python svm pca实践(一)
好久没写博客了
这里主要用python的sklearn包,来进行简单的svm的分类和pca的降维
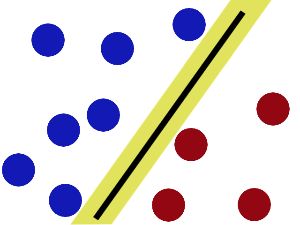
svm是常用的分类器,其核心是在分类的时候找到一个最优的超平面,使得所有的样本与超平面之间的距离达到最小。
pca是常用的一种降维的方法,其核心是对去中心化后的数据,求得协方差矩阵,再对协方差矩阵进行特征分解,将最大的几个特征值作为这个样本的的新特征,达到降低数据特征维度的效果
这里用sklearn的digits数据集作为演示数据集
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# ***use seaborn plotting style defaults
import seaborn as sns; sns.set()
from sklearn import decomposition
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
#********************* KEY IMPORT OF THIS LECTURE********************************
from sklearn import svm
# loading handwritten digits
dig_data = load_digits()
X = dig_data.data
# y: the values of the digits, or "ground truth"
y = dig_data.target
dig_img = dig_data.images
print(type(X), X.dtype, X.shape)
print(type(dig_img), dig_img.dtype, dig_img.shape)
print(type(y), y.dtype, y.shape)先导入所需要的包,并下载所需要的数据集
这里主要用到digits数据集中的.data,.target,.images属性
.data 为数据集的图像数据,用有1797个数据以一维的形式呈现,每个数据集的长度为64
.target为数据集的标签数据
.image位数据以8x8的形式呈现
dig_data = load_digits()
X = dig_data.data
y = dig_data.target
# This is basically each array in X
# getting reshaped into (8, 8).
dig_img = dig_data.images
print(type(X), X.dtype, X.shape)
print(type(y), y.dtype, y.shape)
select_idx = 2
# select_idx = 5
# ********************************Separating training data from testing data****************
Xtrain = np.delete(X, select_idx, axis = 0)
ytrain = np.delete(y, select_idx)
# if you don't do .reshape(1, -1), you get a warning.
# B/c the data argument for classifier has to be an array,
# even if it's a one-element array.
Xtest = X[select_idx].reshape(1, -1)
test_img = dig_img[select_idx]
ytest = y[select_idx]
print('Xtrain.shape, ytrain.shape', Xtrain.shape, ytrain.shape)
print('Xtest.shape, ytest.shape', Xtest.shape, ytest.shape)
plt.figure(figsize = (4, 4))
plt.imshow(test_img, cmap = 'binary')
plt.grid('off')
plt.axis('off')
# ************************************* The PCA Section ********************************
n_comp = 10
pca = PCA(n_comp)
# finding pca axes
pca.fit(Xtrain)
# projecting training data onto pca axes
Xtrain_proj = pca.transform(Xtrain)
# projecting test data onto pca axes
Xtest_proj = pca.transform(Xtest)
print(Xtrain_proj.shape)
print(Xtest_proj.shape)
# ************************************* The SVM Section ********************************
# instantiating an SVM classifier
clf = svm.SVC(gamma=0.001, C=100.)
# apply SVM to training data and draw boundaries.
clf.fit(Xtrain_proj, ytrain)
# Use SVM-determined boundaries to make
# a prediction for the test data point.
clf.predict(Xtest_proj)将数据集分成训练集和测试集,将索引为2的数据从整个数据集中剔除作为测试数据集,剩下的数据作为训练数据集,
n_comp为PCA降维后取得维数,
用训练集来训练PCA,再用训练集的模型来对训练集和测试集进行降维,
接着用训练集来训练SVM,并对测试集进行预测
def classify_dig_svm(X, y, dig_img, select_idx, n_comp, plot_test_img = False):
dig_data = load_digits()
X = dig_data.data
y = dig_data.target
dig_img = dig_data.images
Xtrain = np.delete(X, select_idx, axis = 0)
ytrain = np.delete(y, select_idx)
Xtest = X[select_idx].reshape(1, -1)
test_img = dig_img[select_idx]
ytest = y[select_idx]
if plot_test_img == True:
plt.figure(figsize = (4, 4))
plt.imshow(test_img, cmap = 'binary')
plt.grid('off')
plt.axis('off')
n_comp = 10
pca = PCA(n_comp)
pca.fit(Xtrain)
Xtrain_proj = pca.transform(Xtrain)
# projecting test data onto pca axes
Xtest_proj = pca.transform(Xtest)
# print(Xtrain_proj.shape)
# print(Xtest_proj.shape)
# ************************************* The SVM Section ********************************
# instantiating an SVM classifier
clf = svm.SVC(gamma=0.001, C=100.)
# apply SVM to training data and draw boundaries.
clf.fit(Xtrain_proj, ytrain)
clf.predict(Xtest_proj)
return clf.predict(Xtest_proj)
X = dig_data.data
y = dig_data.target
n_comp = 30
# select_idx =
# classify_dig_svm(X, y, dig_img, select_idx, n_comp, plot_test_img = False)
counter = 0
tot = 1797
for i in range(tot):
if classify_dig_svm(X, y, dig_img, i, n_comp, plot_test_img = False) == y[i]:
counter += 1
rate = counter/tot
print(rate)classify_dig_svm的方法是对每个数据进行测试看一下训练出来的pca模型和svm模型的准确性
其实效果还好
