Scrapy爬取电商网站京东奶粉商品价格数据-附各种问题解决
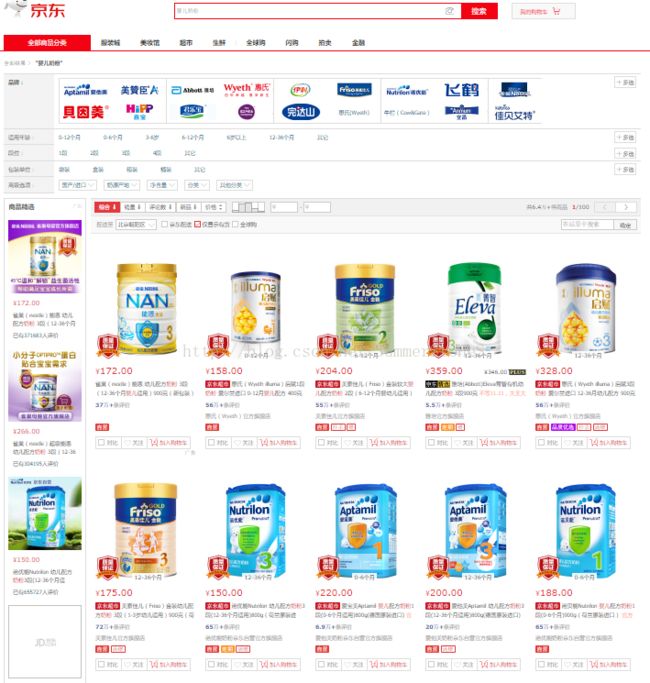
主要的目标是爬奶粉的价格,商品名称和sku_id,想知道奶粉的平均价格。
首先在cmd里建立一个新的scrapy spider project
(1)scrapy startproject milkprice 创建一个项目
(2)创建一个spider,注意要先cd到有.cfg的路径下创建
用scrapy genspider -l 命令可以查看spider模板
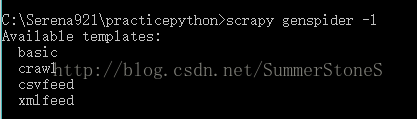
scrapy genspider -t
创建好了以后项目文件里会生成scrapy预置的框架,集合了爬取,保存以及一些爬取中的设置。
在spiders文件夹里打开我们刚才命名的那个spider;
class JingdongSpider(scrapy.Spider):
name = 'jingdong'
allowed_domains = ['search.jd.com']
start_urls = ['https://search.jd.com/s_new.php?keyword=%E5... ...page=1。。。',
'https://search.jd.com/s_new.php?key... ...page=2。。。']start_urls是在spider启动时进行爬取的url列表,可以是一个也可以是多个,可以给一个初始的url,在后面的parse里解析页面时拿到下一页的url然后自动继续爬取或者一开始我们知道每页的url,就可以都放在start_urls里。
京东的商品每页的url长一个样子,只需要该page的数字,所以可以事先都列在这。
spider对每个url会进行访问,得到一个response,然后对这个response解析,生成item对象,送到pipeline里保存我们的数据,同时还能负责生成下一个request对象;
现在我们来定义解析函数parse
def parse(self, response):
"""
直接获取每个sku-data
"""
product = MilkpriceItem()
sku_list = response.xpath('//li[@class="gl-item"]')
name_selector = response.xpath('//div[@class="p-name p-name-type-2"]//em')
for i in range(len(sku_list)):
product['sku_id'] = sku_list[i].xpath('./@data-sku').extract()[0]
product['price'] = float(sku_list[i].xpath('.//div[@class="p-price"]//i//text()').extract()[0])
product['brand'] = name_selector[i].xpath('./text()').extract()[0]
product['name'] = name_selector[i].xpath('./text()').extract()[1:]
yield product
我们可以看到每个商品的信息都非常整齐地在li class='gl-item'里呆着,所以我们可以先拿到所有商品的li元素,以便于获取到data-sku属性。
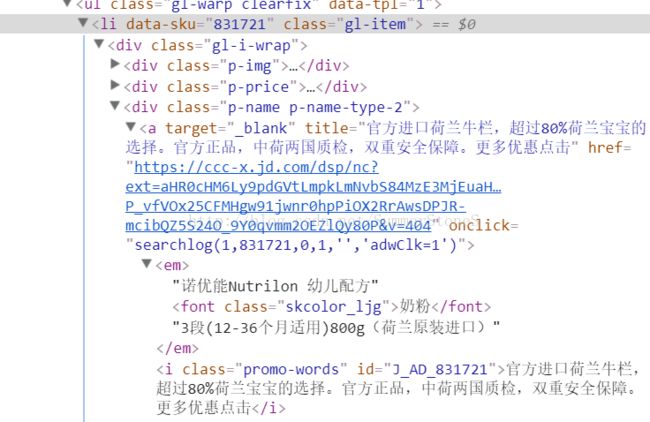

为了取到商品的名称信息,我们先获取到em元素这个selector,然后再逐一取text,可以生成一个商品的名字的列表。
在pipelines里可以用csvitemexporter,jsonitemexporter写入每个item,或者自己定义数据库链接,将数据保存到数据库里。
from scrapy.exporters import CsvItemExporter
class MilkpriceItemCsvPipeline(object):
def open_spider(self, spider):
self.file = open('milkprice.csv', 'wb')
self.exporter = CsvItemExporter(self.file)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return itemITEM_PIPELINES = {
'milkprice.pipelines.MilkpriceItemCsvPipeline': 300,
}# Obey robots.txt rules ROBOTSTXT_OBEY = False
settings里有诸多有用的控制。比如上面这个。它的默认值是True,但是在爬京东的过程中,没有找到robot.txt,就会不停redirect到京东首页,迟迟不能按照我的url爬。在这里把它改成false就好啦。
DOWNLOAD_DELAY = 10
设置下载延迟,默认是3,单位是秒,可以有小数点
COOKIES_ENABLED = False 不向web_server发送cookies,一般为了性能为了反爬最后都禁止。
DEFAULT_REQUEST_HEADERS = {
# "Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
# "Accept-Language": "en-US,en;q=0.8",
"Connection": "keep-alive",
。。。
。。。
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
# "X-Requested-With": "XMLHttpRequest",
}然后我们可以启动项目scrapy crawl

还可以打开保存的csv查看
下面开始说下项目中遇到的问题:
1. xpath相关:
(1)对selector对象再取xpath的时候,前面一定要加上‘.’,表示选取当前节点
(2)//是相对路径,表示这个元素后所有满足要求的元素,/是绝对路径,表示紧跟其后的
(3)选取根元素后面多个text应该逐一取到这个根元素的selector,然后取text(),可以得到一个text的list
2. scrapy shell相关:
正常我们用scrapy shell调试xpath 可以简简单单的scrapy shell url,但是这次经常打不开正确的url
(1)检查response是不是正确的url的response,可以通过response.url和view(response)在浏览器打开url来检查
(2)先打scrapy shell命令, 然后用fetch('url'),用这个方法竟然就打开了。。。
(3)要传入headers咋办?在scrapy shell 里,
from scrapy import Request
req=Request(url, headers={"ddd" : "dddd",... ...})
fetch(req)
(4)加user agent scrapy shell -s USER_AGENT='…' url
3. 动态加载问题:
一开始使用的url是进去京东搜索奶粉后的url,但是爬着爬着遇到两个问题
(1)在商品list页面我只能抓到30个,但实际陈列了60个,咋回事呢,原来是需要手动往下拉去加载剩下30个,这也解释了为啥第一页是page=1,第二页就是page=3了,其实是有page=2的...汗,看到了好多按照page=1,3,5,7,9...抓的同学
(2)进入了商品详情url后,发现抓不到价格了,OMG。。。咋回事,发现也变成是js,网页去动态请求了价格数据。
解决方案就是用inspect里的network,看看这些url都默默低做了些啥。

点了network之后刷新页面,然后我们会看到前30个商品的信息;左上角那个ban的符号,是clear已经load好的数据,我们点一下清除第一页的数据;然后把页面往下拉,让页面加载剩下30个商品,然后看到network里面name列里的各种返回数据,同过看他们的response,我们可以找到我们需要的信息。比如说剩下30个信息就藏在这个s_new。。。。request里,在headers里我能看到它的url和headers信息,于是乎,我们就可以用这个url和headers来访问。
4.不按照指定url爬,总是redirect

到settings里修改ROBOTSTXT_OBEY为false
5. 价格获取不到的报错
多爬几页的话就会遇到有些东西价格信息拿不到的情况,为了不影响该页其他商品的爬取,对原代码做一点修正
price = sku_list[i].xpath('.//div[@class="p-price"]//i//text()').extract_first()
if price:
product['price'] = float(price)
else:
product['price'] = ''