Top命令基础
top命令显示多个PID的详细信息,同时可以通过uptime来获得同样的第一行数据
top返回:
top - 19:58:17 up 63 days, 9:46, 1 user, load average: 0.00, 0.02, 0.05
Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.8%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 4106756k total, 4081900k used, 24856k free, 284192k buffers
Swap: 1048568k total, 9252k used, 1039316k free, 1664760k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13689 admin 20 0 4642m 1.6g 10m S 1.3 41.7 228:40.61 java
2714 admin 20 0 15088 1276 964 R 0.3 0.0 0:00.03 top
9003 root 20 0 224m 13m 3520 S 0.3 0.3 27:58.79 ilogtail
24285 root 20 0 784m 8928 2848 S 0.3 0.2 211:30.07 logagent
1 root 20 0 19396 1064 880 S 0.0 0.0 0:09.04 inituptime返回:
$ uptime
19:58:52 up 63 days, 9:47, 1 user, load average: 0.00, 0.01, 0.05上面的结果分成几列:
| 系统时间 | 极其运行时间 | 系统登录用户数 | 平均Load值,从左到右分别为Load1 Load5 Load15 |
|---|---|---|---|
| 19:58:52 | up 63 days, 9:47(已经启动了63天多了) | 1 user | load average: 0.00, 0.01, 0.05 |
Load1 Load5 Load15 ,解释为 一分钟,五分钟,十五分钟 Load 的平均值
可以通过who命令查看登录的用户
$ who
admin pts/0 2017-06-15 18:01 (xx.xx.xx.xx)
#(xx.xx.xx.xx)为ip地址其中,pts表示通过ssh远程登录的,后面一列表示登录时间
类似的还有w命令,可以看到更多的信息
$ w
20:07 up 3 days, 10:59, 3 users, load averages: 2.05 2.17 2.14
USER TTY FROM LOGIN@ IDLE WHAT
yunpeng.byp console - 一09 3days -
yunpeng.byp s001 - 15:44 1 ssh xxx@xxx.xxx
yunpeng.byp s002 - 20:00 - w名字后面的WHAT对应的w表示是该用户在执行命令.
如果需要查看用户的命令执行历史,除了使用
history还可以直接观察.bash_history来获取每个用户的操作记录
Load
Load表示CPU处理队列的长度
以单核CPU举例,单核CPU的Load满载为1,表示一个处理时刻cpu处理一个任务
Load是可以大于1的,说明一个处理时刻,cpu需要处理的任务数大于1个,这个时候极其已经在超负荷运行了
这些场景类似于同步,只有一个线程可以访问,如果后面还有线程需要继续调度,只能排队.
4核cpu则Load满载为4,Load为8则表示同一时刻,有4个任务在处理,有4个任务在等待.
Load参数表明了目前系统的运行情况,通常情况下,几核的cpu的Load最大负载就是几,8核cpu最大Load负载就是8,超过8说明此时极其已经在超负荷运行.
下面可以看top的第二行
Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombieTasks
第二行是系统此时的进程情况
| 目前系统所有进程数 | 运行进程数 | sleep进程数 | 中断进程数 | 僵尸进程数 |
|---|---|---|---|---|
| 148 total | 1 running | 147 sleeping | 0 stopped | 0 zombie |
在观察cpu情况时,如果出现过多的僵尸进程或者中断进程,需要考虑系统是否存在调整过优先级的进程或进程设计是否存在问题.可以考虑重启机器
任务的状态分成如下一些状态:
- TASK_RUNNING: 进程当前正在运行,或者正在运行队列中等待调度
- TASK_INTERRUPTIBLE: 进程处于睡眠状态,正在等待某些事件的发生.进程可以被信号中断.接收到信号或被显式的唤醒呼叫唤醒之后,进程转变成为TASK_RUNNING状态.
- TASK_UNINTERRUPTIBLE: 此进程状态类似于TASK_INTERRUPTIBLE,只是它不会处理信号,中断处于这种状态的进程是不合适的,因为它可能正在完成一些重要的任务.当它所等待的时间发生时,进程江北显式的唤醒所唤醒
- TASK_STOPPED: 进程已经终止执行,它没有运行,并且不能运行,接收到SIGSTOP和SIGTSTP等信号时,进程将进入这种状态.接收到SIGCONT信号之后,进程将再次变得可运行.
- TASK_TRACED: 正被调试程序等待其他进程监控时,进程将进入这种状态.
- EXIT_ZOMBIE: 进程已终止,它正等待其父进程收集关于他们的一些统计信息.
- EXIT_DEAD: 最终状态.将进程从系统中删除时,它将进入此状态,因为其父进程已经通过
wait4()或者waitpid()调用收集了所有的统计信息.
CPU
第三行
Cpu(s): 0.0%us, 0.1%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st用man可以看到其中的具体含义:
- us: user mode
- sy: system mode
- ni: low priority user mode (nice)
- id: idle task
- wa: I/O waiting
- hi: servicing IRQs
- si: servicing soft IRQs
- st: steal (time give to other DomU instances)
top展示下,按数字键1可以看到cpu的核数核每个cpu的具体情况
Cpu0 : 0.0%us, 0.0%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
Cpu1 : 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 0.0%us, 0.0%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%stus和sy
us指的是用户控件占cpu的时间百分比,sy指的是系统空间占用cpu的百分比
将linux系统分为三部分,最底下是硬件配置,中间是系统空间,最上面是用户空间
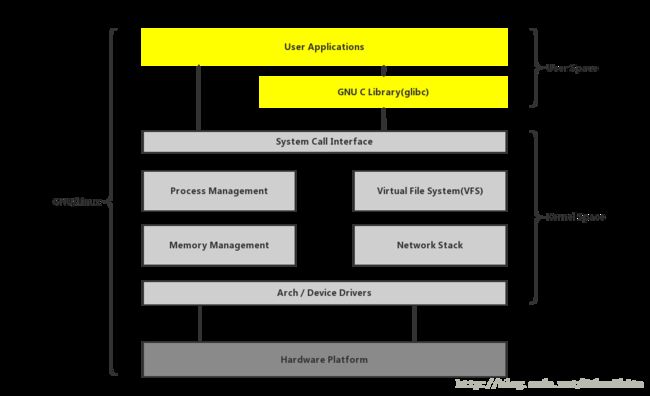
进程在执行用户自己的代码时,则称其处于用户状态,此时耗时的cpu的百分比为us,而一个任务(进程)执行系统调用而陷入内核代码中执行时,称进程处于内核运行态,此时耗费cpu的百分比为sy
用户代码与系统代码在内存中是分开存储的,一般而言,系统代码存放在内存的高位中.
举个具体的事例而言,例如我们要调用java的httpclient发送http请求,那么对httpclient代码的处理,参数的填写,这些动作的执行,都算是用户控件的cpu耗费,而最后需要调用网卡驱动去发送网络信号,这些,则算是系统控件的cpu耗费.
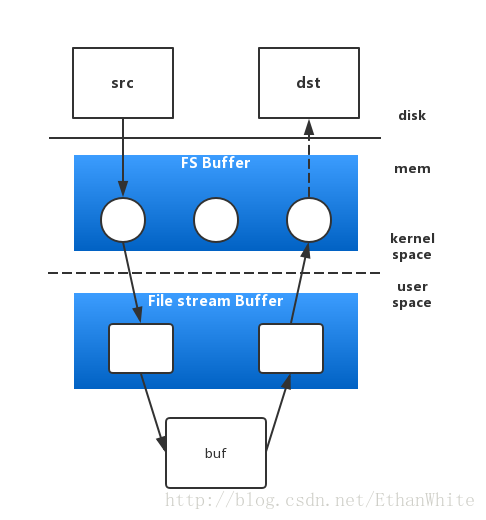
我们在cp文件时,需要先将文件拷贝到内核空间的Buffer上,在拷贝到用户空间的buffer上,再反过来,从用户空间的buffer上,到系统空间的buffer上,再到磁盘上.
而在这个过程中,在系统空间耗费的cpu时间片就是sy,而在用户空间的耗费就是us
ni
ni全称是nice,用户进程空间内改变过优先级的进程占用CPU百分比.
我们知道,现在的cpu是按照时间片来完成多任务的执行的,若每个进程的优先级相同,则每个进程执行的时间片分配都是一致的,但实际情况是往往会有低优先级与高优先级进程区分.
ni对每个进程而言也是一个固定的值,负值表示高优先级,正值表示低优先级,数值从-20(最高)到19(最低优先级),我们可以通过改变进程的ni值,灵气获取更多的cpu时间片,这个ni值默认为0.
所以ni指的就是,用户进程空间内该表过优先级使优先级变高的进程占用CPU百分比
wa
wa是等待磁盘读写消耗的cpu时间,在磁盘写入时,cpu需等待磁盘写入完成才可以进行下一步操作
如果top命令下,wa的比例特别高,需要考虑下磁盘的写入是否特别大,针对业务来讲就是要看下日志输出是否过多,引起cpu消耗过多
hi si
hi si是硬中断,软中断耗费的cpu时间.
硬中断是由外部硬件发起的cpu中断信号,由终端控制器提供,如网卡数据来了,键盘按键了之类的都算是硬中断,硬中断的cpu消耗是正常的,但是不会大量消耗,出现了硬中断比例很高,一般是计算机硬件出问题了
可以通过
cat /proc/interrupts来查看
在网络非常heavy的情况下,对于文件服务器,高流量 Web 服务器这样的应用来说,把不同的网卡IRQ均衡绑定到不同的CPU上将会减轻某个CPU的负担,提高多个CPU整体处理终端的能力;对于数据库服务器这样的应用来说,把磁盘控制器绑到一个CPU,把网卡绑定到另一个CPU将会提高数据库的响应时间,优化性能.合理的根据自己的生产环境和应用的特点来平衡IRQ中断有助于提高系统的整体吞吐能力和性能.
至于软中断,知识比硬中断少了一个硬件发送信号的动作,其他与硬中断基本类似.
当前正在运行的代码(或进程)才会产生软终端.这种中断时一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求
也就是说,系统中的硬中断,软中断的CPU消耗是正常的,但如果大量CPU消耗,则需要重点排查.
id,st
id为空闲时间时间占比
st这个项只有主机是虚拟机的时候,才会存在,全称为steel,意味着虚拟机从宿主机获取cpu时间片的消耗百分比,如果这个值过多,则需要查看宿主机是否过多的分配虚拟机,引起资源不足
内存
top的最后两行是内存相关的信息:
Mem: 4106756k total, 4086516k used, 20240k free, 318040k buffers
Swap: 1048568k total, 9240k used, 1039328k free, 1173960k cached第一行Mem显示的是极其的真是内存数
第二行Swap显示的是交换内存数
Mem中,total显示的是内存的总量,这里的单位是大K,也就是约4G左右内存总数,used表示已使用内存数,free是空闲内存数,buffer是buffer内存数,cache为cache的内存数
Swap中,total,used,free三个参数的表示内存交换空间中的总量,已使用内存与空闲空间.
total,used,free都很好理解,无论是Mem中还是Swap中都是一个意思total = used + free.下面重点来看buffers和cache内存占用的说明.
used的内存占用接近了4个G,并不意味着极其内存全部被耗完,windows下用多少申请多少内存,但是linux下则不然,内存总是不嫌多的,linux会将读取过的数据都缓存起来,以便下次读取时减少读取时间.即使你的程序运行结束后,内存也不会自动释放.这就会导致你在linux系统中程序频繁读写文件后,发现物理内存变少.
而cache与buffer就属于linux系统的缓存内存,这部分的缓存内存和其他程序真实真实需要使用内存的时候,则会释放.所以程序真实使用的内存数应该是used - buffer -cache,就上面的数据而言是:
4086516k - 20240k - 318040k = 3748236k大约是3.7g
在linux上使用
free -m$ free -m
total used free shared buffers cached
Mem: 4010 3986 23 0 310 1143
-/+ buffers/cache: 2532 1477
Swap: 1023 9 1014
同样可以看到这些信息
cache和buffer的用途不同,cache表示从硬盘中读取文件中到内存的缓存,例如vim打开一个92M左右的文件,打开前,内存的缓存占用增加93M
OS处理网络数据的速度远超过网卡接受数据,因此需要一个Buffer,等存满了一次性交给OS又比如从数据库获取数据很慢,所以对于不经常修改的数据,就一次性取出,放入Cache,将来就不去数据取了
Buffer是待处理的数据,Cache是处理结果
进程状态
top的最后一行是系统中所有系统的进程情况,开发者可以通过找到指定的进程,然后再去分析进程的详细情况