python web面试题整理-从放弃到入门-day02
第一部分Python基础题(80)
21.列举布尔值为False的常见值?
‘’ False 0 [] () {}
22.字符串、列表、元组、字典每个常用的5个方法?
- String常用的字符串操作
# encoding:utf-8
__author__ = '酸奶'
__date__ = '2019/10/12 15:10'
# 1. 去掉空格和特殊符号
name = " abcdefgeyameng "
name1 = name.strip() # 并不会在原来的字符串上操作,返回一个去除了两边空白的字符串
print(name1, len(name1), name, len(name))
# abcdefgeyameng 14 abcdefgeyameng 17
# 去掉左边的空格和换行符
name2 = name.lstrip()
print(name2, len(name2))# print(name2, len(name2))#
# 去掉右边的空格和换行符
name3 = name.rstrip()
print(name3, len(name3)) # abcdefgeyameng 15
# 2.字符串的搜索和替换
name.count('e') # 查找某个字符在字符串中出现的次数
name.capitalize() # 首字母大写
name.center(100,'-') # 把字符串方中间,两边用-补齐,100表示占位多少
name.find('a') # 找到这个字符返回下标,多个时返回第一个,不存在时返回-1
name.index('a') # 找到这个字符返回下标,多个时返回第一个,不存在时报错
print(name.replace(name,'123')) # 字符串的替换
name.replace('abc','123') # 注意字符串的替换的话,不是在原来的字符串上进行替换.而是返回一个替换后的字符串.
# 3.字符串的测试和替换函数
name.startswith("abc") # 是否以abc开头
name.endswith("def") # 是否以def结尾
name.isalnum() # 是否全是字母和数字,并且至少包含一个字符
name.isalpha() # 是否全是字母,并至少包含一个字符
name.isdigit() # 是否全是数字,并且至少包含一个字符
name.isspace() # 是否全是空白字符,并且至少包含一个字符
name.islower() # 是否全是小写
name.isupper() # 是否全是大写
name.istitle() # 是否是首字母大写
# 4.字符串的分割
name.split('') # 默认按照空格进行分隔,从前往后分隔
name.rsplit() # 从后往前进行分隔
# 5.连接字符串
'.'.join(name) # 用.号将一个可迭代的序列拼接起来
name = 'geyameng'
# 6.截取字符串(切片)
name1 = name[0:3] # 第一位到第三位的字符,和range一样不包含结尾索引
name2 = name[:] # 截取全部的字符
name3 = name[6:] # 截取第6个字符到结尾
name4 = name[:-3] # 截取从开头到最后一个字符之前
name5 = name[-1] # 截取最后一个字符
name6 = name[::-1] # 创造一个与原字符串顺序相反的字符串
name7 = name[:-5:-1] # 逆序截取
列表常用的操作
> 列表的特性
有序的集合
通过偏移来索引,从而读取数据
支持嵌套
是可变的类型
列表是一个有序的可以通过索引修改读取数据的支持嵌套的可变的一个数据集合
# encoding:utf-8
__author__ = '酸奶'
__date__ = '2019/10/12 15:10'
# 1.创建一个列表
list1 = ['1', '2', '3', '4']
list2 = list("1234")
print(list1, list2)
print(list1 == list2)
# 以上创建的两个列表是等价的,都是['1', '2', '3', '4']
# 2.添加新元素
# 末尾追加
a = [1, 2, 3, 4, 5]
a.append(6)
print(a)
# 指定位置的前面插入一个元素
a.insert(2, 100) # 在下标为2的前面插入一个元素100
print(a)
# 扩展列表list.extend(iterable),在一个列表上追加一个列表
a.extend([10, 11, 12])
print(a)
# 3.遍历列表
# 直接遍历
for i in a:
print(i)
# 带索引的遍历列表
for index, i in enumerate(a):
print(i, index)
# 4.访问列表中的值,直接通过下标取值.list[index]
print(a[2])
# 从list删除元素
# List.remove() 删除方式1:参数object 如果重复元素,只会删除最靠前的.
a = [1,2,3]
a.remove(2) # 返回值是None
# List.pop() 删除方式2:pop 可选参数index,删除指定位置的元素 默认为最后一个元素
a = [1,2,3,4,5]
a.pop()
print(a)
a.pop(2)
print(a)
# 终极删除,可以删除列表或指定元素或者列表切片,list删除后无法访问
a = [1,2,3,4,5,6]
del a[1]
print(a) # 1, 3, 4, 5, 6]
del a[1:]
print(a) # 1
del a
# print(a) # 出错,name a is not defined
# 排序和反转代码
# reverse 反转列表
a = [1,2,3,4,5]
a.reverse()
print(a)
# sort 对列表进行排序,默认升序排列.有三个默认参数cmp = None,key = None,reverse = False
# 7.Python的列表的截取与字符串操作类型相同,如下所示
L = ['spam','Spam','SPAM!']
print(L[-1]) # ['SPAM']
# 8.Python列表操作的函数和方法
len(a) # 列表元素的个数
max(a) # 返回列表元素最大值
min(a) # 返回列表元素最小值
list(tuple) #将一个可迭代对象转换为列表
# 列表常用方法总结
a.append(4)
a.count(1)
a.extend([4,5,6])
a.index(3)
a.insert(0,2)
a.remove()
a.pop()
a.reverse()
a.sort()
字典概述
字典是通过键值对来存储数据的一种数据结构,字典是工作键值映射来存取数据的. 数据的访问时通过键,而不是索引.并且字典的无序的可变的序列.
创建字典的方法
创建一个空字典
D = {} 或 D = dict()
通过键构建值都为None的字典
D = dict.fromkeys(['a','b','c']) ==> {'a':None,'b':None,'c':None}
通过zip函数构建字典
D = dict(zip(keyslist,valueslist))
通过赋值表达式元组构造字典(键必须是字符串,因为如果不是字符串,构造的时候也会当成是字符串处理)
D = dict(name='Bob',age=42) ==> {'name':'Bob,'age':42}
成员关系(判断的是key,和value没有关系.字典的成员关系判断只判断key)
if key in D:
pass
列出所有的键,值.注意得到的是一个可迭代对象,而不是列表.用的时候需要转换
D.keys() D.values() D.items() --> 键 + 值
拷贝一个字典的副本 (浅拷贝)
D1 = D.copy()
已知字典的键,获取其对应的值,如果不存在,提供一个默认值. 如果没有提供默认值,这个键对应的值又不存在的时候,就会引发错误.
d_value = D.get(key,default)
合并更新字典
D.update(D2)
删除字典(根据键)以及长度
D.pop(key) len(D) del D[key]
新增或者是修改键对应的值
D[key] = value # 如果key已经存在则修改,如果不存在就创建.
字典键的列表,值的列表
list(D.keys()) list(D.values())
字典推导式
D = [x:x**2 for x in range(10) if x %2 == 0]
字典使用事项
1)序列运算无效(字典是映射机制,不是序列)
2)对新索引的赋值会添加新的键值对
3)键不一定总是字符串(任何不可变对象都可以作为键).
使用字典模拟灵活的列表
问题? 我们都知道使用列表的时候,对在列表中的末尾的偏移赋值时是非法的
L = [1]
L[1] = 2 # 这里会报一个index out of range 的错误.
可以用字典解决这个问题,使用整数作为键时,字典可以效仿列表在偏移赋值时增长.
可以用字典解决这个问题,使用整数作为键时,字典可以效仿列表在偏移赋值时增长
D = {}
D[0] = 1
D[1] = 2
补充,创建字典的方法
如果你事先可以拼接出整个字典,可以这么来创建
D ={'name':'fioman','age':45}
如果你需要动态的创建一个字典,可以这么来创建
D = {}
D['name'] = 'fioman'
D['age'] = 45
如果键都是字符串,并且所有的键的值都知道,则可以这么来创建
D = dict(name = 'Fioman',age = 4)
可以根据两个序列构成一个字典
dct(['name','fioman',('age',45)])
元组
元组概述
任意对象的有序集合,可以通过序列取值
元组不可变的序列的操作类型
固定长度,异构,嵌套(元组里也可以包含元组)
对象引用的数组
常见的操作
创建空元组
t1 = ()
t2 = tuple()
单个元素的元组记得一定加,
x = (40) ==> int数 40
x = (40,) ==> 一个元组,具有一个元素的值是40
多元组的两种表达方式
T = (1,2,3) # T = 1,2,3 括号可以省略
用一个可迭代对象生成元组
T = tuple('abc')
元组的访问
T[i] T[i][j]
合并和重复
T1 + T2 T * 3
迭代和成员关系
for x in T:
print(x)
'spam' in T
对元组进行排序
注意
当对元组进行排序的时候,通常先得将它转换为列表并使得它成为一个可变对象.或者使用
sorted方法,它接收任何序列对象.
T = ('c','a','d','b')
tmp = list(T)
tmp.sort() ==> ['a','b','c','d']
T = tunple(tmp)
sorted(T)
为什么有了列表还要元组
a. 元组可以看成是简单的对象组合,而列表是随着时间而改变的数据集合
b. 元组的不可变性提供了某种完整性.这样可以确保元组不会被另外一个引用来修改.
元组有点类似于其它语言中的常数声明.
集合
集合概述
集合内的元素必须是不可变的,而它本身是可变的容器,集合是无序的,并且里面存放的对象是唯一的不重复的
集合是可迭代的对象,集合相当于是只有键没有值的字典,集合可以作为字典的键.
集合的操作
创建空集合
a = set()
注意不能是 a = {} 这是空字典
b = set(iterable) # 用可迭代对象创建一个集合
集合的运算
& 生成两个集合的交集 s3 = s1 & s2
| 生成两个集合的并集 s3 = s1 | s2
-生成两个集合的补集 s3 = s1 - s2
^ 对称补集 s3 = s1 ^ s2 (只能属于s1或者s2 ,也就是去除掉s1和s2重合的部分)
集合的特殊符号
判断一个集合是否是另外一个集合的超集
< 判断一个集合是否是另外一个集合的补集
23.lambda表达式格式及应用场景?
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
函数名 = lambda 参数 :返回值
#参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
lambda 表达式
temp = lambda x,y:x+y
print(temp(4,10)) # 14
temp = lambda x,y:x*y
print(temp(4,10)) # 40
可替代:
def foo(x,y):
return x+y
print(foo(4,10)) # 14
def foo(x,y):
return x*y
print(foo(4,10)) # 40
我们一般实现两个数相加相乘
a = 1
b = 2
print(a+b)
a = 1
b = 2
print(a*b)
24.pass的作用?
空语句 do nothing
保证格式完整
保证语义完整
if true:
pass #do nothing
else:
#do something
当你在编写一个程序时,执行语句部分思路还没有完成,这时你可以用pass语句来占位,
也可以当做是一个标记,是要过后来完成的代码。比如下面这样:
def iplaypython():
pass
25.*arg和**kwarg的作用?
一个简单的函数
首先我们可以定一个简单的函数, 函数内部只考虑required_arg这一个形参(位置参数)
def exmaple(required_arg):
print required_arg
exmaple("Hello, World!")
>> Hello, World!
那么,如果我们调用函数式传入了不止一个位置参数会出现什么情况?当然是会报错!
exmaple("Hello, World!", "another string")
>> TypeError: exmaple() takes exactly 1 argument (2 given)
定义函数时,使用*arg和**kwarg
*arg和**kwarg 可以帮助我们处理上面这种情况,
允许我们在调用函数的时候传入多个实参
def exmaple2(required_arg, *arg, **kwarg):
if arg:
print "arg: ", arg
if kwarg:
print "kwarg: ", kwarg
exmaple2("Hi", 1, 2, 3, keyword1 = "bar", keyword2 = "foo")
>> arg: (1, 2, 3)
>> kwarg: {'keyword2': 'foo', 'keyword1': 'bar'}
从上面的例子可以看到,当我传入了更多实参的时候
*arg会把多出来的位置参数转化为tuple
**kwarg会把关键字参数转化为dict
再举个例子,一个不设定参数个数的加法函数
def sum(*arg):
res = 0
for e in arg:
res += e
return res
print sum(1, 2, 3, 4)
print sum(1, 1)
>> 10
>> 2
当然,如果想控制关键字参数,可以单独使用一个*,作为特殊分隔符号。
限于Python 3,下面例子中限定了只能有两个关键字参数,
而且参数名为keyword1和keyword2
def person(required_arg, *, keyword1, keyword2):
print(required_arg, keyword1, keyword2)
person("Hi", keyword1="bar", keyword2="foo")
>> Hi bar foo
如果不传入参数名keyword1和keyword2会报错,因为都会看做位置参数!
person("Hi", "bar", "foo")
>> TypeError: person() takes 1 positional argument but 3 were given
调用函数时使用*arg和**kwarg
直接上例子,跟上面的情况十分类似。反向思维。
def sum(a, b, c):
return a + b + c
a = [1, 2, 3]
# the * unpack list a
print sum(*a)
>> 6
def sum(a, b, c):
return a + b + c
a = {'a': 1, 'b': 2, 'c': 3}
# the ** unpack dict a
print sum(**a)
>> 6
26.is和==的区别?
| Is | 比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象,是否指向同一个内存地址。 |
|---|---|
| == | 比较的是两个对象的内容是否相等,默认会调用对象的__eq__()方法。 |
27.请简述下python的深浅拷贝及应用场景?
深浅拷贝用法来自copy模块。
导入模块:import copy
浅拷贝:copy.copy
深拷贝:copy.deepcopy
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等.
字典(列表)的深浅拷贝
赋值:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n2 = n1
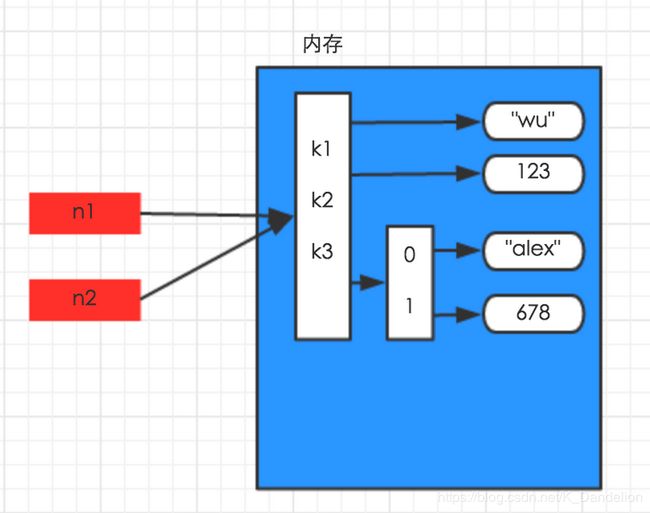 浅拷贝:
浅拷贝:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n3 = copy.copy(n1)
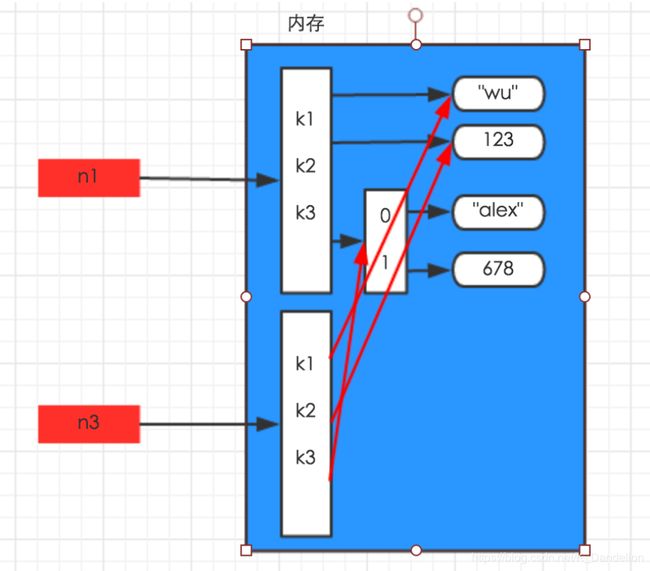 深拷贝:
深拷贝:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n4 = copy.deepcopy(n1)
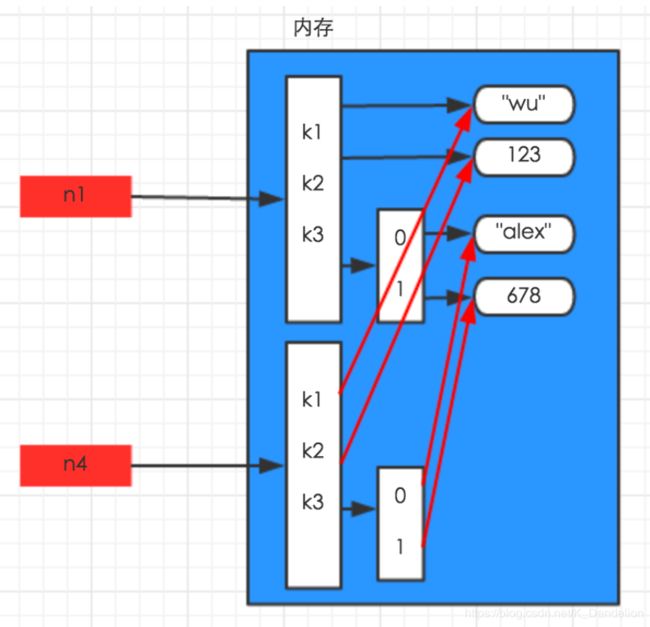
28.python的垃圾回收机制?
我们从三个方面来了解一下Python的垃圾回收机制。
一、引用计数
Python垃圾回收主要以引用计数为主,分代回收为辅。引用计数法的原理是每个对象维护一个ob_ref,用来记录当前对象被引用的次数,也就是来追踪到底有多少引用指向了这个对象,当发生以下四种情况的时候,该对象的引用计数器+1
对象被创建 a=14
对象被引用 b=a
对象被作为参数,传到函数中 func(a)
对象作为一个元素,存储在容器中 List={a,”a”,”b”,2}
与上述情况相对应,当发生以下四种情况时,该对象的引用计数器-1
当该对象的别名被显式销毁时 del a
当该对象的引别名被赋予新的对象, a=26
一个对象离开它的作用域,例如 func函数执行完毕时,
函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
将该元素从容器中删除时,或者容器被销毁时。
.当指向该对象的内存的引用计数器为0的时候,该内存将会被Python虚拟机销毁
下面来补充一下它的源码分析:
Python里面每一个东西都是对象,他们的核心是一个结构体Py_Object,所有Python对象的头部包含了这样一个结构PyObject
// object.h
struct _object {
Py_ssize_t ob_refcnt; # 引用计数值
struct PyTypeObject *ob_type;
} PyObject;
看一个比较具体点的例子,int型对象的定义:
// intobject.h
typedef struct {
PyObject_HEAD
long ob_ival;
} PyIntObject;
简而言之,PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少。当引用计数为0时,该对象生命就结束了。
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
————————————————
垃圾回收、简单了解火候不够
————————————————
29.python的可变类型和不可变类型?
Python中的数据包括:Number(包括Int,Float,Bool和Complex),String,Tuple,List,Dict,Set。
- 可变类型(mutable):列表,字典
- 不可变类型(unmutable):数字,字符串,元组
这里的可变不可变,是指内存中的那块内容(value)是否可以被改变
a = 100
id(a) # 查看内存地址
输出: 493236016
a = a + 100
a
输出: 200
id(a) # 查看内存地址
输出: 493239216
通过id函数查看变量a的内存地址进行验证,a = a +
100并不是在原有的int对象上+100,而是重新创建一个值为200的int对象,a指向这个新的对象。
# int类型
a = 100
b = 100
id(a)
输出: 493236016
id(b)
输出: 493236016
c = 100
id(c)
输出: 493236016
# 字符串类型
a = 'abc'
b = 'abc'
id(a)
输出: 10401864
id(b)
输出: 10401864
c = 'abcd'
id(c)
输出: 80776864
c = 'abc'
id(c)
输出: 10401864
# 浮点型
a = 3.14
b = 3.14
id(a)
输出: 67234432
id(b)
输出: 67234480
# 元组
a = (1,2,3)
b = (1,2,3)
id(a)
输出: 77183880
id(b)
输出: 77002504
对于不可变类型int,无论创建多少个不可变类型,只要值相同,都指向同个内存地址。同样情况的还有比较短的字符串。浮点类型和元组类型则不同(这方面涉及Python内存管理机制,Python对int类型和较短的字符串进行了缓存,无论声明多少个值相同的变量,实际上都指向同个内存地址)。
可变类型
列表、字典属于可变类型。
字典的key只能使用不可变类型定义
a = [1,2,3,4]
id(a)
输出: 80579720
a.append(100)
a
输出: [1, 2, 3, 4, 100]
id(a)
输出: 80579720
list在append之后,还是指向同个内存地址,因为list是可变类型,可以在原处修改。
a = ['a', 'b', 'c']
b = ['a', 'b', 'c']
id(a)
输出: 82985224
id(b)
输出: 80906760
c = ['a', 'b', 'c']
id(c)
输出: 81238344
d = a
id(d)
输出: 82985224
从运行结果可以看出,虽然a、b、c的值相同,但是指向的内存地址不同。如果想让他们内存地址相同可以通过d = a
的赋值语句,让他们指向同个内存地址。
a = [1,2,3]
b = a
b.append(4)
a
输出: [1, 2, 3, 4]
b
输出: [1, 2, 3, 4]
id(a)
输出: 81237960
id(b)
输出: 81237960
通过运行结果可以看出,可变类型a、b指向同个内存地址,对a、b任意一个List进行修改,都会影响另外一个List的值。
a = [1,2,3]
b = [1,2,3]
id(a)
输出: 81173256
id(b)
输出: 81172744
a.append(4)
a
输出: [1, 2, 3, 4]
b
输出: [1, 2, 3]
如果内存地址不同,对a、b任意一个List进行修改,是不会影响另外一个list的。
对不可变类型操作,相当于从新定义了一个新的变量。只是名字相同罢了,但是内存地址不同。对于int型(-5~256)和比较短的字符串(不超过3个以上字符)只要值相同,都指向同个内存地址。
对可变类型操作,相当于直接去修改变量的值。就算两个变量的值相同,所在的内存地址也不同。如果想要把让两个可变类型的内存地址相同可以使用赋值的语句。但是两个内存地址相同的可变类型,改变了其中一个的值,另一个也会跟着被改变。
30.求结果?
v =dict.fromkeys(['k1','k2'],[])
v['k1'].append(666)
print(v)
v['k1']=777
print(v)
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
fromkeys方法语法
dict.fromkeys(iterable[,value=None])
- iterable 用于创建新的字典的键的可迭代对象(字符串,列表,元组,字典)
- value 可选参数,字典所有键对应同一个值的初始值,默认为None
因为所有键对应同一个值,所以对键为‘k1’的值做了添加操作后,其他几个键的值也都添加了相同的值
31.求结果?
闭包延迟绑定
def multipliers():
return [lambda x : i*x for i in range(4)]
print ([m(2) for m in multipliers()] )
[6, 6, 6, 6]
为什么输出结果为[6, 6, 6, 6],这段代码相当于
def multipliers():
funcs = []
for i in range(4):
def bar(x):
return x*i
funcs.append(bar)
return funcs
print ([m(2) for m in multipliers()] )
运行代码,解释器碰到了一个列表解析,循环取multipliers()函数中的值,而multipliers()函数返回的是一个列表对象,这个列表中有4个元素,
每个元素都是一个匿名函数(实际上说是4个匿名函数也不完全准确,其实是4个匿名函数计算后的值,因为后面for i 的循环不光循环了4次,
同时提还提供了i的变量引用,等待4次循环结束后,i指向一个值i=3,这个时候,匿名函数才开始引用i=3,计算结果。所以就会出现[6,6,6,6],
因为匿名函数中的i并不是立即引用后面循环中的i值的,而是在运行嵌套函数的时候,才会查找i的值,这个特性也就是延迟绑定)
改进:
def multipliers():
# 添加了一个默认参数i=i
return [lambda x, i=i: i*x for i in range(4)]
print ([m(2) for m in multipliers()] )
[0, 2, 4, 6]
相当于
def multipliers():
funcs = []
for i in range(4):
def bar(x, i=i):
return x * i
funcs.append(bar)
return funcs
print ([m(2) for m in multipliers()] )
Python的延迟绑定其实就是只有当运行嵌套函数的时候,才会引用外部变量i,不运行的时候,并不是会去找i的值,这个就是第一个函数,为什么输出的结果是[6,6,6,6]的原因。
32.列举常见的内置函数?
1、abs() 此函数返回数字的绝对值。
a = 5
b = -10
print(abs(a)) #输出3
print(abs(b)) #输出5
2、all() 此函数用于判断给定的可迭代参数 iterable 中的所有元素是否都不为 0、都不为False 或者iterable都 为空,如果是返回 True,否则返回 False。
复制代码
print(all(['a', 'b', 'c', 'd'])) # True
print(all(['a', 'b', '', 'd'])) # False
print(all([0, 1,2, 3])) # False
print(all(('a', 'b', '', 'd'))) # False
print(all((0, 1,2, 3))) # False
print(all([])) # True
print(all(())) # True
3、any() 函数用于判断给定的可迭代参数 iterable 是否全部为空对象,如果都为空、都为0、或者都为false,则返回 False,如果不都为空、不都为0、不都为false,则返回 True。
复制代码
print(any(['a', 'b', 'c', 'd'])) # True
print(any(['a', 'b', '', 'd'])) # True
print(any([0, 1,2, 3])) # True
print(any(('a', 'b', '', 'd'))) # True
print(any((0, 1,2, 3))) # True
print(any([])) # False
print(any(())) # False
4、bin() 返回一个整数 int 或者长整数 long int 的二进制表示。
print(bin(10)) #0b1010
print(bin(20)) #0b10100
5、bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
传入布尔类型时,按原值返回
参数如果缺省,则返回False
传入字符串时,空字符串返回False,否则返回True
传入数值时,0值返回False,否则返回True
传入元组、列表、字典等对象时,元素个数为空返回False,否则返回True.
print(bool()) #False
print(bool(True)) #True
print(bool("")) #False
print(bool("123")) #True
print(bool(0)) #False
print(bool(1)) #True
print(bool([])) #False 若元祖和字典为空时 也为False ,不为空 则为True
6、chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。(只能输入数字)
print(chr(65)) #A
print(chr(97)) #a
print(chr(100)) #d
7、cmp(x,y) 函数用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。(python3已经删除了)
8、compile() 函数将一个字符串编译为字节代码。语法:compile(source, filename, mode[, flags[, dont_inherit]])
import re
pattern=re.compile('[a-zA-Z]')
result=pattern.findall('as3SiOPdj#@23awe')
print(result)
9、complex(real,imag) 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
print(complex(1, 2)) #(1 + 2j)
print(complex(1)) #(1 + 0j)
print(complex("3")) #(3+0j)
10、dict() 函数用于创建一个字典。
print(dict(a='a',b='b')) #{'b': 'b', 'a': 'a'}
11、dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
12、python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
13、enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
14、eval() 函数用来执行一个字符串表达式,并返回表达式的值。
15、execfile() 函数可以用来执行一个文件。
16、float() 函数用于将整数和字符串转换成浮点数。
17、frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
18、getattr() 函数用于返回一个对象属性值。
19、hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
20、help() 函数用于查看函数或模块用途的详细说明。
21、hex() 函数用于将10进制整数转换成16进制整数。
22、id() 函数用于获取对象的内存地址。
23、input() 输入函数
24、int() 函数用于将一个字符串会数字转换为整型。
25、isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
26、len() 方法返回对象(字符、列表、元组等)长度或项目个数。
27、list() 方法用于将元组转换为列表。
28、locals() 函数会以字典类型返回当前位置的全部局部变量。
29、long() 函数将数字或字符串转换为一个长整型。
30、max() 方法返回给定参数的最大值,参数可以为序列。
31、memoryview() 函数返回给定参数的内存查看对象(Momory view)。
32、min() 方法返回给定参数的最小值,参数可以为序列。
33、oct() 函数将一个整数转换成8进制字符串。
34、open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
35、ord() 函数与chr()函数相反,输入字符返回数字
36、pow() 方法返回 xy(x的y次方) 的值。函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
37、print() 输出函数
38、range() 函数可创建一个整数列表,一般用在 for 循环中。
39、reload() 用于重新载入之前载入的模块。
40、everse() 函数用于反向列表中元素。
41、round() 方法返回浮点数x的四舍五入值。
42、set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
43、str() 函数将对象转化字符串
44、sum() 方法对系列进行求和计算。
45、tuple() 元组 tuple() 函数将列表转换为元组。
46、type() 返回对象类型。
47、unichr() 该函数和chr()函数功能基本一样, 只不过是返回 unicode 的字符。
48、vars() 函数返回对象object的属性和属性值的字典对象。
49、xrange() 函数用法与 range 完全相同,所不同的是生成的不是一个数组,而是一个生成器。
50、import() 函数用于动态加载类和函数 。如果一个模块经常变化就可以使用 import() 来动态载入。
33.filter、map、reduce的作用?
map 作用是生成一个新数组,遍历原数组,将每个元素拿出来做一些变换然后
放入到新的数组中。
[1, 2, 3].map(v => v + 1) // -> [2, 3, 4]
另外 map 的回调函数接受三个参数,分别是当前索引元素,索引,原数组
[‘1’,‘2’,‘3’].map(parseInt)
第一轮遍历 parseInt('1', 0) -> 1
第二轮遍历 parseInt(‘2’, 1) -> NaN
第三轮遍历 parseInt('3', 2) -> NaN
filter 的作用也是生成一个新数组,在遍历数组的时候将返回值为 true 的元素放入新数组,我们可以利用这个函数删除一些不需要的元素
let array = [1, 2, 4, 6]
let newArray = array.filter(item => item !== 6)
console.log(newArray) // [1, 2, 4]
和 map 一样,filter 的回调函数也接受三个参数,用处也相同。
最后我们来讲解 reduce 这块的内容,同时也是最难理解的一块内容。reduce 可以将数组中的元素通过回调函数最终转换为一个值。
如果我们想实现一个功能将函数里的元素全部相加得到一个值,可能会这样写代码
const arr = [1, 2, 3]
let total = 0
for (let i = 0; i < arr.length; i++) {
total += arr[i]
}
console.log(total) //6
但是如果我们使用 reduce 的话就可以将遍历部分的代码优化为一行代码
const arr = [1,2,3]
const sum = arr.reduce((acc,current)=>acc + current,0)
console.log(sum)
对于 reduce 来说,它接受两个参数,分别是回调函数和初始值,接下来我们来分解上述代码中 reduce 的过程
首先初始值为 0,该值会在执行第一次回调函数时作为第一个参数传入
回调函数接受四个参数,分别为累计值、当前元素、当前索引、原数组,
后三者想必大家都可以明白作用,这里着重分析第一个参数
在一次执行回调函数时,当前值和初始值相加得出结果 1,该结果会在
第二次执行回调函数时当做第一个参数传入
所以在第二次执行回调函数时,相加的值就分别是 1 和 2,以此类推,循环结束后得到结果 6
想必通过以上的解析大家应该明白 reduce 是如何通过回调函数将所有元素最终转换为一个值的,当然 reduce 还可以实现很多功能,接下来我们就通过 reduce 来实现 map 函数
const arr = [1, 2, 3]
const mapArray = arr.map(value => value * 2)
const reduceArray = arr.reduce((acc, current) => {
acc.push(current * 2)
return acc
}, [])
console.log(mapArray, reduceArray) // [2, 4, 6]
34.一行代码实现9*9乘法表?
[[print(f"{i} x {j} = {i * j}", end=' ') if (i + 1) > j else print('\n') for j in range(1, i + 2)] for i in range(1, 10)]
for i in range(1,10):
for j in range(1,i+1):
print(f"{i} x {j} = {i * j}", end=' ')
#print("{0}*{1}={2}".format(i,j,i*j), end=' ')
print()
1 x 1 = 1
2 x 1 = 2 2 x 2 = 4
3 x 1 = 3 3 x 2 = 6 3 x 3 = 9
4 x 1 = 4 4 x 2 = 8 4 x 3 = 12 4 x 4 = 16
5 x 1 = 5 5 x 2 = 10 5 x 3 = 15 5 x 4 = 20 5 x 5 = 25
6 x 1 = 6 6 x 2 = 12 6 x 3 = 18 6 x 4 = 24 6 x 5 = 30 6 x 6 = 36
7 x 1 = 7 7 x 2 = 14 7 x 3 = 21 7 x 4 = 28 7 x 5 = 35 7 x 6 = 42 7 x 7 = 49
8 x 1 = 8 8 x 2 = 16 8 x 3 = 24 8 x 4 = 32 8 x 5 = 40 8 x 6 = 48 8 x 7 = 56 8 x 8 = 64
9 x 1 = 9 9 x 2 = 18 9 x 3 = 27 9 x 4 = 36 9 x 5 = 45 9 x 6 = 54 9 x 7 = 63 9 x 8 = 72 9 x 9 = 81
35.如何安装第三方模块、以及你用过的哪些第三方模块?
模块安装方式分为两种:在线安装与离线安装
1.傻瓜式安装
直接在命令行窗口输入命令 pip install pymysql 、pip install redis
2.手动安装
(1) 百度搜索:python redis
(2) 找到网址:https://pypi.python.org/pypi/redis#downloads,下载安装包
(3) 安装whl结尾的安装包
shift+右键,在此处打开命令行窗口(或者在地址栏中直接输入cmd)
pip install redis-2.10.6-py2.py3-none-any.whl
(4) 安装tar.gz结尾的安装包
a、解压这个压缩包
b、进入到这个解压之后的文件夹里面(shift+右键,在此处打开命令行窗口(或者在地址栏中直接输入cmd))
c、在命令行里面运行 python setup.py install 3、卸载模块
pip uninstall xxx #卸载
36.至少列举8个常用模块?
模块实质上就是一个python文件,它是用来组织代码的,意思就是说把python代码写到里面,文件名就是模块的名称,test.py
test就是模块名称。什么是包?
包,package本质就是一个文件夹,和文件夹不一样的是它有一个__init__.py文件,包是从逻辑上来组织模块的,也就是说它是用来存放模块的,如果你想导入其他目录下的模块,那么这个目录必须是一个包才可以导入。
1、Django
2、pip
3、pillow-python
4、pygame
5、pyMysql
6、pytz
7、opencv-python
8、numpy
9.os、sys模块
10.random模块
11.time&datetime模块
12.re模块是正则表达式模块,用来匹配一些特定的字符串
37.re的match和search的区别?
**
1、match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配;
2、也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
**
import re
print(re.match('super', 'superstition').span()) # (0,5)
print(re.match('super', 'insuperable')) # None
search()会扫描整个字符串并返回第一个成功的匹配:
import re
print(re.search('super', 'superstition').span()) #(0,5)
print(re.search('super', 'insuperable')) # <_sre.SRE_Match object; span=(2, 7), match='super'>
其中span函数定义如下,返回位置信息:
span([group]):
返回(start(group), end(group))。
38.什么是正则的贪婪匹配?
贪婪匹配:正则表达式一般趋向于最大长度匹配。
非贪婪匹配:匹配到结果就好。
默认是贪婪模式。在量词后面直接加一个问号?就是非贪婪模式。
详情参考:正则表达式的贪婪和非贪婪匹配
39.求结果?
a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
40.求结果?
a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2