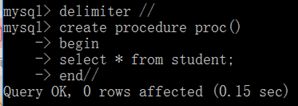
![]()
Delimiter //语句将mysql的结束符设置为//。可以避免存储过程中与sql语句默认结束符相冲突。注意delimiter与要设定的结束符之间一定要有一个空格,否则设定无效。
2. 变量的使用:在编写存储过程时,有时会需要使用变量保存数据处理过程中的值。在mysql中,变量可以在子程序中声明并使用,这些变量的作用范围是在begin…end程序中。要在begin。。。end内定义。
(1) 定义变量:declare var_name[,varname]…data_type[default value];
Default value子句给变量提供一个默认值。该值除了可以被声明为一个常数之外,还可以被指定为一个表达式。如果没有default子句,变量的初始值为null.
如:declare myvariable int default 100; 定义变量
Set var_name=expr[,var_name=expr]…; 为变量赋值
还可以使用select…into为一个或多个变量赋值,该语句可以把选定的列直接存储到对应位置的变量。
Select col_name[…] into var_name[…] table_expr;
其中,col_name表示字段名称;var_name表示定义的变量名称;table_exxpr表示查询条件表达式,包括表名称和where子句。
如:将student表中name为rose的同学的成绩和性别分别存入到了变量s_grade和s_gender中。
Declare s_gradefloat;
Declare s_gender char(2);
select grade, genderinto s_grade, s_gender from student where name=’rose’;
3. 定义条件和处理程序
(1) 定义条件
Declare condition_name condition for [condition_type];
// condition_type 的两种形式:
[condition_type]:
Sqlstate[value] sqlstate_value | mysql_error_code
其中,condition_name表示所定义的条件的名称;
Condition_type表示条件的类型;
Sqlstate_value和mysql_error_code都可以表示mysql的错误,sqlstate_value是长度为5的字符串类型错误代码,mysql_error_code为数值型的错误代码。例如:ERROR1142(42000)中,sqlstate_value的值是42000,mysql_error_code的值是1142.
上述语法格式指定了需要特殊处理的条件。它将一个名字和指定的错误条件关联起来。这个名字可以随后被用在定义处理程序的declare handler语句中。
例:定义‘error1148(42000)’错误,名称为command_not_allowed。可以有两种不同的方法来定义:
//方法一:使用sqlstate_value
Declare command_not_allowed condition for sqlstate ‘42000’;
//方法二:使用mysql_error_code
Declare command_not_allowed condition for 1148;
(2) 定义处理程序
Declare handler_type handler for condition_value[,…]sp_statement
Handler_type:
Continue | exit |undo
Condition_value:
|condition_name
|sqlwarning
|not found
|sqlexeption
|mysql_error_code
其中,handler_type为错误处理方式,参数取三个值。Continue表示遇到错误不处理,继续执行;exit表示遇到错误马上退出;undo表示遇到错误之后撤回之前的操作,mysql中暂时不支持这样的操作。Sp_statement参数为程序语句段,表示在遇到定义的错误时,需要执行的存储过程;condition_value表示错误类型,可以有以下取值:
(1) sqlstate[value] sqlstate_value包含5各字符的字符串错误值。
(2) condition_name表示declarecondition定义的错误条件名称;
(3) sqlwarning匹配所有以01开头的sqlstate错误代码
(4) not found匹配所有以02开头的sqlstate错误代码;
(5) sqlexception匹配所有没有被sqlwarning或not found捕获的sqlstate错误代码。
(6) mysql_error_code匹配数值类型错误代码。
例1:定义处理程序的几种方式:
//方法一:捕获sqlstate_value
Declare continuehandler for sqlstate ‘42s02’ set @info=’NO_SUCH_TABLE’;
如果遇到sqlstate_value值为’42s02’,则执行continue操作并且输出’NO_SUCH_TABLE’信息。
//方法二:捕获mysql_error_code
Declare continuehandler for 1146 set @info=’NO_SUCH_TABLE’;
如果遇到mysql_error_code值为1146,则执行continue操作,并且输出’NO_SUCH_TABLE’信息。
//方法三:先定义条件,然后使用
Declareno_such_table condition for 1146;
Declare continuehandler for NO_SUCH_TABLE SET @info=’ERROR’;
先定义no_such_table条件,遇到1146错误就执行continue操作。
//方法四:使用sqlwarning
Declare exithandler for sqlwarning set @info=’error’;
Sqlwarning捕获所有以01开头的sqlstate_value值,然后执行exit操作,并且输出‘error’信息。
//方法五:使用NOTFOUND
Declare exithandler for not found set @info=’NO_SUCH_TABLE’;
Not found捕获所有以02开头的sqlstate_value值,然后执行exit操作,并且输出’NO_SUCH_TABLE’信息。
//方法六:使用sqlexception
Declare exithandler for sqlexception set @info=’error’;
Sqlexception捕获所有没有被sqlwarning或not found捕获的sqlstate_value值,然后执行exit操作,并且输出’ERROR’信息。
例1:
@x是一个用户变量,执行@x等于3,表明mysql被执行到程序的末尾。如果没有declare ……语句,第二个insert会因primary key强制而失败,mysql可能已经采取默认(exit)路径,并且select @x会返回2.

4. 光标的使用
如果查询数据返回的记录非常多,则需要使用光标逐条读取查询结果集中的记录。光标是一种用于轻松处理多行数据的机制。
(1) 光标的声明:光标必须声明在声明变量、条件之后,声明处理程序之前。
Declare cursor_name cursor for select_statement
其中,cursor_name表示光标的名称;select_statement表示select语句的内容,返回一个用于创建光标的结果集。
如:declare cursor_student cursor for select s_name, s_gender fromstudent;
(2) 光标的使用:使用光标之前首先要打开光标。
Open cursor_name
Fetch cursor_name into var_name[,var_name]…
Cursor_name表示参数的名称;var_name表示将光标中的select语句查询出来的信息存入该参数中,需注意的是,var_name必须在光标声明之前就定义好。
如:fetchcursor_student into s_name, s_gender;
(3) 光标的关闭:
Close cursor_name
5. 流程控制的使用
流程控制语句用于将多个SQL语句划分成组合成符合业务逻辑的代码块。Mysql中的流程控制语句包括:if语句、case语句、loop语句、while语句、leave语句、iterate、repeat语句和while语句。
每个流程中可能包含一个单独语句,也可能是使用begin…end构造的复合语句,可以嵌套。
(1) if语句
if expr_condition then statement_list
[elseifexpr_condition then statement_list]
[elsestatement_list]
End if.
其中,expr_condition表示判断条件,statement_list表示SQL语句列表,它可以包括一个或多个语句。如果expr_condition求值为True,相应的sql语句列表就会被执行;如果没有expr_ondition匹配,则else子句里的语句列表被执行。
需要注意的是,mysql中还有一个if()函数,它不同于这里描述的if语句。
If val is null
Then select ‘val isnull’
Else select ‘val isnot null’
End if;
(2) case 语句
第一种格式:
Case case_expr
When when_value then statement_list
[when when_value then statement_list]…
[elsestatement_list]
End case
例1:
Case val
When 1then select ‘val is 1’;
When 2then select ‘val is 2’;
Elseselect ‘val is not 1 or 2’;
End case;
第二种格式:
Case
Whenexpr_condition then statement_list
[whenexpr_condition then statement_list]
[elsestatement_list]
End case;
存储过程里的case语句不能有else null子句,并且用end case替代end来终止。
(3) loop语句:只是创造一个循环操作的过程,并不进行条件判断。
[loop_label:]loop
Statement_list
End loop[loop_label]
其中,loop_label表示loop语句的标注名称,该参数可以省略;statement_list表示需要循环执行的语句。
例子:
Declare id int default 0;
Add_loop:loop
Set id=id+1;
Ifid>=10 then leave add_loop;
End if;
End loop add_loop;
(4) leave语句:用于退出任何被标注的流程控制构造:leave label
label表示循环的标志,通常情况下,leave语句与begin…end、循环语句一起使用。
(5) iterate语句:用于将执行顺序转到语句段的开头处。Iterate label
iterate语句只可以出现在loop、repeat和while语句内。
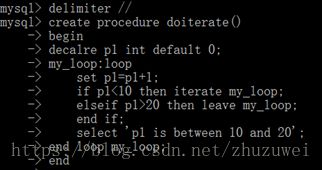
(6) repeat语句:语句创建一个带有条件判断的循环过程,每次语句执行完毕后,会对条件表达式进行判断,如果表达式为真,则循环结束;否则重复执行循环中的语句。
[repeat_label:] repeat
Statement_list
Until expr_condition
End repeat[repeat_label]
Repeat_label为repeat语句的标注名称,该参数是可选的;repeat语句内的语句或语句群被重复,直至expr_condition为真。
(7) while语句:创建一个带条件判断的循环过程,与repeat不同的是,while在语句执行时,先对指定的表达式进行判断,如果为真,则执行循环内的语句,否则退出循环。
[while_label] while expr_condition do
Statement_list
End while [while_label]
三、 存储过程的使用
1. 调用存储过程
Call sp_name([parameter[,…]])
其中,sp_name为存储过程的名称,parameter为存储过程的参数。
2. 查看存储过程:可以使用show status语句或show create语句来看,也可以直接从系统的information_schema数据库中查询。
(1) show status语句查看存储过程的状态
show {procedure | function} status [like ‘pattern’]
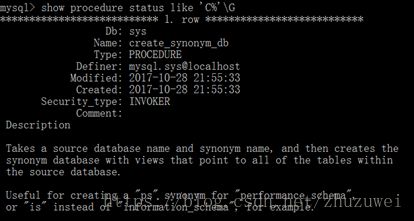
(2) show create 语句查看存储过程的状态
show create {procedure | function} sp_name
(3) 从information_schema, Routines表中查看存储过程的信息
在mysql中存储过程和函数的信息存储在information_schema数据库下的routinues表中。可以通过查询该表的记录来查询存储过程的信息。
![]()
3. 修改存储过程
Alter {procedure | function} sp_name [characteristic…..]
其中,sp_name表示存储过程或函数的名称;characteristic表示要修改存储过程的哪个部分,characteristic的取值具体如下:
(1) contains sql表示子程序包含sql语句,但不包含读或写数据的语句;
(2) no sql表示子程序中不包含sql语句
(3) reads sql data表示子程序中包含读数据的语句;
(4) modeifies sql data表示子程序中包含写数据的语句;
(5) sql security {definer |invoker}指明谁有权限来执行;
(6) definer表示只有定义者自己才可以执行;
(7) invoker表示调用者可以执行;
(8) comment ‘string’表示注释信息。
如:Alter procedurecountprocl
Modifies sql data
Sql security invoker
4. 删除存储过程
Drop {procedure | function} [if exists] sp_name
四、 综合案例----存储过程应用
1. 创建一个stu表

2. 创建一个存储过程
