requests+BeautifulSoup爬取猫眼电影top100
首先测试一下网页是否有用
import requests,json
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
response=requests.get(url,headers=headers)
try:
if response.status_code==200: #如果状态码为200,则返回抓取的网页文本
return response.text
return None
except RequestException:
return print("访问页面错误(●'◡'●)")
def main():
url = 'https://maoyan.com/board/4?offset=0'
html=get_one_page(url)
print(html)
if __name__ == '__main__':
main()运行成功,返回如下text。这一段包含我们想要爬去的所有的内容。
9

![千与千寻]()
9.3


先获取第一页的内容
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
body = soup.select('.board-wrapper dd')
for i in body:
yield{
'index':i.select('.board-index')[0].get_text() ,
#排名
'name':i.select('.name a ')[0].get_text() ,
#电影名
'img':i.select('.board-img')[0].attrs['data-src'],
#图片链接
'star':i.select('.star')[0].get_text().strip() , #用strip去除两边空格
#演员
'releasetime':i.select('.releasetime')[0].get_text()[5:], #用切片把上映时间去掉
#上映时间
}
def main():
url = 'https://maoyan.com/board/4?offset=0'
html = get_one_page(url)
dy = parse_one_page(html)
for item in dy:
print(item)这里需要注意的一点是,在获取图片链接的时候,并不是调试工具中显示的这样
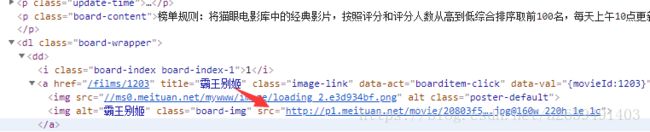
我在爬链接的时候一直报错,然后通过对比爬去到的整个页面的时候发现了问题的 根源,原来这里是data-src

接着把爬去到的内容下载并存入文本
def main():
url = 'https://maoyan.com/board/4?offset=0'
html = get_one_page(url)
dy = parse_one_page(html)
with open('dianying.txt','a',encoding='utf8') as f:
for item in dy:
#禁用ascii码防止乱码
f.write(json.dumps(item,ensure_ascii=False)+'\n')
print(item)
完美的爬下第一页
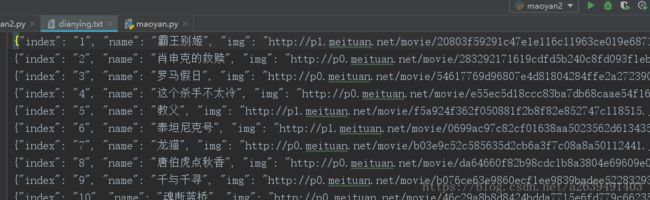
爬下第一页后,自然是要爬下所有页,通过观察,我们发现URL的offset每次翻页都改变10。因此我们只需要稍微的改造一下就能完成翻页效果。
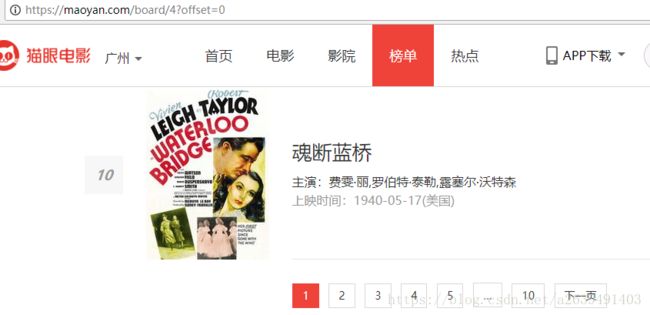
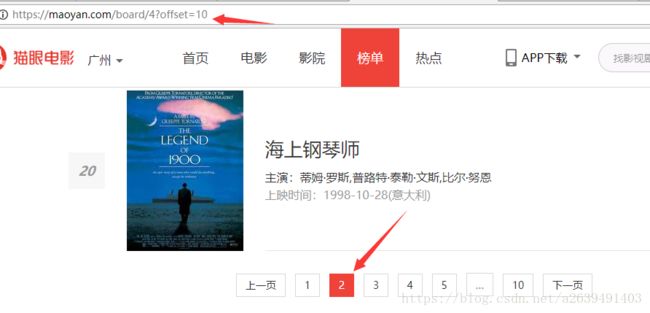
改变一下url
def main(offset):
url = 'https://maoyan.com/board/4?offset='+str(offset)if __name__ == '__main__':
#offset的每次变化都是+10,只需要循环就OK了
for i in range(10):
offset=i*10
main(offset)完整代码
import requests,json
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
response=requests.get(url,headers=headers)
try:
if response.status_code==200: #如果状态码为200,则返回抓取的网页文本
return response.text
return None
except RequestException:
return print("访问页面错误(●'◡'●)")
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
body = soup.select('.board-wrapper dd')
for i in body:
yield{
'index':i.select('.board-index')[0].get_text() ,
#排名
'name':i.select('.name a ')[0].get_text() ,
#电影名
'img':i.select('.board-img')[0].attrs['data-src'],
#图片链接
'star':i.select('.star')[0].get_text().strip() , #用strip去除两边空格
#演员
'releasetime':i.select('.releasetime')[0].get_text()[5:], #用切片把上映时间去掉
#上映时间
}
def main(offset):
url = 'https://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
dy = parse_one_page(html)
with open('dianying.txt','a',encoding='utf8') as f:
for item in dy:
#禁用ascii码防止乱码
f.write(json.dumps(item,ensure_ascii=False)+'\n')
print(item)
if __name__ == '__main__':
#offset的每次变化都是+10,只需要循环就OK了
for i in range(10):
offset=i*10
main(offset)