论文阅读:SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
苏菲:一个专注于预测符合社会和物理约束的路径的GAN
论文链接:https://arxiv.org/pdf/1806.01482.pdf
摘要:本文讨论了场景中多个交互代理的路径预测问题,这是许多自动驾驶平台(如自动驾驶汽车和社交机器人)的关键步骤。我们介绍SoPhie;基于生成对抗网络(GAN)的可解释框架,其利用场景的图像来利用两个信息源,场景中所有代理的路径历史以及场景上下文信息。要预测代理的未来路径,必须利用物理和社交信息。以前的工作并没有成功地共同模拟物理和社会互动。我们的方法将社交关注机制与物理关注相结合,帮助模型学习在大型场景中查看的位置,并提取与路径相关的图像的最显着部分。然而,社交关注组件在不同的代理交互中聚合信息,并从周围的邻居中提取最重要的轨迹信息。 SoPhie还利用GAN生成更逼真的样本,并通过对其分布进行建模来捕捉未来路径的不确定性。所有这些机制使我们的方法能够预测代理人的社会和物理合理路径,并在几个不同的轨迹预测基准上实现最先进的性能。
总结本文的主要贡献如下:
1.我们的模型使用场景上下文信息与代理之间的社交交互,以预测每个代理的未来路径。
我们提出了一种更可靠的特征提取策略来编码代理之间的交互。
3.我们结合基于LSTM的GAN引入两种注意机制,以生成更准确和可解释的社会和物理可行路径。
4.多个轨迹预测基准的最新结果。
好了,官方翻译完毕,接下来上自己的理解:
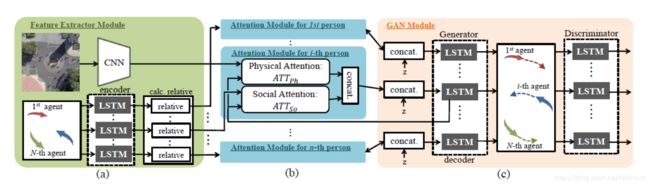
1.1先上流程图:
1.2问题定义
t时刻的图像:![]()
N个代理的过去到现在的状态:![]()
1-N个代理的状态集合+除去第i个代理的状态集合:![]()
未来![]() 时刻的轨迹标签:
时刻的轨迹标签:![]()
所以对第i个代理未来t+1到t+T(T>1)时刻的真实轨迹和预测轨迹:![]()
![]() 其中
其中
我们的目标:学习参数W*去预测轨迹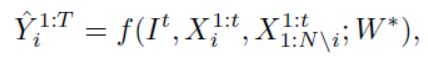
minimizing a loss LGAN between the predicted and ground truth future states for all agents.
1.3模型总览
1- A feature extractor module (![]() :CNN,
:CNN,![]() :LSTM(encoder)
:LSTM(encoder)
2- An attention module(social and physical attention mechanisms:highlights the most important information)
3- An LSTM based GAN module(the LSTM based GAN module :generate a sequence of realistic future paths for each agent)
2模型细节
2.1 特征提取
2.1.1图像特征提取:![]() CNN是用VGG19,权重先预训练Wcnn is initialized by pre-training on ImageNet,然后在场景分割的任务上微调。
CNN是用VGG19,权重先预训练Wcnn is initialized by pre-training on ImageNet,然后在场景分割的任务上微调。
2.1.2第i个代理的历史轨迹信息特征提取:![]() where ht
where ht
en(i) represents the hidden state of the encoder LSTM at time t for the agent i.
2.1.3其他代理对第i个代理未来路径影响的联合特征表示:但是,不能简单地按照代理的顺序将它们连接起来来创建这个联合特性。为了保持它的置换不变性(使用了permutation invariant (symmetric) function)social gan里面是用一个max函数做的,这样的话呢,所有的代理都使用相同的特征,而且丢失了各自的独特性信息。为了解决这个问题,将其他代理按照距离i的欧几里得距离sort之后,有序的相减,然后再concat,![]() where 派j is the index of the other agents sorted according to their distances to the target agent i.
where 派j is the index of the other agents sorted according to their distances to the target agent i.
当然呢,这里在向量编码的时候,要规定代理人的总数(即向量的长度)N = Nmax,然后用a dummy value as features if the corresponding agent does not exist in the current frame.
2.2 Attention Modules
2.2.1we want the model to focus more on the salient regions of the scene and the more relevant agents in order to predict the future state of each agent.为了让模型专注于更突出的场景和更相关的代理人,加入了attention module
2.2.2Physical Attention:
模型定义:![]()
inputs:the hidden states of the decoder LSTM in the GAN module, and the visual features extracted from the
image V t Ph ;;Note that, the hidden state of the decoder LSTM has the information for predicting the agent’s future path.
作者认为:解码器LSTM中的hidden state 有预测该代理未来路径的信息,即行人更注意哪一些场景区域,于是把它也作为输入
output:a context vector ![]() h t dec(i) represents the hidden state of the decoder
h t dec(i) represents the hidden state of the decoder
LSTM at time t for the agent i.
Social Attention:与Physical Attention类似
a social context highlights which other agents are most important to focus on when predicting the trajectory of the agent i.
这个向量强调了应该关注哪些其他的重要代理,对于预测代理i的未来轨迹
![]()
We use soft attention similar to [25]Neural image caption generation with visual attention.(ICML 2015)
2.3基于LSTM的GAN
INPUT:![]() and
and![]() ,即上一节中得到的两个the social and physical context vectors for each agent i,
,即上一节中得到的两个the social and physical context vectors for each agent i,
OUTPUT:candidate future states which are compliant to social and physical constraints.(服从社交和物理约束的候选未来状态)
目前存在的方法呢,大多使用L2损失,但有一个缺点就是只预测了一条未来轨迹,即大概是凭直觉的所有可行路径的average,使用GAN模型呢,学习到的就是一种分布了。
模型:a decoder LSTM as the generator and a classifier LSTM as the discriminator
Generator (G):Similar to the conditional GAN [18], the input to our generator is a white noise vector z sampled from
a multivariate normal distribution while the physical and social context vectors are its conditions.类似于条件gan,加入白噪声z(从多元正态分布采样),![]() and
and![]() 是它的条件。
是它的条件。
simply concatenate![]()
则产生的第i个代理,第 个时间的未来状态:
个时间的未来状态:![]()
Discriminator (D):LSTMdis(.)its input is a randomly chosen trajectory sample from the either ground truth or
predicted future paths,对第i个代理,第个时间,随机地选择采样的生成轨迹和真实的轨迹,即![]() 则判别器得到的output:
则判别器得到的output: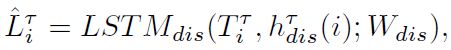 是一个预测的lable of是否是real(=1) or fake(=0)
是一个预测的lable of是否是real(=1) or fake(=0)
Losses:To train SoPhie, we use the following losses:
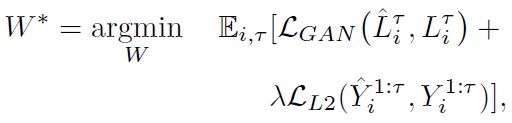 其中
其中 是一个正则化项between two losses.
是一个正则化项between two losses.
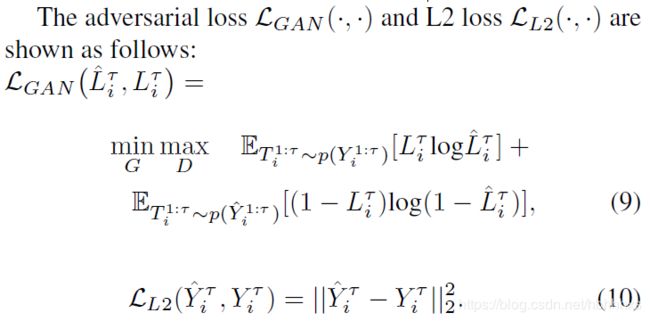
3数据集和训练
These datasets include nontrivial movements including pedestrian collisions, collision avoidance behavior, and group movement. Both of the datasets consists of a total of five unique scenes, Zara1, Zara2, and Univ (from UCY), and ETH and Hotel (from ETH).
One image is used per scene as the cameras remain static.
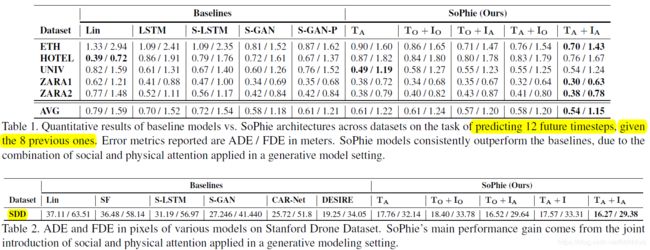
SDD主要就是包含比较多的物理地标,比如 建筑物和交叉环绕路口,能体现本文的贡献点。

模型训练细节:
迭代训练GAN:使用Adam optimizer
batch size:64 learning rate:0.001 for both the generator and the discriminator
Models were trained for 200 epochs.
The encoder encodes trajectories using a single layer MLP with an embedding dimension of 16.
In the generator this is fed into a LSTM with a hidden dimension of 32;
in the discriminator, the same occurs but with a dimension of 64.
The decoder of the generator uses a single layer MLP with an embedding dimension of 16 to encoder
agent positions and uses a LSTM with a hidden dimension of 32.
In the social attention module, attention weights are retrieved by passing the encoder output and decoder context
through multiple MLP layers of sizes 64, 128, 64, and 1,
with ReLu activations
The final layer is passed through a Softmax layer. The interactions of the surrounding Nmax = 32 agents are considered
If there are less than Nmax agents, the dummy value of 0 is used.
The physical attention module takes raw VGG features (512 channels),
we have observed eight timesteps of an agent and are attempting to predict the next T = 12 timesteps.
We weight our loss function by setting = 1.
不贴了不贴了,细节看论文去吧。