使用scrapy爬取京东产品详细信息
我的爬虫以京东女装的外套为例进行,抓取更大的分类可以再进行修改。
scrapy的安装,建工程什么的我就不说了,工程结构如图
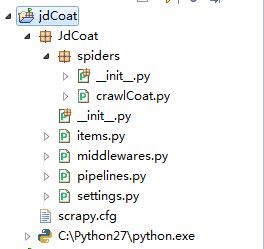
crawlCoat内容如下:
# -*- coding: utf-8 -*-
from JdCoat.items import JdcoatItem
from scrapy.http import Request
from scrapy.selector import Selector
from scrapy.contrib.linkextractors.lxmlhtml import LxmlLinkExtractor
from scrapy.contrib.spiders import Rule, CrawlSpider
class JdCrawl(CrawlSpider):
name = "crawlcoat"
allowed_domins = ["jd.com"]
start_urls = [
"http://list.jd.com/list.html?cat=1315,1343,9712",#外套
# "http://list.jd.com/list.html?cat=1315,1343,9717"#长裤
]
#这里主要是抽取产品的url和下一页的url,并分别调用各自的回调函数,默认调用parse,也就是直接请求网页不做相关处理
#还有一个方法是,不写rule,直接重写parse方法,方法里分别获取产品url和下一页url,也很好用
rules = [
Rule(LxmlLinkExtractor(allow="/\d{10}.html"), callback="parseItemurl",),
Rule(LxmlLinkExtractor(allow=("/list.html\?cat=1315%2C1343%2C9712&page=\d+&JL=6_0_0"), restrict_xpaths=("//a[@class='next']")),
follow=True)
] def parseItemurl(self,response):
itemurl = response.xpath("//div[@id='choose-color']/div[2]/div")
i = 1
for url in itemurl.xpath("a/@href").extract():
item = JdcoatItem()
item['color'] = response.xpath("//div[@id='choose-color']/div[2]/div["+str(i)+"]/a/@title").extract()
i = i + 1
r = Request(url,callback=self.parseDetail)
r.meta['item'] = item
yield r
def parseDetail(self, response):
mainurl = response.url
productid = mainurl[19:29]
#京东价格是js生成的,我只会这样获取产品价格
# 模拟js访问此网站,获取商品价格,返回的是str
priceUrl = 'http://p.3.cn/prices/mgets?skuIds=J_' + productid + 'J_'
r = Request(priceUrl,callback=self.parsePrice) #请求 价格地址
sel = Selector(response)
#item = JdcoatItem() item = response.meta['item']
product_detail = sel.xpath("//ul[@class='detail-list']/li")
i = 0
#获取其他信息
elseInfo = ''
for info in product_detail.xpath("text()").extract():
infoList = info.encode('utf-8').split(":")
#获取店铺标签所在的位置
i = i + 1
key = infoList[0]
value = infoList[1]
if(key == "商品编号"):
item['productID'] = value
elif(key == "上架时间"):
item['time'] = value
elif(key == "店铺"):
item['shop'] = sel.xpath("//ul[@class='detail-list']/li["+str(i)+"]/a/text()").extract()
item['shop_url'] = sel.xpath("//ul[@class='detail-list']/li["+str(i)+"]/a/@href").extract()
elif(key == "商品毛重"):
item['weight'] = value
elif(key == "商品产地"):
item['addr'] = value
elif(key == "尺码"):
item['size'] = value
elif(key == "材质"):
item['material'] = value
elif(key == "颜色"):
item['color'] = value
elif(key == "流行元素"):
item['popEle'] = value
elif(key == "上市时间"):
item['marketTime'] = value
elif(key == "袖型"):
item['sleeves_type'] = value
elif(key == "风格"):
item['style'] = value
elif(key == "版型"):
item['version_type'] = value
elif(key == "厚度"):
item['thickness'] = value
elif(key == "衣长"):
item['length'] = value
elif(key == "衣门襟"):
item['yimenjin'] = value
elif(key == "领型"):
item['collar'] = value
elif(key == "图案"):
item['pattern'] = value
else:
if((key != "商品名称")):
elseInfo = elseInfo+info.encode('utf-8')+'~'
item['elseInfo'] = elseInfo
item['title'] = sel.xpath("//div[@id='name']/h1/text()").extract()
item['category'] = sel.xpath("//div[@class='breadcrumb']/span[1]/a[2]/text()").extract()
item['url'] = mainurl
item['image_urls'] = sel.xpath("//div[@id='preview']/div/img/@src").extract()
item['images'] = sel.xpath("//div[@id='product-intro']/div[3]/div[1]/img/@src").extract()
r.meta['item'] = item
return r
def parsePrice(self,response):
sel = Selector(text=response.body)
try:
price = sel.xpath("//text()").extract()[0].encode('utf-8').split('"')[7]
except Exception,ex:
print ex;
price = 0
#获取parseDetail方法传过来的其他item信息,在此处return item
item = response.meta['item']
item['price'] = price
return item
爬虫的文件就是这样了,item里对属性的定义就不用写了。middrewares文件是使用http代理的,如果你是使用http代理上网,则必须有此文件,我之前没有加,抓取特别慢。
文件内容如下:
class ProxyMiddleware(object):
# overwrite process request
def process_request(self, request, spider):
# Set the location of the proxy
request.meta['proxy'] = "http://***************:port"
# 如果有密码,加上下面这些
proxy_user_pass = "USERNAME:PASSWORD"
# setup basic authentication for the proxy
import base64
encoded_user_pass = base64.encodestring(proxy_user_pass)
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass再来看看pipelines文件的内容:
class JdcrawlPipeline(object):
def process_item(self, item, spider):
return item
##################下面这些不要也行,要的话就把上面的注释掉吧,下面这些主要是修改相关图片信息时需要的#####################
# import scrapy
# from scrapy.contrib.pipeline.images import ImagesPipeline
# from scrapy.exceptions import DropItem
#
# class MyImagesPipeline(ImagesPipeline):
#
# def get_media_requests(self, item, info):
# for image_url in item['image_urls']:
# yield scrapy.Request(image_url)
#
# def item_completed(self, results, item, info):
# image_paths = [x['path'] for ok, x in results if ok]
# if not image_paths:
# raise DropItem("Item contains no images")
# item['image_paths'] = image_paths
# return item
################################################################下面是setting文件的内容:
# -*- coding: utf-8 -*-
# Scrapy settings for JdCrawl project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
#
BOT_NAME = 'JdCoat'
SPIDER_MODULES = ['JdCoat.spiders']
NEWSPIDER_MODULE = 'JdCoat.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'JdCrawl (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36'
#爬取图片的话必须加上下面这些,如果pipelines文件里的MyImagesPipeline没有的话,就把下面的注释掉的再注释回来,
#再注释掉MyImagesPipeline那一行就可以了,就是必须开启图片管道
ITEM_PIPELINES = {
#'scrapy.contrib.pipeline.images.ImagesPipeline': 1
'JdCoat.pipelines.MyImagesPipeline',}
IMAGES_STORE = './jdimage_5/'
#宽度优先策略
#SCHEDULER_ORDER = 'BFO'
#http 代理,如果没有代理这就不要了
DOWNLOADER_MIDDLEWARES = {
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,
'JdCoat.middlewares.ProxyMiddleware': 100,
}基本内容就这些了,接下来直接到工程目录下运行scrapy crawl ***就行了(如果想将爬取结果存到csv,json里,就在这句后面加上-o **.csv(json))。
关于存mysql数据库,也很容易,网上也有。写的不好,还请大家多多指教。