缓存中的那些事儿:一致性Hash原理与实现
前言
互联网公司中,绝大部分都没有马爸爸系列的公司那样财大气粗,他们即没有强劲的服务器、也没有钱去购买昂贵的海量数据库。那他们是怎么应对大数据量高并发的业务场景的呢?
这个和当前的开源技术、海量数据架构都有着不可分割的关系。比如通过mysql、nginx等开源软件,通过架构和低成本的服务器搭建千万级别的用户访问系统。
怎么样搭建一个好的系统架构,这个话题我们能聊上个七天七夜。这里我主要结合Redis集群来讲一下一致性Hash的相关问题。
详情
Redis集群的使用
我们在使用Redis的过程中,为了保证Redis的高可用,我们一般会对Redis做主从复制,组成Master-Master或者Master-Slave的形式,进行数据的读写分离,如下图所示:
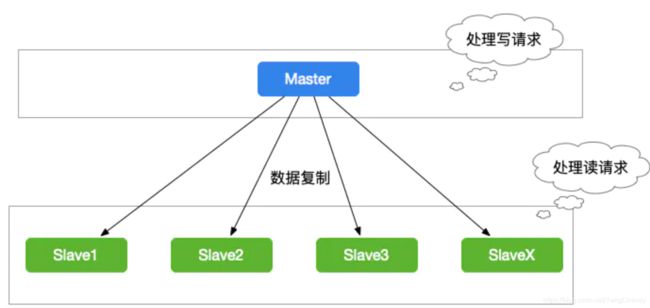
当缓存数据量超过一定的数量时,我们就要对Redis集群做分库分表的操作。
来个栗子,我们有一个电商平台,需要使用Redis存储商品的图片资源,存储的格式为键值对,key值为图片名称,Value为该图片所在的文件服务器的路径,我们需要根据文件名,查找到文件所在的文件服务器上的路径,我们的图片数量大概在3000w左右,按照我们的规则进行分库,规则就是随机分配的,我们以每台服务器存500w的数量,部署12台缓存服务器,并且进行主从复制,架构图如下图所示:
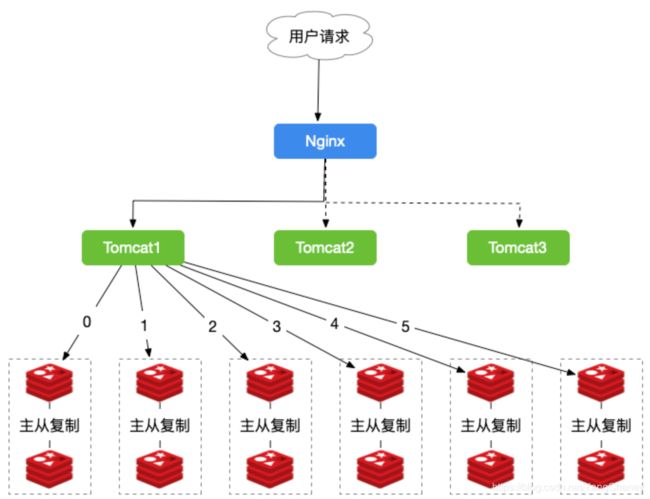
由于我们定义的规则是随机的,所以我们的数据有可能存储在任何一组Redis中,比如我们需要查询"product.png"的图片,由于规则的随机性,我们需要遍历所有Redis服务器,才能查询得到。这样的结果显然不是我们所需要的。所以我们会想到按某一个字段值进行Hash值、取模。所以我们就看看使用Hash的方式是怎么进行的。
使用Hash的Redis集群
如果我们使用Hash的方式,每一张图片在进行分库的时候都可以定位到特定的服务器,示意图如图所示:
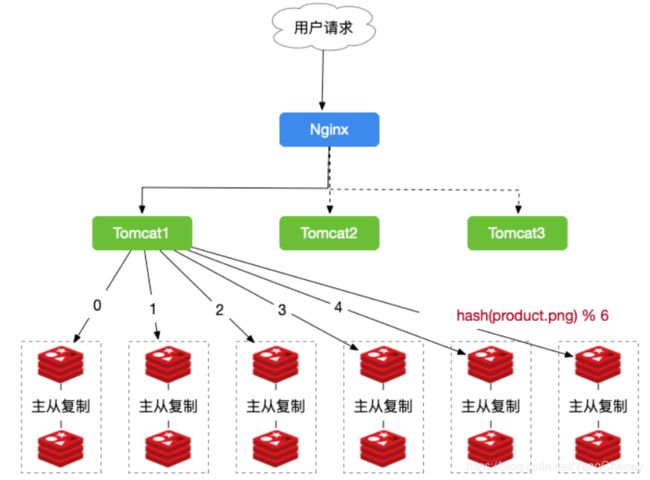
从上图中,我们需要查询的是图product.png,由于我们有6台主服务器,所以计算的公式为:hash(product.png) % 6 = 5, 我们就可以定位到是5号主从,这们就省去了遍历所有服务器的时间,从而大大提升了性能。
使用Hash时遇到的问题
在上述hash取模的过程中,我们虽然不需要对所有Redis服务器进行遍历而提升了性能。但是,使用Hash算法缓存时会出现一些问题,Redis服务器变动时,所有缓存的位置都会发生改变。
比如,现在我们的Redis缓存服务器增加到了8台,我们计算的公式从hash(product.png) % 6 = 5变成了hash(product.png) % 8 = ? 结果肯定不是原来的5了。
再者,6台的服务器集群中,当某个主从群出现故障时,无法进行缓存,那我们需要把故障机器移除,所以取模数又会从6变成了5。我们计算的公式也会变化。
由于上面hash算法是使用取模来进行缓存的,为了规避上述情况,Hash一致性算法就诞生了~~
一致性Hash算法原理
一致性Hash算法也是使用取模的方法,不过,上述的取模方法是对服务器的数量进行取模,而一致性的Hash算法是对2的32方取模。即,一致性Hash算法将整个Hash空间组织成一个虚拟的圆环,Hash函数的值空间为0 ~ 2^32 - 1(一个32位无符号整型),整个哈希环如下:
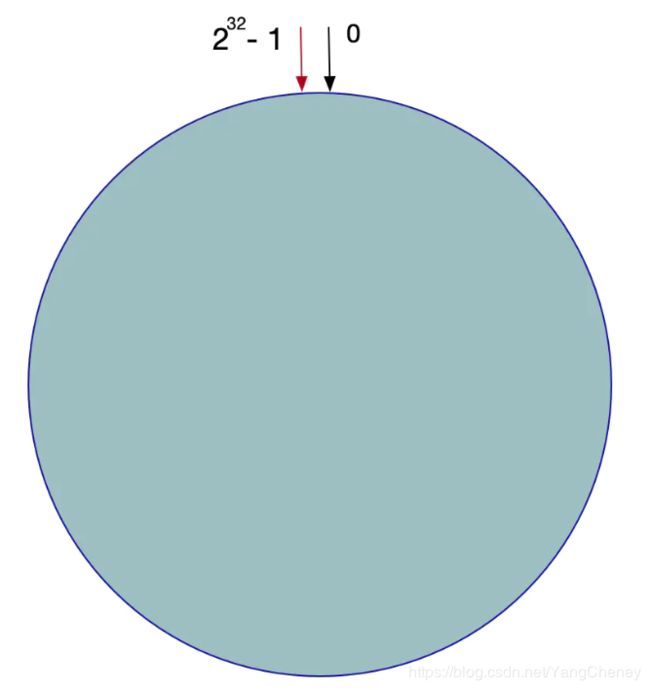
整个圆环以顺时针方向组织,圆环正上方的点代表0,0点右侧的第一个点代表1,以此类推。
第二步,我们将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台服务器就确定在了哈希环的一个位置上,比如我们有三台机器,使用IP地址哈希后在环空间的位置如图所示:
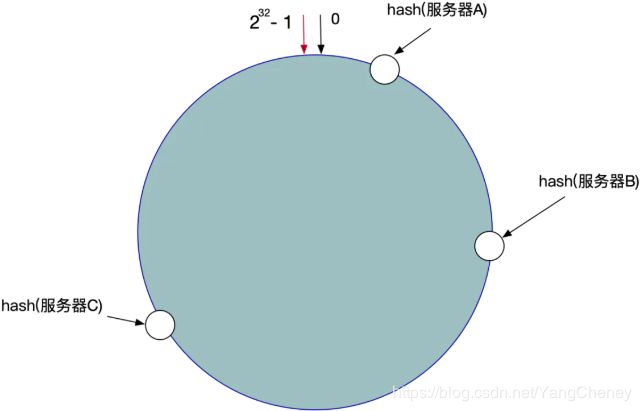
现在,我们使用以下算法定位数据访问到相应的服务器:
将数据Key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针查找,遇到的服务器就是其应该定位到的服务器。
例如,现在有ObjectA,ObjectB,ObjectC三个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性算法,Object -> NodeA,ObjectB -> NodeB, ObjectC -> NodeC
一致性Hash算法的容错性和可扩展性
现在,假设我们的Node C宕机了,我们从图中可以看到,A、B不会受到影响,只有Object C对象被重新定位到Node A。所以我们发现,在一致性Hash算法中,如果一台服务器不可用,受影响的数据仅仅是此服务器到其环空间前一台服务器之间的数据(这里为Node C到Node B之间的数据),其他不会受到影响。如图所示:
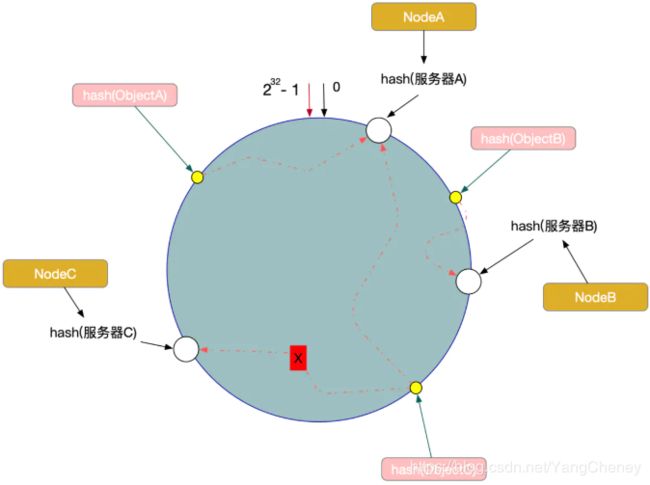
另外一种情况,现在我们系统增加了一台服务器Node X,如图所示:
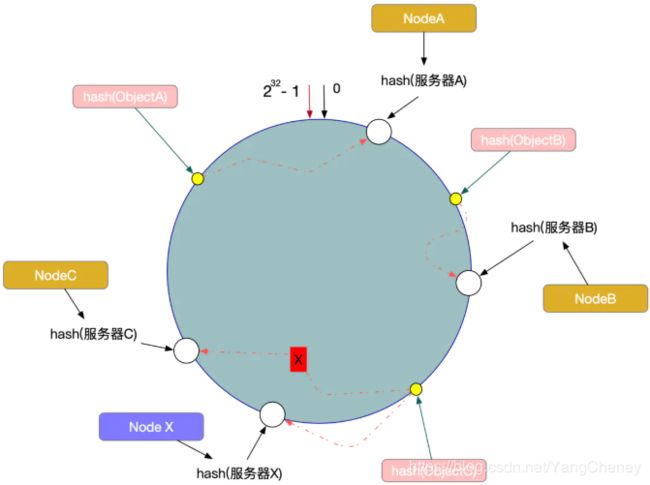
此时对象ObjectA、ObjectB没有受到影响,只有Object C重新定位到了新的节点X上。
如上所述:
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,有很好的容错性和可扩展性。
数据倾斜问题
在一致性Hash算法服务节点太少的情况下,容易因为节点分布不均匀面造成数据倾斜(被缓存的对象大部分缓存在某一台服务器上)问题,如图特例:
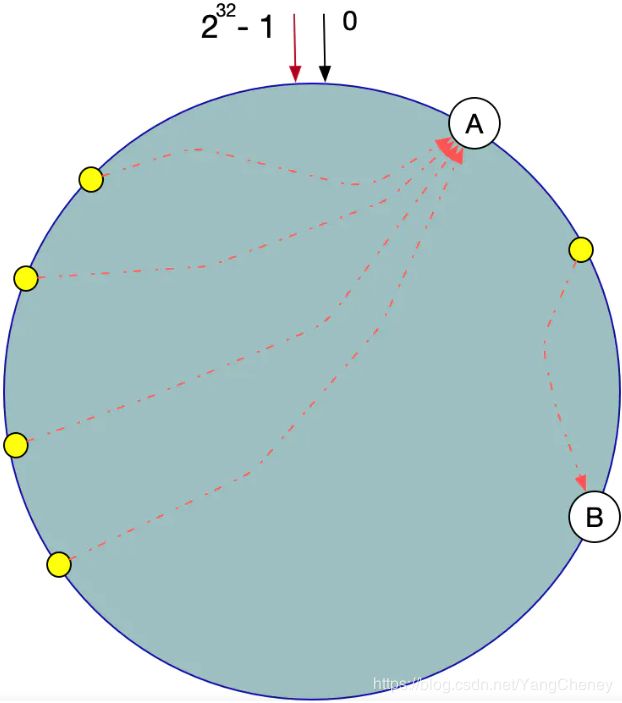
这时我们发现有大量数据集中在节点A上,而节点B只有少量数据。为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务器节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体操作可以为服务器IP或主机名后加入编号来实现,实现如图所示:
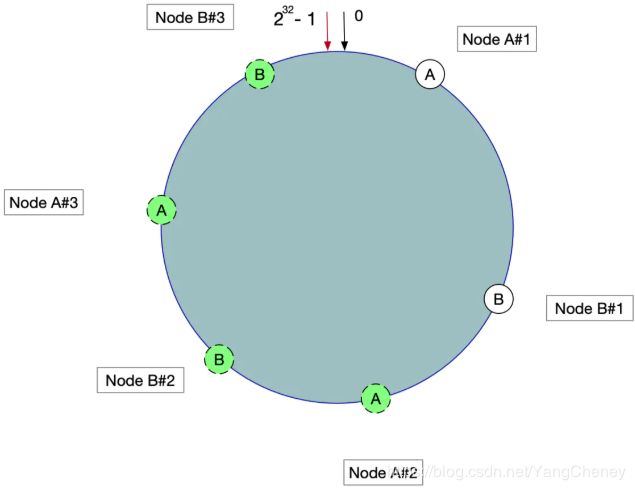
数据定位算法不变,只需要增加一步:虚拟节点到实际点的映射。
所以加入虚拟节点之后,即使在服务节点很少的情况下,也能做到数据的均匀分布。
具体实现
- 算法接口类
public interface IHashService {
Long hash(String key);
}
- 算法接口实现类
public class HashService implements IHashService {
/**
* MurMurHash算法,性能高,碰撞率低
*
* @param key String
* @return Long
*/
public Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN);
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}
- 模拟机器节点
public class Node<T> {
private String ip;
private String name;
public Node(String ip, String name) {
this.ip = ip;
this.name = name;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 使用IP当做hash的Key
*
* @return String
*/
@Override
public String toString() {
return ip;
}
}
- 一致性Hash操作
public class ConsistentHash<T> {
// Hash函数接口
private final IHashService iHashService;
// 每个机器节点关联的虚拟节点数量
private final int numberOfReplicas;
// 环形虚拟节点
private final SortedMap<Long, T> circle = new TreeMap<Long, T>();
public ConsistentHash(IHashService iHashService, int numberOfReplicas, Collection<T> nodes) {
this.iHashService = iHashService;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
/**
* 增加真实机器节点
*
* @param node T
*/
public void add(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.put(this.iHashService.hash(node.toString() + i), node);
}
}
/**
* 删除真实机器节点
*
* @param node T
*/
public void remove(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.remove(this.iHashService.hash(node.toString() + i));
}
}
public T get(String key) {
if (circle.isEmpty()) return null;
long hash = iHashService.hash(key);
// 沿环的顺时针找到一个虚拟节点
if (!circle.containsKey(hash)) {
SortedMap<Long, T> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
}
- 测试类
public class TestHashCircle {
// 机器节点IP前缀
private static final String IP_PREFIX = "192.168.0.";
public static void main(String[] args) {
// 每台真实机器节点上保存的记录条数
Map<String, Integer> map = new HashMap<String, Integer>();
// 真实机器节点, 模拟10台
List<Node<String>> nodes = new ArrayList<Node<String>>();
for (int i = 1; i <= 10; i++) {
map.put(IP_PREFIX + i, 0); // 初始化记录
Node<String> node = new Node<String>(IP_PREFIX + i, "node" + i);
nodes.add(node);
}
IHashService iHashService = new HashService();
// 每台真实机器引入100个虚拟节点
ConsistentHash<Node<String>> consistentHash = new ConsistentHash<Node<String>>(iHashService, 500, nodes);
// 将5000条记录尽可能均匀的存储到10台机器节点上
for (int i = 0; i < 5000; i++) {
// 产生随机一个字符串当做一条记录,可以是其它更复杂的业务对象,比如随机字符串相当于对象的业务唯一标识
String data = UUID.randomUUID().toString() + i;
// 通过记录找到真实机器节点
Node<String> node = consistentHash.get(data);
// 再这里可以能过其它工具将记录存储真实机器节点上,比如MemoryCache等
// ...
// 每台真实机器节点上保存的记录条数加1
map.put(node.getIp(), map.get(node.getIp()) + 1);
}
// 打印每台真实机器节点保存的记录条数
for (int i = 1; i <= 10; i++) {
System.out.println(IP_PREFIX + i + "节点记录条数:" + map.get(IP_PREFIX + i));
}
}
}
- 运行结果如下:
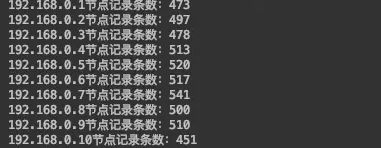
每台机器映射的虚拟节点越多,则分布的越均匀~~~
感兴趣的同学可以拷贝上面的代码运行尝试一下。
参考资料 & 致谢
【1】一致性哈希的基本概念
【2】一致性Hash原理与实现