Python爬虫小白教程(一)—— 静态网页抓取
文章目录
- 安装Requests库
- 获取响应内容
- 定制Requests
- 传递URL参数
- 定制请求头
- 发送 POST 请求
- 超时
- 后记
- 爬虫系列
安装Requests库
Requests库是Python中抓取网页的一个开源库,功能极为强大。我们可以通过pip安装,如果使用Anaconda的话也可以使用conda安装。
如使用pip安装,打开cmd,输入:
pip install requests
如使用Anaconda,则打开Anaconda Prompt,输入:
conda install requests
获取响应内容
在Requests库中,最常用的功能就是获取某个网页的内容。现在我们使用Requests获取CSDN主页的内容。
import requests
response = requests.get('https://www.csdn.net')
print("文本编码:",response.encoding)
print("响应状态码", response.status_code)
print("字符串形式的响应体:", response.text)
这样就返回了一个名为response的响应对象,我们可以由此获取我们所需要的信息。上述代码的结果如图所示。

上例的说明如下:
response.text是服务器相应的内容response.encoding是服务器内容使用的文本编码response.status_code是检测相应的状态码,如果返回200,就表示请求成功;返回4xx,表示客户端错误;返回5xx则表示服务器错误响应。
定制Requests
有些网页需要对Requests的参数设置才能获取正确的信息,包括传递URL参数、定制请求头、发送POST请求、设置超时等。
传递URL参数
为了请求某些特定的数据,我们需要在URL后面加上某些数据,一般跟在一个?后面,并以键值对的形式放在URL中,如https://www.url.com/get?key1=value1&key2=value2。
在Python中按照下面方式使用。
import requests
key_dict = {'key1' : 'value1', 'key2' : 'value2'}
response = requests.get('http://url.com/get', params=key_dict)
print("URL正确编码:", response.url)
输出如下:
URL正确编码:https://www.url.com/get?key1=value1&key2=value2
定制请求头
在某些情况下如果请求头和实际网页不一致,则可能无法返回正确的结果。
首先要找到正确的请求头。在Chrome浏览器中右键,选择检查,然后点击Network

然后在左侧资源中找到需要的网页,在Header中可以看到Requests Header的详细信息,如下图所示。
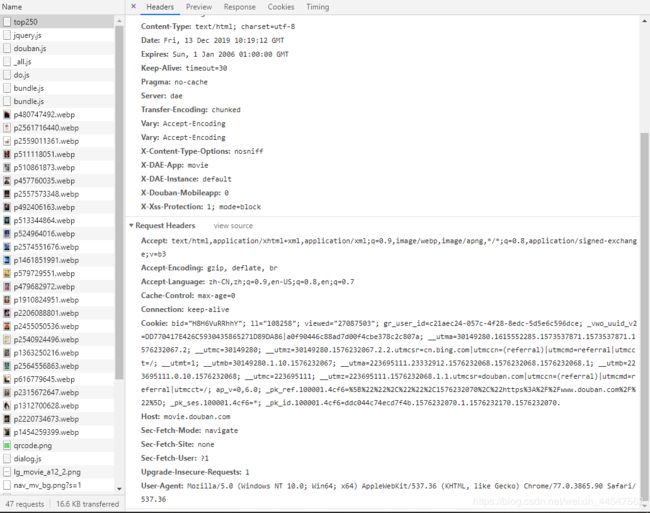
然后我们得到请求头的信息为:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Cache-Control: max-age=0
Connection: keep-alive
Cookie: bid="H8H6VuRRhhY"; ll="108258"; viewed="27087503"; gr_user_id=c21aec24-057c-4f28-8edc-5d5e6c596dce; _vwo_uuid_v2=DD770417E426C5930435865271D89DA86|a0f90446c88ad7d00f4cbe378c2c807a; __utma=30149280.1615552285.1573537871.1573537871.1576232067.2; __utmc=30149280; __utmz=30149280.1576232067.2.2.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmb=30149280.1.10.1576232067; __utma=223695111.23332912.1576232068.1576232068.1576232068.1; __utmb=223695111.0.10.1576232068; __utmc=223695111; __utmz=223695111.1576232068.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1576232070%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; _pk_id.100001.4cf6=ddc044c74ecd7f4b.1576232070.1.1576232170.1576232070.
Host: movie.douban.com
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36
提取请求头中重要的部分,可以把代码改为:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Host':'movie.douban.com'
}
response = requests.get('https://movie.douban.com/top250', headers=headers)
print("响应状态码:", response.status_code)
发送 POST 请求
在登录的时候我们会用到POST,只需要简单地传递一个字典给Requests中地data参数,这个数据字典就会在发送请求地时候自动编码为表单(form)形式。
import requests
key_dict = {'key1' : 'value1', 'key2' : 'value2'}
response = requests.get('http://url.com/get', data=key_dict)
print(response.text)
输出地结果为:
{
......
"form":{
"key1":"value1",
"key2":"value2"
},
}
可以看到,form的变量值为key_dict输入的值,这样POST就成功了。
超时
有些时候会遇到服务器长时间不响应,这时爬虫一直等待,从而导致爬虫程序无法顺利执行。因此可以在Requests的timeout参数中设置最大等待时间,如果服务器在timeout秒内无响应,就返回异常。
下面我们爬取YouTube网站试一下。
import requests
url = "https://www.youtube-nocookie.com/embed"
response = requests.get(url, timeout= 10)
返回结果如下:
ConnectTimeout: HTTPSConnectionPool(host='www.youtube-nocookie.com', port=443):
Max retries exceeded with url: /embed (Caused by ConnectTimeoutError
(,
'Connection to www.youtube-nocookie.com timed out. (connect timeout=10)'))
异常值的意思是在时间限制10秒内,连接到地址为 https://www.youtube-nocookie.com/embed 的时间已到。
后记
根据本博客的内容我写了一篇爬虫实践,趁热打铁,再好不过了!详见
Python爬虫小白教程(二)—— 爬取豆瓣评分TOP250电影
爬虫系列
Python爬虫小白教程(一)—— 静态网页抓取
Python爬虫小白教程(二)—— 爬取豆瓣评分TOP250电影
Python爬虫小白教程(三)——使用正则表达式分析网页
Python爬虫小白教程(四)—— 反反爬之IP代理池
Python爬虫小白教程(五)—— 多线程爬虫