如何使用Java语言实现一个网页爬虫
网络上有许多信息,我们如何自动的获取这些信息呢?没错,网页爬虫~!
在这篇博文中,我将会使用java语言一步一步的编写一个原型的网页爬虫,其实网页爬虫并没有它听起来那么难。紧跟我的教程,我相信你会在马上学会,一个小时应该可以搞定,之后你就可以享受你所获得的大量数据。这次所编写的是最简单的教程,可以说是网页爬虫的hello world程序, 由于仅仅是原型,之后你要花更多的时间来研究并未自己来定制特定需求的爬虫。
首先,我认为你已经掌握了下面的基础知识:
1.基础的java编程
2.关于sql以及mysql数据库或者oracle数据库
如果你不想使用数据库的话,你可以用一个文件来将爬到的数据存储好。
一、我们的目标
给定一个学校的URL,例如“mit.edu”,返回包括字符串“research”所有的这个学校的页面。
一个经典的爬虫程序步骤:
1.解析根网页(“mit.edu”),并从这个网页得到它所有的链接。获取每个URL并解析HTML页面,我会使用Jsoup来处理,Jsoup是一个好用而且方便的java库。
2.使用步骤1返回回来的URL,解析这些URL。
3.当我们在做上面两个步骤的时候,我们需要跟踪哪些页面是之前已经被处理了的,那样的话,每个页面只需被处理一次。这也是我们为什么需要数据库的原因了。
二、建立Mysql数据库
如果你使用的是ubuntu, 你可以使用经典的Apache, MySQL, PHP, and phpMyAdmin来操作。
如果你是用的是windows,你可以简单的使用wampServer或者SQLlog并安装,也可以使用oracle数据库,可以使用PLSQL developer工具。
这里我使用mysql sqllog工具,它是使用mysql数据化的一个可视化的GUI工具,当然你也可以使用其他的工具或者方法。
三、创建数据库以及表
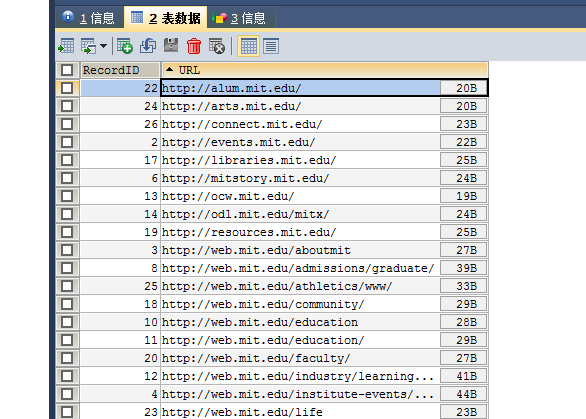
创建一个数据库名为:Crawler,创建一个表,名为:Record
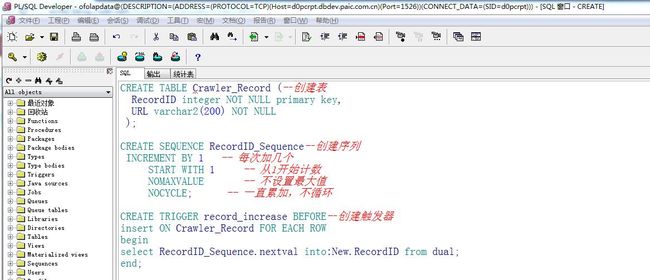
下面是一个oracle sql 脚本
CREATE TABLE Record (--创建表
RecordID integer NOT NULL primary key,
URL varchar2(200) NOT NULL
);
CREATE SEQUENCE RecordID_Sequence--创建序列
INCREMENT BY 1 -- 每次加几个
START WITH 1 -- 从1开始计数
NOMAXVALUE -- 不设置最大值
NOCYCLE; -- 一直累加,不循环
CREATE TRIGGER record_increase BEFORE--创建触发器
insert ON Record FOR EACH ROW
begin
select RecordID_Sequence.nextval into:New.RecordID from dual;
end;
如果是mysql的话,如此执行:
CREATE TABLE IF NOT EXISTS `Record` (
`RecordID` INT(11) NOT NULL AUTO_INCREMENT,
`URL` TEXT NOT NULL,
PRIMARY KEY (`RecordID`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;下图是使用pl/sql的示例图:
四、使用Java开始爬虫
1. 下载Jsoup核心库,点击这里下载。
“`
如果使用oracle数据库, 你需要下载oracle的JDBC驱动jar包,ojdbc14.jar包
如果使用mysql数据库,那么需要下载mysql-connector-java 的jar包
2. 在Eclipse中创建项目,并将Jsoup库jar以及ojdbc14.jar也加入到Java Build Path(右键点击项目,选择build path—>”Configure Build Path” –> click “Libraries” tab –> click “Add External JARs”)
3. 创建一个DB类,来处理数据库的操作。
package crawlerDemo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class DB {
public Connection conn = null;
public DB() {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/Crawler";
conn = DriverManager.getConnection(url, "wonderq", "root");
System.out.println("conn built");
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public ResultSet runSql(String sql) throws SQLException {
Statement sta = conn.createStatement();
return sta.executeQuery(sql);
}
public boolean runSql2(String sql) throws SQLException {
Statement sta = conn.createStatement();
return sta.execute(sql);
}
@Override
protected void finalize() throws Throwable {
if (conn != null || !conn.isClosed()) {
conn.close();
}
}
public static void main(String[] args) {
new DB();
}
}4.创建一个名为“Main”的类,这个类将是我们的爬虫。
package crawlerDemo;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Main {
public static DB db = new DB();
public static void main(String[] args) throws SQLException, IOException {
db.runSql2("TRUNCATE Record;");
processPage("http://www.mit.edu");
}
public static void processPage(String URL) throws SQLException, IOException{
//检查一下是否给定的URL已经在数据库中
String sql = "select * from Record where URL = '"+URL+"'";
ResultSet rs = db.runSql(sql);
if(rs.next()){
}else{
//将uRL存储到数据库中避免下次重复
sql = "INSERT INTO `Crawler`.`Record` " + "(`URL`) VALUES " + "(?);";
PreparedStatement stmt = db.conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
stmt.setString(1, URL);
stmt.execute();
//得到有用的信息
Document doc = Jsoup.connect("http://www.mit.edu/").get();
if(doc.text().contains("research")){
System.out.println(URL);
}
//得到所有的链接,并递归调用
Elements questions = doc.select("a[href]");
for(Element link: questions){
if(link.attr("href").contains("mit.edu"))
processPage(link.attr("abs:href"));
}
}
}
}现在你已经得到了自己的爬虫,run一下, 看看结果吧。
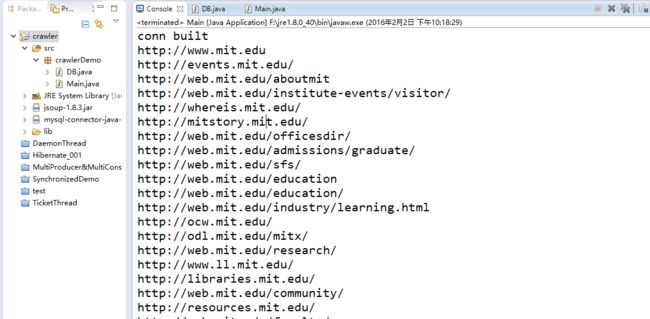
查看mysql数据库,如下所示: