运维基础——日志分析处理工具
1. ELK
Elasticsearch
基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
logstash
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
说到搜索,logstash带有一个web界面,搜索和展示所有日志。
kibana
Logstash是一个完全开源的工具,为 Logstash 和 ElasticSearch 提供的日志分析的 Web 接口,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索),您可以使用它。说到搜索,logstash带有一个web界面,搜索和展示所有日志。
2. SkyEye
对java、scala等运行于jvm的程序进行实时日志采集、索引和可视化,对系统进行进程级别的监控,对系统内部的操作进行策略性的报警、对分布式的rpc调用进行trace跟踪以便于进行性能分析
https://github.com/JThink/SkyEye
3. flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
日志收集
Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
针对实时数据分析,可以使用:
flume-ng+Kafka+Storm
4. Scribe
https://github.com/facebook/scribe
Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。其通常与Hadoop结合使用,scribe用于向HDFS中push日志,而Hadoop通过MapReduce作业进行定期处理。
5. Cloudera Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
一些flume的应用:
flume+kafka+storm+mysql构建大数据实时系统
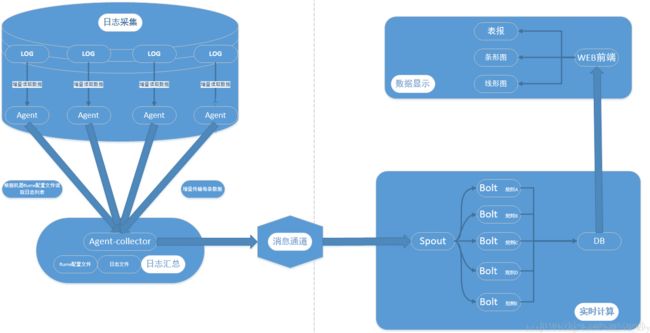
Flume+HDFS+KafKa+Strom实现实时推荐,反爬虫服务等服务在美团的应用

Flume+Hadoop+Hive的离线分析网站用户浏览行为路径
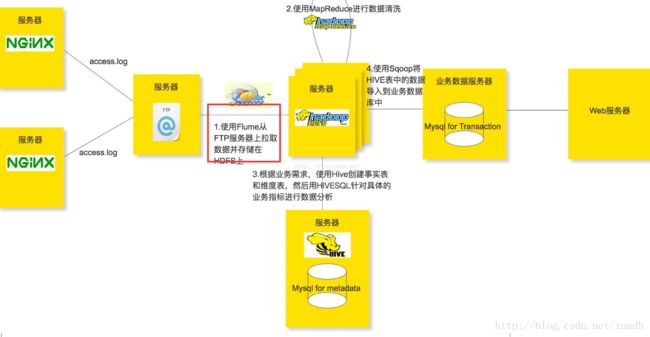
Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析

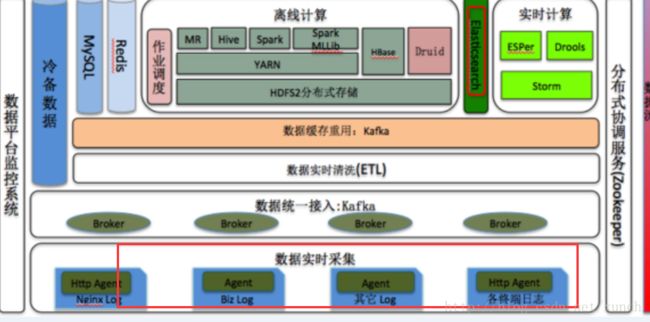
Flume+Spark + ELK新浪数据系统实时监控平台
6. Log Parser 微软的日志分析工具
主要针对windows的系统日志的分析工具。
LogParser.exe 为可执行文件,后跟一个使用 SQL 结构的语句参数进行查询。
C:\Program Files\Log Parser 2.2>LogParser “SELECT TOP 10 * FROM System ORDER BY RecordNumber DESC”
从系统日志(可以从事件查看器中找到)中,选出按 RecordNumber 逆序的前 10 条记录。RecordNumber 是 System 中的一个字段。
7. Splunk
是一个长期的基础设施的数据分析。它历来被认为是一个日志收集或聚集的工具,但它已发展成为一个伪大数据分析工具。 Splunk的扩展了它的使用案例,包括各种数据,棒球分析。
Splunk扩展基础设施管理的多样化分析工具,Splunk的并不限制数据源的来源。 Splunk的允许数据从收集的东西(IOT)设备和传感器网络中获取数据。一个例子分析可以分析数据中心机架的温度,来分析数据中心是否会受到影响。
Splunk允许使用向导来创建简单但功能强大的数据分析。对于高级用户,Splunk的利用其搜索处理语言(SPL)创建更深和更先进的数据相关性。
Splunk的是两个版本:免费版和企业。免费版本,该数据集的限制为500MB;它必须在非商业环境中使用,而且功能方面还有一些限制。
8. Sumo Logic
Sumo 是在 Splunk 的基础上建立的 SaaS 版本,它沿用了 Splunk 早期的一些特性和视觉效果。不得不说,SL 今天已经发展成了一个成熟的企业级日志管理工具。是一个收费软件。
9. vRealize Log Insight
vRealize Log Insight的前身为vCenter Log Insight,是VMware的分析工具,能够为VMware环境提供实时记录档案管理,在实体、污泥与云端环境中可以发挥极其学习似智慧型群组、高效能搜寻与更加的疑难排除等功能。
10. Virtual Instruments
当手机日志和分析有关海量数据的时候,主要考虑的是基础设施所产生的开销,无论是一个企业的应用程序还是基础设施工具,都是大数据的基础,那么有没有一种仪器能够完善数据的收集和分析呢?Virtual Instruments就是这样的一个设备来进行数据分析。
Virtual Instruments提供了收集数据的功能以及分析工具VirtualWisdom,Virtual Instruments医疗通过从网络、存储以及服务器监控得到的信息,利用现有客户端的数据,来帮助客户分析出有价值的信息。既简单又方便。
11. TimeTunnel
http://code.taobao.org/p/TimeTunnel/src/
TimeTunnel(简称 TT)是一个基于thrift通讯框架搭建的实时数据传输平台,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点(基于Hbase)。
目前TimeTunnel在阿里巴巴广泛的应用于日志收集、数据监控、广告反馈、量子统计、数据库同步等领域。
12. Loggly
Loggly 也是一个健壮的日志分析工具,强调简洁朴素让开发者用起来方便。
13. PaperTrails
PaperTrails 擅长从多台机器上查找日志,并提供一个合并的窗口,使用起来很方便。是基于文本格式的。如果需要支持先进的集成、预测和报告功能,就显得力不从心了。
14. Graylog2
用 MongoDB 和 ElasticSearch 支持的用来存储与搜索日志错误的工具。它致力于帮助开发者找到并修复程序中的错误。
15. Takipi for Logs
对于日志分析工具来说,最大的缺点就是你必须要有日志可以分析。从集成开发环境的角度看,如果没有异常报告,或者没有错误信息的数据,你就没办法知道哪里出问题了,这样世界上任何工具都帮不了你了!Debug 就卡在这里了。:(
在 Takipi 的一项优势就是可以跳过日志文件,进入到调试信息中。这样你就能看到真实的源代码和错误范围的变量了。了解更多点击这里。
Takipi 会报告所有的异常和错误,并且告诉你哪里出错了,即使是多线程或者是发生在多台机器上。1分钟之内就能安装,维护费用不足2%.
参考:
http://server.zol.com.cn/507/5079410_all.html
http://www.importnew.com/12383.html
http://www.cnblogs.com/zhangs1986/p/6897200.html