Selenium+ChromeDriver框架,Selenium入门,百度搜索,猫眼电影,京东商城案例
目录
一、什么是Selenium
二、Selenium相当于机器人
三、Selenium非常简单
四、下载ChromeDiver(Windows教程)
五、Selenium基础用法
1,浏览器对象(browser)方法
2,定位结点(单元素,返回一条结果,返回类型为string)
3,定位结点(多元素,返回多个结果,返回类型为集合)
4,无界面模式(无头模式)
5,Selenium键盘操作
6,Selenium鼠标操作
7,切换页面
8,子页面切换
六、猫眼电影爬取(鼠标点击案例)
七、 京东商品爬取(键盘+鼠标案例)
八、QQ邮箱登录(子页面跳转案例)
一、什么是Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
二、Selenium相当于机器人
基于以上的Selenium的描述,我们知道Selenium可以模拟人的操作,比如鼠标点击,搜索栏搜索,切换页面等操作。从这一点上看,他可以充当一个智能机器人,按照我们的命令去做一些事情,这些事情往往是繁琐的,重复的,耗费时间的。如果我们要将链家二手房网页上的所有房源信息保存到文件中,如果一条条的去复制可能要弄几天上月,粘贴复制粘贴复制,下一页,粘贴复制,如此循环。只有几十页还好,如果有成百上千页,谁愿意干?
三、Selenium非常简单
Selenium上手非常简单,哪怕是一个没有做过编程的人都可以做出来,接下来我们通过一个小的例子来说明:
下面这段代码帮我们做了这样的事情,打开浏览器-》进入百度-》搜索周杰伦。你现在可能看不懂下面的代码,那接下来就学一下Selenium的语法。
from selenium import webdriver
#打开浏览器
browser=webdriver.Chrome()
#输入URl
browser.get("http://www.baidu.com")
#找到搜索框
node=browser.find_element_by_xpath('//*[@id="kw"]')
#搜索周杰伦
node.send_keys("周杰伦")
#找到点击按钮
su=clink=browser.find_element_by_xpath('//*[@id="su"]')
#点击搜索
su.click()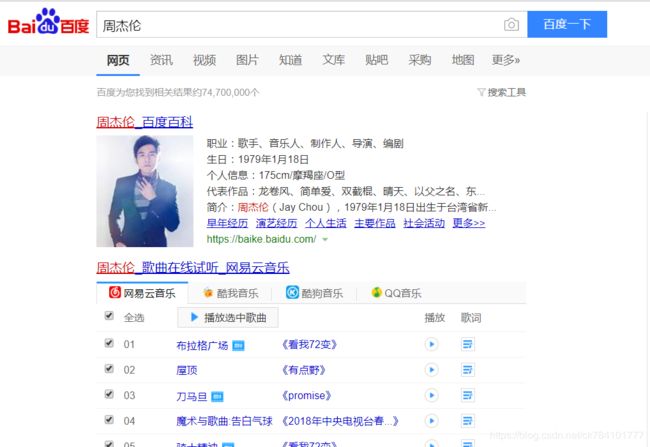
四、下载ChromeDiver(Windows教程)
Chrome是谷歌浏览器,Diver是驱动的意思,谷歌驱动,我们需要下载这个驱动来配合Selenium的使用,下载地址:
http://chromedriver.storage.googleapis.com/index.html
下载之前看一下谷歌浏览器的版本,我的是78.0.3904.108,下载对应的版本即可。
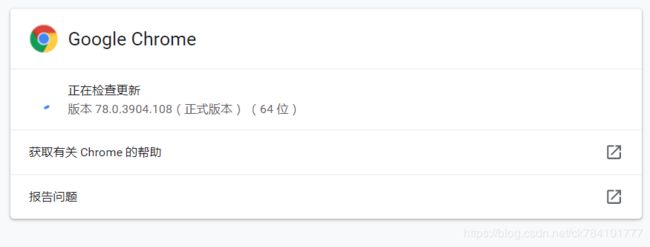
好像没有我这个子版本,选择一个最接近的即可
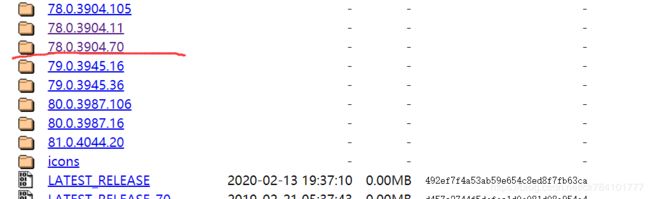
下载完之后,打开控制台,输入where python,显示python安装路径,取python.exe之前的路径即可

把下载的文件拖到Scripts里面


Linux版本安装方式:
$ cp chromedriver /usr/bin
$ chmod 777 /usr/bin/chromedriver
五、Selenium基础用法
1,浏览器对象(browser)方法
browser=webdriver.Chrome(executable_path=")
#创建browser浏览器对象,executable_path="是chromeDriver的存放地址,如果你把它放到了python的script可以不用写
browser.get(url) #打开浏览器并输入url
browser.page_source #返回browser的网页源码
browser.page_source.find('字符串') #在网页源码中找到某字符串,没有找到返回-1
browser.quit() #关闭浏览器
2,定位结点(单元素,返回一条结果,返回类型为string)
browser=webdriver.Chrome() #生成对象后使用
browser.find_element_by_id('') #通过标签的id值来找元素
browser.find_element_by_name('') #通过标签的name值来找元素
browser.find_element_by_class_name('') #通过标签的class_name值来找元素
browser.find_element_by_xpath('') #通过xpath匹配来找元素
browser.find_element_by_link_text('') #通过连接地址找元素
3,定位结点(多元素,返回多个结果,返回类型为集合)
与返回单元素的差别是在element后面多加一个s
browser=webdriver.Chrome() #生成对象后使用
browser.find_elements_by_id('') #通过标签的id值来找元素
browser.find_elements_by_name('') #通过标签的name值来找元素
browser.find_elements_by_class_name('') #通过标签的class_name值来找元素
browser.find_elements_by_xpath('') #通过xpath匹配来找元素
browser.find_elements_by_link_text('') #通过连接地址找元素
4,无界面模式(无头模式)
Selenium正常情况下会打开浏览器,这样比较消耗资源,可以设置无界面模式,如下:
options=webdriver.ChromeOptions()
options.add_argument("--headless")
browser=webdriver.Chrome(options=options)
5,Selenium键盘操作
需要导入模块:from selenium.webdriver.common.keys import Keys
browser=webdriver.Chrome() #生成对象后使用
browser.find_element_by_id('搜索框的id').send_keys('搜索内容') # 在搜索框中输入
browser.find_element_by_id('搜索框的id').send_keys(Keys.SPACE) # 输入空格
browser.find_element_by_id('搜索框的id').send_keys(Keys.CONTROL,'a') # 模拟全选中 Ctrl+a
browser.find_element_by_id('搜索框的id').send_keys(Keys.CONTROL,'c') # 模拟复制 Ctrl+c
browser.find_element_by_id('搜索框的id').send_keys(Keys.CONTROL,'v') # 模拟粘贴 Ctrl+v
browser.find_element_by_id('搜索框的id').send_keys(Keys.ENTER) # 模拟回车
注意:并不是只能用find_element_by_id('搜索框的id'),3、4小节举例的用法都可以使用
6,Selenium鼠标操作
需要导入模块:from selenium.webdriver import ActionChains
browser=webdriver.Chrome() #生成对象后使用
element=browser.find_element_by_xpath('')
ActionChains(browser).move_to_element(element).perform() #将鼠标移动到某个地方
browser.find_element_by_link_text('').click() #点击匹配的内容
7,切换页面
用于在页面之间互相切换,在Selenium里,一个页面叫做一个句柄,要切换页面,首先要获取到所有页面,也就是获取到所有句柄,获取到句柄后通过索引值切换,索引值从0开始,对应页面的顺序
all_handle=browser.window_handles #获取所有句柄
browser.switch_to.window(all_handle[索引值]) #切换句柄
8,子页面切换
有的时候一个页面下会嵌套子页面,如iframe,常见的如登录界面,如果有Selenium找某这个元素没有找到,大概率是当前页面下嵌有子页面,需要先跳转到子页面才可以抓。方法:
iframe=browser.find_element_by_id('') # by_id by_name by_xpah 都可以,只要标识到iframe
browser.switch_to.frame(iframe) # 跳转到子页面
到这里再来分析第三节的代码:
①第一步是导入selenium模块,导入webdriver方法;
②第二步创建一个chrome浏览器的对象;
③第三步打开百度网页;
④第四步是通过xpath找搜索框,讲一下方法,打开控制台,点击我标出的按钮,在把鼠标移动到搜索框上,系统会自动为你选中这一段内容的标签属性。把鼠标放到即选中的标签框上,点击右键,点击Copy,点击Copy Xpath,就可以得到Xpath的值。这里也可以通过browser.find_element_by_id('kw') 来匹配。browser.find_element_by_id('kw')将返回一个对象。


⑤第五步用第四步创建的对象,调用send_keys('')方法,相当于在搜索框输入值
⑥第六步 按照第四步的方法同样得出‘百度一下’这个按钮的xpath,同样返回一个对象
⑦第七步 调用click对象,相当于点击‘百度一下’
from selenium import webdriver
#打开浏览器
browser=webdriver.Chrome()
#输入URl
browser.get("http://www.baidu.com")
#找到搜索框
node=browser.find_element_by_xpath('//*[@id="kw"]')
#搜索周杰伦
node.send_keys("周杰伦")
#找到点击按钮
su=clink=browser.find_element_by_xpath('//*[@id="su"]')
#点击搜索
su.click()
#关闭浏览器
brower.quit()
六、猫眼电影爬取(鼠标点击案例)
打开猫眼top100,URL:https://maoyan.com/board/4
一共一百部,每页10部,我们用Selenium+ChromeDriver把100部电影爬下来
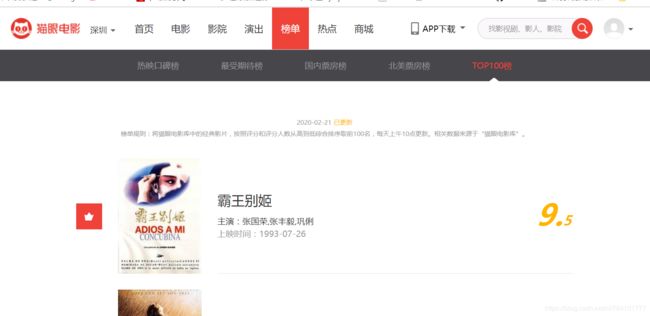
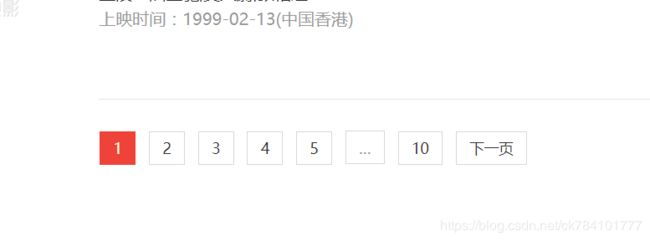

根据图片所示,第十页就没有下一页了,可以通过browser.find_element_by_link_text('下一页').click()方法来进入下一页,每进入到一页等待2秒,目的是使页面加载完全,2秒之后点击下一页,直到找不到下一页而抛异常退出。
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get("https://maoyan.com/board/4")
#死循环,退出条件为找不到下一页
while True:
#等待2秒再匹配内容
time.sleep(2)
#匹配文本内容
lists = browser.find_elements_by_xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
#输出文本内容
for i in lists:
print(i.text)
print('-' * 50)
try:
#进入下一页
next_page=browser.find_element_by_link_text('下一页').click()
except Exception as e:
browser.quit()
break
执行效果:


七、 京东商品爬取(键盘+鼠标案例)
京东首页:https://www.jd.com/
程序执行思路:
1.进入京东首页
2.搜索关键字
3.进入商品页面
4.抓当前页面的商品信息
5.点击下一页
6.重复4-5
7.到最后一页结束爬取


最后一页的下一页属性为:
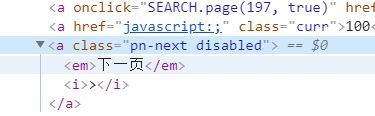
本程序执行速度较为缓慢,实际上Selenium和传统爬虫比速度本身就非常慢,你可以选择无界面模式让速度稍快一些。
import time
from selenium import webdriver
#生成浏览器对象
browser=webdriver.Chrome()
# 可以选择用无界面模式
# options=webdriver.ChromeOptions()
# options.add_argument("--headless")
#
# browser=webdriver.Chrome(options=options)
browser.get("https://www.jd.com/")
#找到搜索框
search=browser.find_element_by_xpath('//*[@id="key"]')
#搜索关键字
search.send_keys("斗罗大陆")
#点击搜索按钮
browser.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()
#死循环,结束循环的条件是找到最好一页
while True:
#将页面拖到最下面
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
#停留5秒,等待加载结束(可按照你的网速调整)
time.sleep(5)
#找到文本内容
lists=browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
items={}
for i in lists:
print(i.text)
# 你可以选择格式化输出
# products_lists=i.text.split('\n')
# items['price']=products_lists[0]
# items['name'] = products_lists[1]
# items['commit'] = products_lists[2]
# items['shopname'] = products_lists[3]
# print(items)
print('-'*50)
try:
# 已知最后一页的class属性中的内容为pn-next disabled,非最后一页为pn-next
# 如果匹配不到pn-next disabled,说明并非最后一页,点击下一页
# 程序有两种退出方式,要么匹配到最后一页,要么在中途因异常退出
if browser.page_source.find('pn-next disabled') == -1:
browser.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]').click()
else:
browser.quit()
break
except Exception as e:
browser.quit()
break
执行效果:

八、QQ邮箱登录(子页面跳转案例)
QQ邮箱URL:https://mail.qq.com/
QQ邮箱是一个典型的嵌入页面案例,如下图,登录框在iframe下,所以你直接匹配输入框是找不到内容的。


尝试写一个Selenium代码来实现自动登录,如下:
from selenium import webdriver
browser=webdriver.Chrome()
browser.get("https://mail.qq.com/")
#跳到子页面
iframe=browser.find_element_by_id('login_frame')
browser.switch_to.frame(iframe)
browser.find_element_by_id('u').send_keys('账号')
browser.find_element_by_id('p').send_keys('密码')
browser.find_element_by_id('login_button').click()
如果报错可能是打开了qq,把qq关掉重试