2W台服务器、每秒数亿请求,微信如何不“失控”?
微信作为当之无愧的国民级应用,系统复杂程度超乎想象:其后台由三千多个移动服务构成,每天需处理大约十的10~11次方个外部请求,整体需要每秒处理大约几亿个请求!那么微信究竟是如何保证系统稳定性并有序处理各类请求的?本文的作者从技术上深入解读了《用于扩展微信微服务的过载控制》一文,介绍了已在微信上运行了五年之久的过载控制系统DAGOR。

以下为译文:
最近我读了一篇论文《Overload control for scaling WeChat microservices(用于扩展微信微服务的过载控制)》,十分喜欢。
这篇论文主要分两部分:首先,我们能了解一些微信后台的内部消息;其次,作者分享了一种经过实践检验的过载控制系统DAGOR,该系统已经在微信上运行了五年。友情提示,这个系统在设计时就考虑了微服务架构的特殊情况,所以如果你想在自己的微服务上采用某种策略,那最好还是以这个系统为起点参考。
1.每秒需要处理几亿请求的微信后台
现在的微信后台由3000多个移动服务构成,包括实时消息、社交网络、移动支付和第三方认证等,平台每天能处理大约1010~1011外部请求。每个请求可能触发更多的内部请求,所以微信的后台作为一个整体,需要每秒处理大约几亿个请求。
“微信的微服务包含3000多个服务,运行在微信业务系统中的20000多台机器上,随着微信越来越流行,这个数字还在不断增加……由于微信一直在不断发展,它的微服务系统也在迅速更新。例如,从2018年3月到5月间,微信的微服务平均每天大约有1000个修改。”
微信将微服务分类为“入口层”服务(接收外部请求的前端服务)、“共享层”服务(中间层协调服务)和“基本服务”(不调用其他服务的服务,请求在这里终结)。
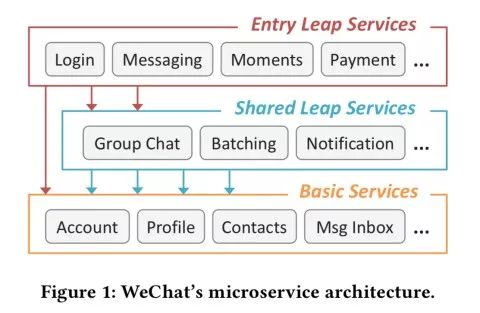
图注:微信的微服务架构
每天,峰值请求大约是日平均请求的三倍。在每一年的固定时期(例如在中国的新年前后),峰值负载可能达到日平均负载的10倍。
2.基于微服务的大型平台过载控制的难点
“过载控制……对于在任何不可预测的负载高峰下都要保证24x7服务大型在线应用来说极其重要。”
传统的过载控制机制主要用于只有少量服务组件的情况,通常包括一个较窄的“前门”,加上一些不重要的依赖。
“……现代的在线服务的架构和依赖变得越来越复杂,远远超过了传统过载控制的设计考虑。”
-
发送到微信后台的请求没有单一的入口点,而传统方式是在全局入口点(网关)上以中心化的负载监视为主,因此无法使用。
-
特定请求的服务调用图可能依赖于请求自身的数据和服务参数,甚至同一种请求的调用图都可能不同。所以,当特定服务出现过载时,很难确定应该拒绝哪一种请求来缓解压力。
-
过度的请求拒绝(特别是在调用图深处或者请求处理后期拒绝)会浪费大量计算资源,而且会由于高延迟而影响用户体验。
-
由于服务的调用图非常复杂,而且在不断变化,有效的跨服务协调的维护成本和系统额外开销非常高。
由于一个服务可能向它依赖的服务发出多个请求,还可能给多个后台服务发出请求,所以在处理过载控制时必须谨慎。作者采用了“序列过载”来描述多于一个过载服务被调用的情况,或一个过载服务被调用多次的情况。
“序列过载给有效的过载控制带来了挑战。直觉上,当服务过载时随机进行load shedding能将系统的吞吐量维持在饱和状态。但是,序列过载可能会导致吞吐量出现预期之外的下降……”
考虑一个简单的情况,服务A调用服务B两次。如果B拒绝掉一半的请求,那么A的成功率就会下降到0.25。
3.微信的过载控制系统DAGOR
微信的过载控制系统叫做DAGOR,它的目标是给所有服务提供过载控制,因此被设计成与服务无关。过载控制运行在单个服务器的粒度上,因为中心化的全局协调太昂贵了。但是,它能够与轻量级的服务器间合作协议配合使用,后者在处理序列过载的情况时是必须的。最后,DAGOR应当在load shedding不可避免时尽可能维持服务的成功率。消耗在失败的任务上的计算资源(如CPU、I/O等)应当保持最小。
我们要解决两个最基本的任务:检测过载状况,决定检测到过载后的对策。
过载检测
对于过载检测,DAGOR采用了等待队列请求平均等待时间(即排队时间)。排队时间可以有效地避免调用图中的延迟造成的影响(可以与其他指标比较一下,比如请求处理时间等)。即使过载没有发生,本地服务器上的服务处理时间也可能增加。DAGOR基于窗口进行监视,窗口大小为1秒或2000个请求,先到者为准。显然,微信做得不错:
“对于过载检测,考虑到微信中的每个服务任务的默认超时时间为500毫秒,我们将请求平均排队时间设置为20毫秒,以此作为服务器过载的标志。这种经验性的配置已经在微信的业务系统中使用了五年以上,其有效性已经被微信业务活动的健壮程度证明。”
任务控制
检测到过载后,我们要决定怎样处理过载。或者更直接地说,要确定拒绝哪些请求。首先我们注意到并非所有请求都是平等的:
“操作日志表明,微信支付和即时消息的服务失败时间是相似的,但微信支付上的用户投诉要比即时消息高出100倍。”
为了以服务无关的方式来处理,每个请求在进入系统时都要指定业务优先级,这个优先级会流向下游的所有请求。用户请求的业务优先级由被请求的操作类型决定。尽管有几百个入口点,但只有几十个入口点有明示的优先级,其他的均为默认优先级(较低的优先级)。优先级用一个有副本的哈希表来维护。
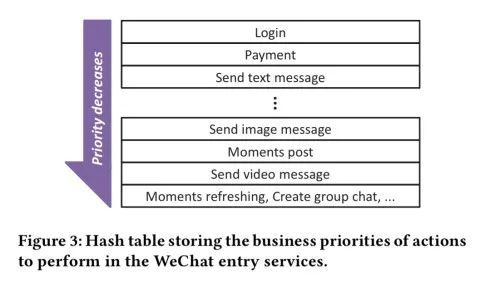
图注:哈希表存储了微信的各个入口服务进行操作的业务优先级
当过载控制被设置为业务优先级n时,所有n+1以上的请求都会被拒绝。对于混合型的负载,这种策略非常好用。但如果出现大量支付请求,所有请求的优先级都相同(均为p),那么系统就会过载,于是就会把过载阈值设置为p-1,从而使负载降低。一旦检测到负载降低,就会把过载阈值再设置为p,从而又导致过载。为了避免这种由大量优先级相同的请求导致的反复情况,我们需要比业务优先级更细粒度的控制。
微信的解决方案很巧妙,它根据用户ID增加了另一层控制。
“用户优先级是由整个服务根据一个哈希函数动态生成的,该哈希函数接收用户ID作为参数。每个入口服务都会在每个小时改变其哈希函数。这样做的结果就是,来自同一个用户的请求在一小时之内会被指定为同样的优先级,但不同的小时会产生不同的用户优先级。”
这样能保证公平,同时为每个用户在相对长的一段时间内提供一致的用户体验。这样做还能帮助控制序列过载问题,因为来自同一个用户优先级更高的请求高更容易在整个调用图中畅通无阻。
将业务优先级和用户优先级结合使用,能够在每个业务优先级内提供128级的用户优先级。
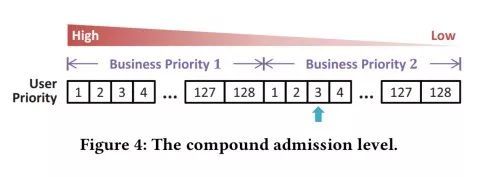
图注:组合优先级
“每个业务优先级的每个层次都有128个用户优先级,这样得到的组合优先级就有几万个。组合优先级的调整是在用户粒度上进行的。”
为什么一定要使用用户ID而不能使用会话ID呢?因为后者会让用户养成在服务差的时候重新登录的习惯,进而会导致在原来的过载问题上出现大量的登录!
DAGOR在每个服务器上维持一个直方图,来跟踪各个优先级的请求的大致分布情况。当在某个窗口内检测到过载时,DAGOR移动到第一个桶,将预期的负载减小5%。如果没有负载,就会到第一个桶内,将预期负载增加1%。
服务器还会顺便将每个响应消息的当前优先级发送到上游服务器。这样,上游服务器就能知道当前下游服务的控制设置,从而甚至可以在发送请求之前进行本地控制。
因此,DAGOR过载控制系统的端到端架构如下所示:
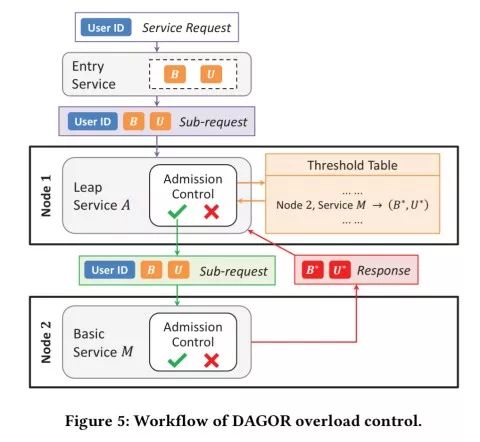
图注:DAGOR过载控制系统的工作流
实验
DAGOR设计的最佳实证就是它已经在微信的产品环境里运行了五年之久。但对于学术论文来说这还不够,因此作者还提供了一系列模拟实验。下面的几张图显示了基于排队时间的过载控制要比基于响应时间的好得多。优势主要出现在系列过载的情况下(图(b))。
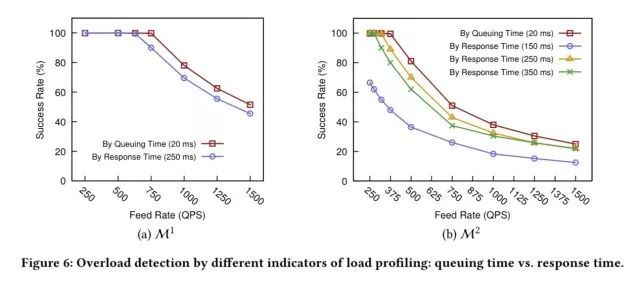
图注:利用不同的负载评测指标进行过载检测:排队时间 vs. 响应时间
与CoDel、SEDA相比,在系列过载的情况下,发送一个系列调用时DAGOR的请求成功率要高出50%。系列请求的数目越高,优势就越大。

图注:不同类型负载下的过载控制
最后为公平起见,可以看出CoDel更适合扇出较小的服务,而DAGOR能在多种不同请求的情况下达到同样的成功率。
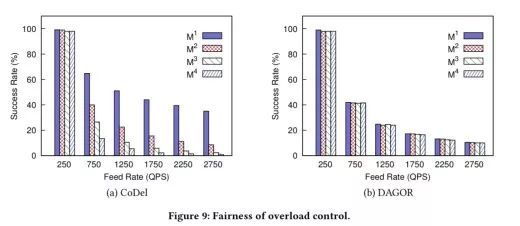
图注:过载控制的公平比较
4.给开发者的三条建议
即使你不会完全按照该论文描述的方式使用DAGOR,作者也给你提了三条非常有价值的建议:
-
大规模微服务架构下的过载控制必须是去中心化,每个服务必须是自动化;
-
过载控制应该考虑各种反馈机制(例如DAGOR的协同控制),不要依赖于单一的开环启发;
-
过载控制设计应当根据实际负载的处理行为进行。
原文:https://blog.acolyer.org/2018/11/16/overload-control-for-scaling-wechat-microservices/
译者:弯月,责编:郭芮
“征稿啦”CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。