如何有效的使用闭包
【译】如何有效地使用闭包
译者:Jason(https://l-movingon.github.io/posts/2016-05-06-use-javascript-closures-efficiently.html)
原文:http://www.ibm.com/developerworks/library/wa-use-javascript-closures-efficiently/
翻译能力有限,原文请点这里 Use JavaScript Closures Efficiently,越到后面,内容才越重要,如果想看,请耐心看完(我也是翻译之后才知道的)
闭包普遍地用在 Node.js 中,以支持各种形式的异步和事件驱动这两种编程模式。如果你对闭包有一个很好的理解,就可以保证你所开发的应用不仅有正确的功能,还有良好的稳定性和可扩展性。
闭包一般用于把数据和作用于数据的代码联合起来。当你使用闭包的时候,你在外部作用域定义的数据元素可以被该作用域里定义的函数访问,即使当这个外部作用域在逻辑上已经退出了(外部函数已经被返回了)。在一些语言例如 JavaScript 中,函数是 first-class 变量( first-class 并不代表函数和其他变量不一样,相反地,它代表了函数和其他变量没有什么不一样。你可以把函数赋给一个变量,可以把函数当成参数,也可以当成返回值),这个特性非常重要,因为这样函数的生命周期就取决于在函数里可见的数据元素的生命周期。在这个环境下,你很容易在不经意间就把数据保留在了内存中,这是非常危险的。
这个教程包含了三个主要的闭包在 Node 中的使用用例
-
Completion handler
-
Intermediary function
-
Listener function
每个用例我们都会提供简单的代码和分别表明闭包预期的寿命和这段寿命时间里内存的情况。这些信息有助于你设计JavaScript 应用时了解这些用例是怎么影响内存使用的,这样你就可以在应用中防止内存泄漏了。
这里有三篇关于 JavaScript 中内存泄漏的文章
-
Understand memory leaks in JavaScript applications
-
Memory leak patterns in JavaScript
-
Core dump debugging for the IBM SDK for Node.js
(
链接分别为:
-
http://www.ibm.com/developerworks/library/wa-jsmemory/
-
http://www.ibm.com/developerworks/library/wa-memleak/
-
http://www.ibm.com/developerworks/library/wa-ibm-node-enterprise-dump-debug-sdk-nodejs-trs/index.html
)
Closures and Asynchronous Programming
如果你习惯于顺序编程的风格,那么当你尝试去了解异步编程的时候,可能会问下面的一些问题
-
如果一个函数被异步调用,你怎么保证这个函数在调用之后,接下来的代码可以与在这个作用域里的数据一起工作?或者换句话说,你写的代码要怎么才能依赖于异步函数调用之后产生的结果或者副作用?
-
在异步函数调用之后,程序继续往下执行与异步调用无关的代码,你是怎么在异步调用执行完之后,返回到之前的调用域中继续执行代码的?
闭包和回调就是这些问题的答案,在最常见和最简单的例子中,每个异步方法都有一个回调函数作为其中的参数。这个函数一般定义在异步函数的里面,并且它可以访问到这个外部作用域的数据元素,例如局部变量和参数。
举一个例子,看看下面这段代码
|
var
b = 20;
function
inner (c) {
var
d = 40;
return
a * b / (d - c);
}
return
inner;
}
var
x = outer(10);
var
y = x(30);
|
我们在 inner() 这个函数的 return 语句中断个点

这个图是 inner 这个函数在第 17 行被调用,然后执行到第 11 行的时候。在 16 行的时候,outer 函数被执行,返回了inner 函数。从图中可以看到,当 inner 函数执行时,可以访问到自己的局部变量 c 和 d 的同时,还可以访问到outer 函数中定义的变量 a 和 b,即使 outer 的作用域已经在 16 行执行完后返回退出了。
想要防止内存泄漏,关键在于弄明白回调函数什么时候可以访问和可以访问多久
回调函数存在于一个可以被调用的状态(也可以说,垃圾回收不可以接触到的一个状态),所以它可以使所有它访问到的数据元素都不被回收。想要防止内存漏泄,关键在于弄明白回调函数什么时候会在这个状态,和存在这个状态多久。
闭包常常用在至少三种类别的场景中。但这三种的使用前提都是一样的: 和一小部分重用代码一起工作的能力,还有选择性保留上下文的能力。
Use Case 1: Completion Handler
在 completion handler 这种模式中,一个函数 (C1) 作为一个参数传进去方法 (M1),当 M1 执行完之后,C1 就会当作 completion handler 来执行。在 M1 的实现中应确保当 C1 不再需要引用 M1 中的数据元素的时候,要及时清除掉。C1 常常会用到 1 到多个在 M1 作用域里的数据元素。每当 C1 创建的时候,就会有一个闭包产生,这个闭包就可以使得 C1 访问 M1 作用域。一个常用的方法就是在 M1 调用的时候,创建一个匿名函数 C1 传进去。这样通过闭包 C1 就可以访问到所有 M1 中的局部变量和参数
一个例子就是 setTimeout() 方法,当时间到了,completion 函数执行完的时候,在 timer 里 C1 需要用到的引用就会被清除
function
CustomObject () {}
function
run () {
var
data =
new
CustomObject();
setTimeout(
function
() {
data.i = 10;
}, 100);
}
run();
|
在 setTimeout 这个方法调用的时候,completion 函数用到了 data 这个变量。即使 run() 这个方法已经执行完了,但是 CustomObject 依然可以通过为 completion handler 所创建的闭包来访问,而不是被垃圾回收掉
Memory retention
闭包的上下文在 completion 函数 (C1) 定义的时候创建,闭包的上下文由 C1 被创建的作用域中的变量和参数组成。这个闭包会一直被保留直到.
-
completion 函数执行完了或者 timer 被清除了(通过
clearTimeout) -
没有其他 C1 需要用到的引用
通过使用 Chrome 的开发者工具可以看到,completion 函数存放在 _onTimeout 这个字段里,对 Timeout 对象有一个引用.
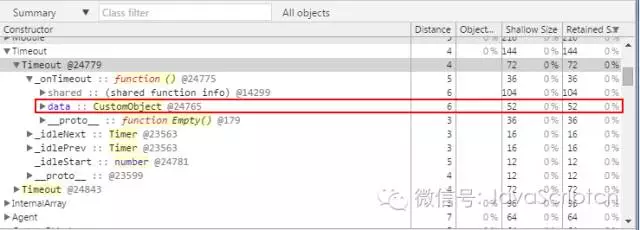
当计时器还有效的时候,Timeout 这个对象,_onTimeout(completion 函数),还有闭包都呆在堆里,等待这个timeout 的事件。当计时器触发和回调结束之后,在 Event Loop 里的等待事件就会被移除。所有的这三个对象都不可以再访问,并进入到下一次的垃圾回收队列中.
当计时器被清除(通过 clearTimeout 方法),completion 函数会从 _onTimeout 中除去,但前题是 completion 函数里的变量或参数没有被其他函数引用。那么它就会进到入下一次的垃圾回收队列中,但 Timeout 对象还会保留起来是因为主程序还保留着对他的引用.
这个截图是对比计时器触发前后的内存快照.

#New 这一栏显示的是在两个快照时间内新增的对象数,#Delete 这一栏则是显示被回收之后的对象数。用红框框住的地方表明 CustomObject 在第一个快照中存在但是在第二个快照中已经被回收和不再可以访问了。释放了 12 字节的内存空间.
在这个模式下(completion haneler),内存会一直保留直到 completion handler (C1) 执行完了,完成了 M1 方法整个过程之后,才会被释放。如果你的应用可以及时的执行完这个 completion handler (C1),那么你就不需要太担心内存泄漏的问题了.
Use Case 2: Intermediary Function
在一些情况下,你需要重复地,迭代地去处理那些异步或者非异步所创建的数据。对于这些情况,你可以返回一个 intermediary 函数,当你需要访问你所需要的数据或者完成所需要的计算的时候,可以一次或多次地调用它。和 completion handlers 一样,当你定义函数的时候就创建了一个闭包,这个闭包就可以让该函数访问到在函数定义的那个作用域里的所有变量和参数.
这种模式的一个例子就是数据流,当服务端返回一大段数据流的时候,客户端就会有一个回调函数去接收,每当有一小段数据流到达的时候,就会执行这个回调函数处理这一段数据。因为数据流是异步的,所以操作(如把数据积累起来)必须是重复迭代的。下面这段程序说明的就是这种情况.
function
readData () {
var
buf =
new
Buffer(1024 * 1024 * 100);
var
index = 0;
buf.fill(
'g'
);
return
function
() {
index++
if
(index < buf.length) {
return
buf[index - 1];
}
else
{
return
''
;
}
}
}
var
data = readData();
var
next = data();
while
(next !==
''
) {
// process data();
next = data();
}
|
在这种情况下,只要 data 变量一直在作用域里,buf 就会一直保留起来。buf 的大小会占用很大的内存空间,虽然这可能会被开发者所忽略,但是我们仍然可以从 chrome 开发者工具中看到,我们可以看一下下面这个截图,是在 while循环之后截取的。大量的缓冲被保留了下来,即使我们都不再使用它了.
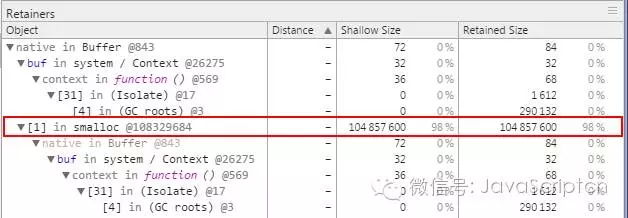
Memory retention
即使当应用使用完了 intermediary 函数(也就是刚刚的 data),但对这个函数的引用会使得关联的闭包还存在。为了能让里面的数据被回收,应用则需要重新修改这个函数的引用,例如像下面这样修改.
data =
null
;
|
这一行代码就可以使得闭包可以被垃圾回收了。下面这个截图是当 data 被置为 null 之后的,可以看到垃圾回收机制已经回收了我们的手动置为空的数据

被红框框住的地方就是缓冲流被回收并释放了内存.
我们经常通过设计构造 intermediary 函数来限制一些潜在的内存漏泄。举个例子,一个从大数据集里不断读取数据的 intermediary 函数可能会去除部分返回数据的引用。但对于这种情况,要记住的是这种方法对应用的其他部分并不友好,因为其他部分可能通过其他方式而非通过 intermediary 函数来访问这些数据。
当我们创建 intermediary function 这种模式的 APIs 的时候,一定要在文档上写明白这种内存残留的特性,这样使用者就了解到把所有引用都置为空的必要性。或者更好的是如果你在编写 API 的时候就可以知道当哪些数据是不再需要的时候,就可以在 intermediary 函数里直接置空,例如如果是刚刚那个例子,你就可以像下面那样重写 intermediary 函数.
return
function
() {
index++;
if
(index < buf.length) {
return
buf[index - 1];
}
else
{
buf =
null
;
// here
return
''
;
}
}
|
这样就可以保证当缓冲流不再需要的时候,会被回收.
User Case 3: Listener Functions
一个很常见的模式就是去注册(绑定)一个函数到某一个特定的事件上去。虽然这在异步编程中非常方便,但是这种注册(绑定)会导致监听函数和事件关联起来,并把所有相关闭包里的东西都保留起来。这在生成和处理事件的过程中,都是好的(因为我们可以使用外部的数据),而且事件拦截器模块也会知道什么时候阻止事件的触发和把监听函数都清除掉。但当监听函数的生命周期不确定或者不被应用所知的时候,风险就会出现。所以监听函数最容易引起内存泄漏的风险.
监听函数最容易引起内存泄漏的风险
大多数使用流和缓冲的场景都使用这种机制来缓存或者积累在外部方法定义的瞬时数据,直到存取在闭包里完成,来看看这个例子.
var
EventEmitter = require(
'events'
).EventEmitter;
var
ev =
new
EventEmitter();
function
run () {
var
buf =
new
Buffer(1024 * 1024 * 100);
var
index = 0;
buf.fill(
'g'
);
ev.on(
'readNext'
,
function
nextReader () {
var
byte = buf[index];
index++;
process(byte);
});
}
|
Memory retention
下面这个截图是截在调用了 run() 函数之后的,可以看到 buf 这个大的缓冲所占用的内存空间。我们还可以从支配树中看到,这个缓冲会一直保留着因为它被下面的事件所关联起来了.

数据会被回调函数(监听函数)一直保留起来,即使当所有的数据都已经处理过,更不用说外部函数(上面例子的 run())早就已经返回了。因为监听函数(上面例子的 nextReader()) 要访问缓冲,所以定义监听函数时创建的闭包就会一直保持,只有当监听函数与事件脱离并且不会再被引用的时候,才会被清理掉.
// 一旦 `readNext` 事件的目标完成后
// 就要把监听函数从事件中脱离
ev.removeListener(
'readNext'
, nextReader);
|
当你使用监听函数,而它的生命周期符合下面两点的时候,就会有内存泄漏风险.
-
不在你的控制之内或者你没有完全了解它的时候
-
在你的监督或者控制之内,但是闭包是匿名的,使得它没有办法引用或者去除
当 Node 的核心模式实现多个事件触发器(例如 streams)的时候和事件消耗者(例如 http)的时候,它们对他们事件的生命周期都有一个很好的了解。相似的,当设计有事件触发和事件消耗的应用和模块的时候,你就需要花时间去了解刚刚上面说到的行为,并且确定是否很好了解事件的生命周期、是否可以取消注册(绑定)当我们不再需要它的时候.
当注册(绑定)一个监听函数的时候,就要确保它们可以在应用合适的地方被取消注册(绑定)
一个很好的例子就是实现典型的 http
var
http = require(
'http'
);
function
runServer () {
// runServer 里的局部数据,但也可以被创建匿名函数时产生的闭包访问
var
buf =
new
Buffer(1024 * 1024 * 100);
buf.fill(
'g'
);
http.createServer(
function
(req, res) {
res.end(buf);
}).listen(8080);
}
runServer();
|
这个例子虽然给我们展示了使用内部函数的便捷性,但是需要注意的是回调函数,还有那个缓冲对象 buf,会一直存在直到我们创建的 httpServer 被清除时,它们才会被回收掉。你可以通过下面这个截图看到这个缓冲对象会一直存在,因为它被这个服务的一个监听请求的函数用到.
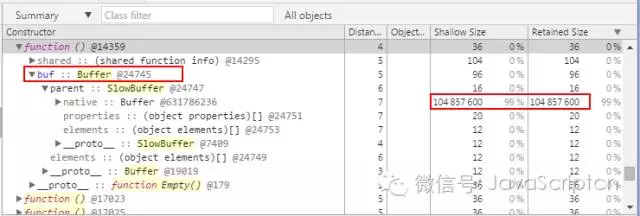
这个例子想要说明的是,对于一些要保留大量数据的监听函数,你需要了解和记录它们被需要的寿命,一旦它们不再被需要,就要注销它们,把它们与事件解除绑定。当然啦,你也可以利用他们生命周期很长这个特点,适当地保留一小部分需要长期使用的数据.
Conclusion
闭包可以灵活地和无限制地绑定数据和代码,是一种很强大的编程结构。然而语义化作用域可能对于一些使用 Java 或者 C++ 的程序员来说并不是那么的熟悉。所以想要避免内存漏泄,很重要的一点就是记住闭包的特性和它的生命周期.