猫眼电影TOP100爬虫
需求分析
根据用户输入的页码数获取猫眼电影TOP100指定页面电影的排名、图片链接、标题、演员表、上映时间、评分。
主要逻辑
- 发送请求,获取响应
- 使用正则表达式提取HTML页面的数据
- 将获取的内容写入到maoyan.txt文件中
页面分析
打开chrome浏览器输入maoyan.com依次点击榜单、TOP100榜进入页面,浏览器地址为https://maoyan.com/board/4
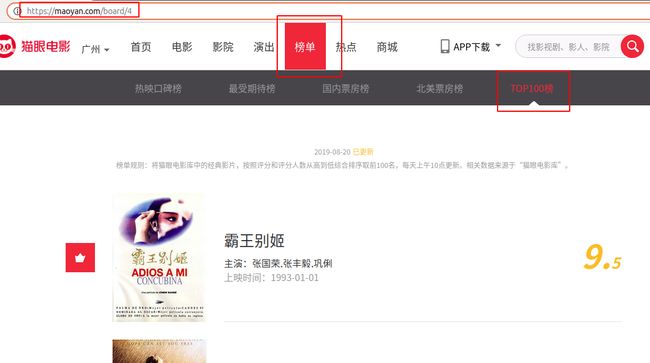
我们需要获取排名、图片链接、标题、演员表、上映时间、评分。

在进入第二页链接变为https://maoyan.com/board/4?offset=10,进入第三页链接变为https://maoyan.com/board/4?offset=20,所以不同页码数对应的地址只有offset=后面的数字不一样为:(当前页码-1)*10
打开检查(或直接按F12)发现每一条电影信息都在一个dd标签中。
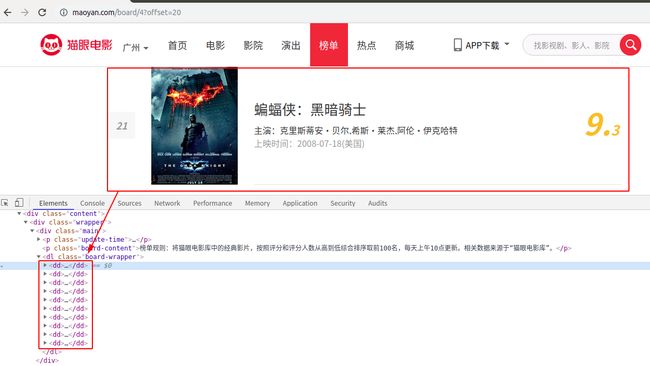
点开发现对应关系,如果觉得看着变扭也可以先在代码里面把html页面下载下来再分析。发现评分是这样的
<i class="integer">9.i>
<i class="fraction">3i>
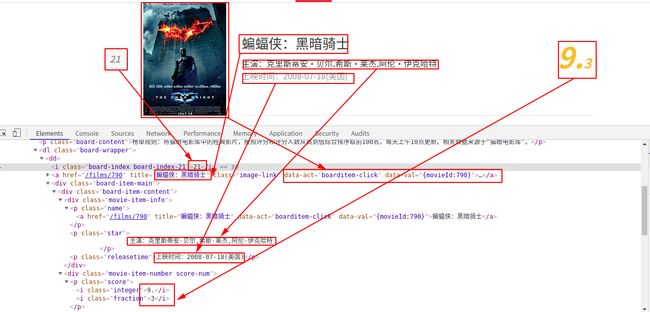
所以后续我们要匹配排名、图片链接、标题、演员表、上映时间、评分的话需要匹配7个分组,评分占用两个分组。正则表达式如下(re.S是为了匹配换行符):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">
+'.*?>(.*?).*?star">(.*?).*?releasetime">(.*?)'
+'.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
如果觉得看不懂的小伙伴可以先学习一下正则表达式,后续我也会出一篇教程专门讲解正则。
主要模块
get_one_page函数发送请求获取响应
def get_one_page(url):
"""发送请求获取响应"""
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response)
return response.text
return None
except RequestException:
return None
-parse_one_page函数正则表达式提取数据
def parse_one_page(html):
"""正则表达式提取数据"""
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">
+'.*?>(.*?).*?star">(.*?).*?releasetime">(.*?)'
+'.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
items = re.findall(pattern, html)
print(len(items))
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5]+item[6]
}
write_to_file函数写入文件
def write_to_file(content):
"""写入文件"""
with open('maoyan.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
main函数实现主要逻辑
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
print(html)
for item in parse_one_page(html): # 循环写入文件
print(item)
write_to_file(item)
- 最后循环运行爬取数据
if __name__ == '__main__':
for i in range(10):
main(i*10)
本文章仅用于学习交流,切勿用于非法用途。同时欢迎各位读者在评论区进行批评指正与交流,与君共勉,让我们一起学爬虫。
完整代码保存在我的个人网站上,感兴趣的小伙伴请点击传送门猫眼电影TOP100爬虫