Hive SQL 优化
要想做好hive优化,首先要理解MR过程,HiveSQL转换为MR的过程,以及Hive表的分区分桶机制。
本质上的优化是,减少读,避免shuffle 和 增加并发度。
优化的手段:
| 跳过不必要的读 | 减少Shuffle | 读延迟问题 | 数据倾斜 |
|---|---|---|---|
| Partition、Bucket 使用 Skew(hive对声明了Skew的列会单独使用文件存储,并且在资源分配上有优待) | MapJoin(Broadcast Join),避免ReduceJoin | 增加热数据备份数 | 对于倾斜部分单独拿出来,做Map Join |
| ORCFile => 支持只读需要的列 | Sort-Merge-Bucket Join | 启动短路读(Short-Circuit Read),即不通过网络客户端,而是直接读取本地文件 | 将倾斜Key绑定一个随机数R,先按key、R做一次Shuffle,聚合减少数据量,然后再按Key做Shuffle聚合。 |
| 使用Tez |
Shuffle Sort/ Map Reduce 原理理解
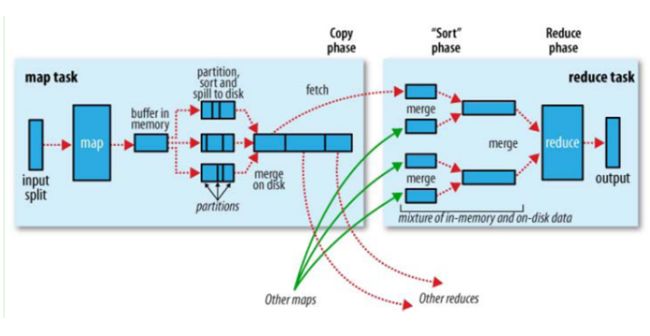
Map Shuffle 过程:
(1)读取block,并切分为多个split,每个split对应一个map task。
(2)按Key 进行 Partition,内存排序,排序结果放入缓存,缓存不够发生溢写。
(3)溢写文件和内存中数据最终归并排序输出Map的结果,最后合并成了一个已分区且已排序的文件。
Reduce Shuffle 过程:
(1)Reduce Task 通过Copy方式,拉取Map task输出的文件,每次传输来的数据都是有序的。
(2)拉取的数据写缓存,缓存不够造成溢写。
(3)每个Ruduce任务,会直接将各个溢写的文件归并排序的结果作为输入,产出reudce的结果。
Hive SQL To Mapreduce 过程(感谢美团团队整理)
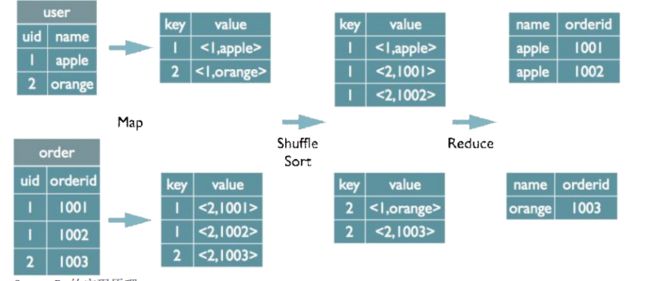
Join的实现原理
使用Join 关联的字段作为Key,并为Value打上不同的表来源标识。
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下 (这里只是说明最基本的Join的实现,还有其他的实现方式)
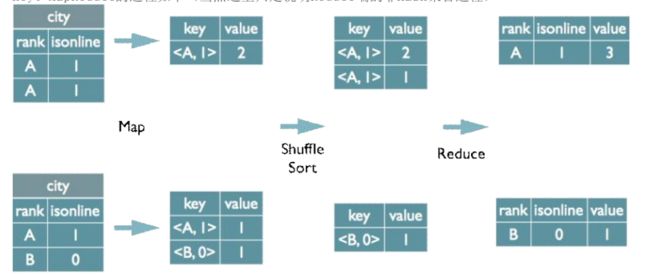
Group By的实现原理
Group By 的字段组合作为Key,并且Map端预聚合
select rank, isonline, count(*) from city group by rank, isonline; 将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的 key。MapReduce的过程如下(当然这里只是说明Reduce端的非Hash聚合过程)
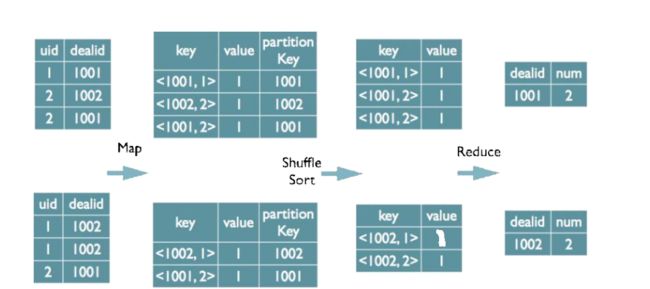
Distinct的实现原理
单个distinct,使用group字段和distinct字段作为排序Key,Group字段作为分区Key,在Reduce阶段保存LastKey(因为排序后每组是按key有序的,因此只需使用一个LastKey作为去重字段)
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为 map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去 重
如果有多个distinct字段呢,如下面的SQL select dealid, count(distinct uid), count(distinct date) from order group by dealid;
实现方式有两种:
(1)和单个Distinct相同,但是内存阶段通过Hash去重。
如果仍然按照上面一个distinct字段的方法,即下图这种实现方式,无法跟据uid和date分别排序,也就无法 通过LastKey去重,仍然需要在reduce阶段在内存中通过Hash去重
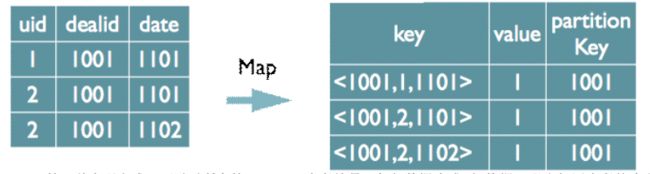
(2)对所有的distinct字段编号,每行数据生成n行数据,按单个distinct进行处理。
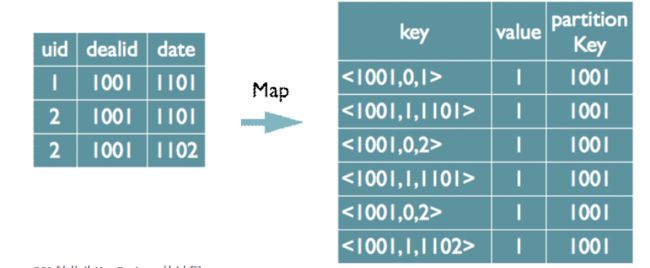
第二种实现方式,可以对所有的distinct字段编号,每行数据生成n行数据,那么相同字段就会分别排序,这 时只需要在reduce阶段记录LastKey即可去重。 这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数 据量。 需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行 value字段均可为空。
理解 查询语句中 Cluster By,Distribute By,Sort By 和 Order By
Cluster By col = 按 col 列 Distribute By + Sort By。
Distribut By col1 和 Sort By col2 通常联合使用,是指的按col1 Partition 并且 按 col2 组内排序。
Order By 是指的全局有序,只有一个Reducer。

理解 建表语句中的Clustered By 、Sorted By 和 Skewed By
Clustered by 是插入数据是按某些列进行分Bucket(文件级别),而Sorted By 是按某些列全局排序,并分桶。
Skewed By 是对倾斜列做特殊处理,单独文件存储。

HIve 优化的方向
| 跳过不必要的读 | 减少Shuffle | 读延迟问题 |
|---|---|---|
| Partition、Bucket 使用 Skew(hive对声明了Skew的列会单独使用文件存储,并且在资源分配上有优待) | MapJoin(Broadcast Join),避免ReduceJoin | 增加热数据备份数 |
| ORCFile => 支持只读需要的列 | Sort-Merge-Bucket Join | 启动短路读(Short-Circuit Read) |
| 使用Tez |
Map Side Join
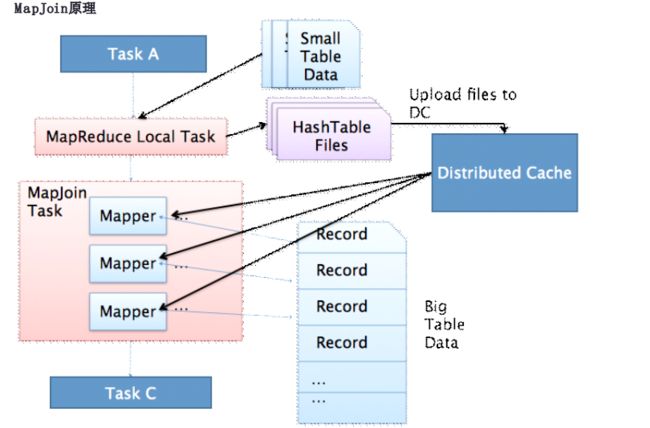
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。 上图是Hive MapJoin的原理图,出自Facebook工程师Liyin Tang的一篇介绍Join优化的slice,从图中可以看出 MapJoin分为两个阶段: 1. 通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会对 HashTableFiles进行压缩。 2. MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map 阶段直接进行Join,将数据传递给下一个MapReduce任务
SET hive.auto.convert.join=true;
SET hive.mapjoin.smalltable.filesize = 20000000
Select /*+ mapjoin(tablelist) */
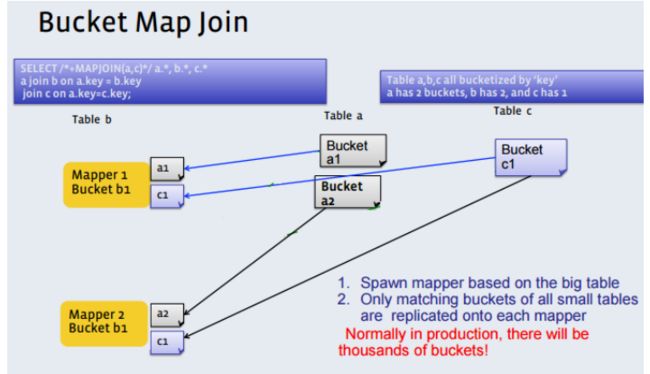
Bucket mapjoin
1) set hive.optimize.bucketmapjoin = true;
2) 一个表的bucket数是另一个表bucket数的整数倍:即一个大表,一个小表
3) bucket列 == join列
4) 必须是应用在map join的场景中
在这种情况下,大表和小表都是按Key分桶的,且大表的桶数是小标的n倍,这样,就可以n个大表桶,对应1个小表桶,将1个小表桶做广播到n个大表桶,做Map Side Join。
SMB join (针对bucket mapjoin 的一种优化)
1)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputF ormat;
2) 小表的bucket数=大表bucket数
3) Bucket 列 == Join 列 == sort 列
4) 必须是应用在bucket mapjoin 的场景中
在这种情况下,桶数相同,且每桶的key都是排序的,因此在读入Mapper时,相同的Key一定出现在同一个Map中,相当于Shuffle sort之后的Reudce过程,可以做Map Side Join。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yhyQx3tY-1591253004454)(http://cdn.rabbitai.cn/hive/13.png)]
Skew(倾斜) 优化
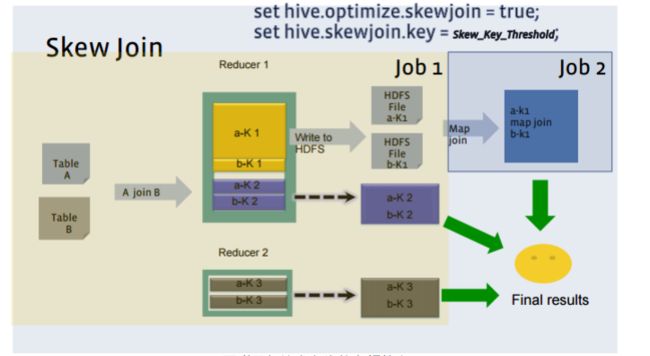
数据倾斜的核心思想,是在Map Shuffle阶段,就统计出需要单独做Map Join 的Key,把倾斜的部分拿出来,单独做Map Side Join,不走reduce Shuffle。
select A.id from A join B on A.id = B.id
-- 转化为,倾斜部分和非倾斜部分
select A.id from A join B on A.id = B.id where A.id <> 1;
select A.id from A join B on A.id = B.id where A.id = 1 and B.id = 1;
-- 如果建表语句元数据中指定了skew key,则使用set hive.optimize.skewjoin.compiletime=true开启skew join。
CREATE TABLE list_bucket_single (key STRING, value STRING) SKEWED BY (key)
ON (1,5,6);
-- 在运行时动态指定数据进行skewjoin,一般和hive.skewjoin.key参数一起使用
set hive.optimize.skewjoin = true;
set hive.skewjoin.key =100000
-- 以上参数表示当记录条数超过100000时采用skewjoin操作
### group by 倾斜优化
对于确定的倾斜值,先均匀分布到各个reducer上,然后开启新一轮reducer进行统计操作。写法如下
-- 正常写法
select key
, count(1) as cnt
from tb_name
group by key;
-- 改进后写法
select a.key
, sum(cnt) as cnt
from (select key
, if(key = 'key001',random(),0)
, count(1) as cnt
from tb_name
group by key,
if(key = 'key001',random(),0)
) t
group by t.key;
如果在不确定倾斜值的情况下,可以设置hive.groupby.skewindata参数,其原理和上述写法调整中类似,是先对key值进行均匀分布,然后开启新一轮reducer求值
set hive.groupby.skewindata=true;
select key
, count(1) as cnt
from tb_name
group by key;
参考:
Antlr: http://www.antlr.org/
Wiki Antlr介绍: http://en.wikipedia.org/wiki/ANTLR
Hive Wiki: https://cwiki.apache.org/confluence/display/Hive/Home
HiveSQL编译过程: http://www.slideshare.net/recruitcojp/internal-hive
Join Optimization in Hive: Join Strategies in Hive from the 2011 Hadoop Summit (Liyin Tang, Namit Jain) Hive Design Docs: https://cwiki.apache.org/confluence/display/Hive/DesignDocs