【梳理】简明操作系统原理 第八章 条件变量和信号量(内附文档高清截图)
参考教材:
Operating Systems: Three Easy Pieces
Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
在线阅读:
http://pages.cs.wisc.edu/~remzi/OSTEP/
University of Wisconsin Madison 教授 Remzi Arpaci-Dusseau 认为课本应该是免费的。
————————————————————————————————————————
这是专业必修课《操作系统原理》的复习指引。
在本文的最后附有复习指导的高清截图。需要掌握的概念在文档截图中以蓝色标识,并用可读性更好的字体显示 Linux 命令和代码。代码部分语法高亮。
操作系统原理不是语言课,本复习指导对用到的编程语言的语法的讲解也不会很细致。如果不知道代码中的一些关键字或函数的具体用法,你应该自行查找相关资料。
八 条件变量与信号量
1、条件变量(condition variable)是一种队列,其中的线程正在等待某个条件满足。当一个线程要求的条件达成后,线程就继续执行。这称为标记(signal)条件。这个思想最早出自E. W. Dijkstra,他称之为私有信号量(private semaphores)。后来,Tony Hoare将其命名为条件变量。
引入条件变量,是为了能让线程实现在需要等待一个自定义的条件满足以后继续执行。有些情况下,如果不使用条件变量,这个目的只能通过旋转锁来实现,大量耗费CPU。条件变量使得无需进行这样的忙等待。
C++11的头文件
2、一个条件变量有两个主要的成员函数:wait()和signal(),分别对应线程的睡眠和唤醒操作。具体来说,Linux中对应pthread_cond_wait()、pthread_cond_signal();而std::condition_variable中则对应wait()、notify_one()和notify_all()。为了方便,以后我们常常用wait()和signal()来统一指代。
这两个操作都是原子操作。
3、wait()接受一个互斥锁为参数。当wait()被调用时,它假设传入的互斥锁是上锁的。调用wait()将尝试解锁并令线程进入睡眠。当然,这也是原子操作,调度器无法将其打断。当线程被唤醒后,又被再次上锁。使用条件变量需要防止的一个主要问题是避免有线程陷入永久休眠而没有线程能够唤醒它。
来看下面的代码:
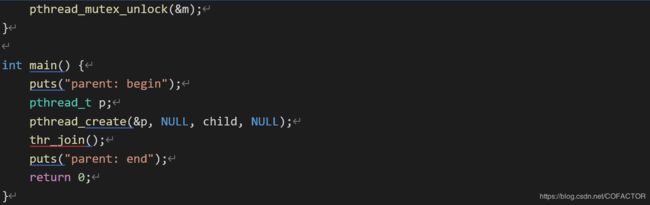
#include
#include
int done = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c = PTHREAD_COND_INITIALIZER;
void thr_exit() {
pthread_mutex_lock(&m);
done = 1;
pthread_cond_signal(&c);
pthread_mutex_unlock(&m);
}
void* child(void* arg) {
puts(“child”);
thr_exit();
return NULL;
}
void thr_join() {
pthread_mutex_lock(&m);
while (done == 0) pthread_cond_wait(&c, &m);
pthread_mutex_unlock(&m);
}
int main() {
puts(“parent: begin”);
pthread_t p;
pthread_create(&p, NULL, child, NULL);
thr_join();
puts(“parent: end”);
return 0;
}
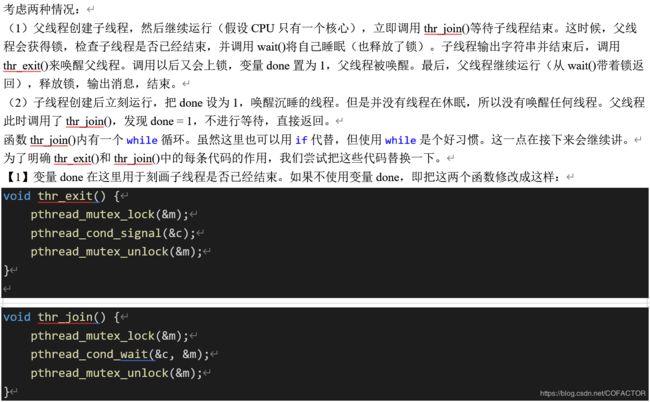
考虑两种情况:
(1)父线程创建子线程,然后继续运行(假设CPU只有一个核心),立即调用thr_join()等待子线程结束。这时候,父线程会获得锁,检查子线程是否已经结束,并调用wait()将自己睡眠(也释放了锁)。子线程输出字符串并结束后,调用thr_exit()来唤醒父线程。调用以后又会上锁,变量done置为1,父线程被唤醒。最后,父线程继续运行(从wait()带着锁返回),释放锁,输出消息,结束。
(2)子线程创建后立刻运行,把done设为1,唤醒沉睡的线程。但是并没有线程在休眠,所以没有唤醒任何线程。父线程此时调用了thr_join(),发现done = 1,不进行等待,直接返回。
函数thr_join()内有一个while循环。虽然这里也可以用if代替,但使用while是个好习惯。这一点在接下来会继续讲。
为了明确thr_exit()和thr_join()中的每条代码的作用,我们尝试把这些代码替换一下。
【1】变量done在这里用于刻画子线程是否已经结束。如果不使用变量done,即把这两个函数修改成这样:
void thr_exit() {
pthread_mutex_lock(&m);
pthread_cond_signal(&c);
pthread_mutex_unlock(&m);
}
void thr_join() {
pthread_mutex_lock(&m);
pthread_cond_wait(&c, &m);
pthread_mutex_unlock(&m);
}
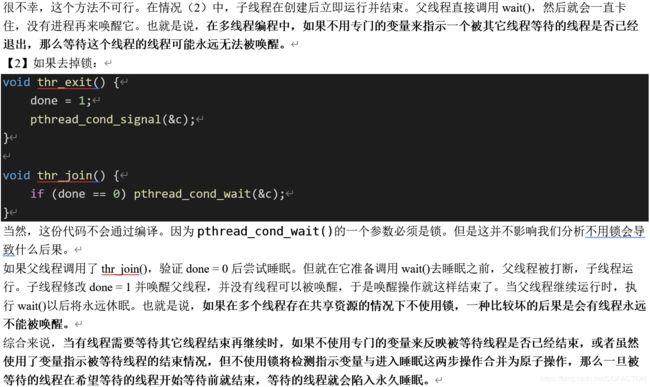
很不幸,这个方法不可行。在情况(2)中,子线程在创建后立即运行并结束。父线程直接调用wait(),然后就会一直卡住,没有进程再来唤醒它。也就是说,在多线程编程中,如果不用专门的变量来指示一个被其它线程等待的线程是否已经退出,那么等待这个线程的线程可能永远无法被唤醒。
【2】如果去掉锁:
void thr_exit() {
done = 1;
pthread_cond_signal(&c);
}
void thr_join() {
if (done == 0) pthread_cond_wait(&c);
}
当然,这份代码不会通过编译。因为pthread_cond_wait()的一个参数必须是锁。但是这并不影响我们分析不用锁会导致什么后果。
如果父线程调用了thr_join(),验证done = 0后尝试睡眠。但就在它准备调用wait()去睡眠之前,父线程被打断,子线程运行。子线程修改done = 1并唤醒父线程,并没有线程可以被唤醒,于是唤醒操作就这样结束了。当父线程继续运行时,执行wait()以后将永远休眠。也就是说,如果在多个线程存在共享资源的情况下不使用锁,一种比较坏的后果是会有线程永远不能被唤醒。
综合来说,当有线程需要等待其它线程结束再继续时,如果不使用专门的变量来反映被等待线程是否已经结束,或者虽然使用了变量指示被等待线程的结束情况,但不使用锁将检测指示变量与进入睡眠这两步操作合并为原子操作,那么一旦被等待的线程在希望等待的线程开始等待前就结束,等待的线程就会陷入永久睡眠。
4、通过上面两个样例,你已经可以看到不正确使用条件变量带来的后果。接下来我们引入生产者-消费者问题(producer-consumer problem),或称有限缓冲区问题(bounded-buffer problem)。
有一些线程,一些是生产者,生成数据并放入缓冲区;一些是消费者,从缓冲区取走数据并使用。这种情况在实际的系统中常常出现。例如Web服务器中,一个生产者线程把HTTP请求放入队列,消费者线程从队列中取出请求并处理。再例如两个进程通过管道(pipe)进行通信时,发送和接收数据的一端分别属于生产者和消费者。
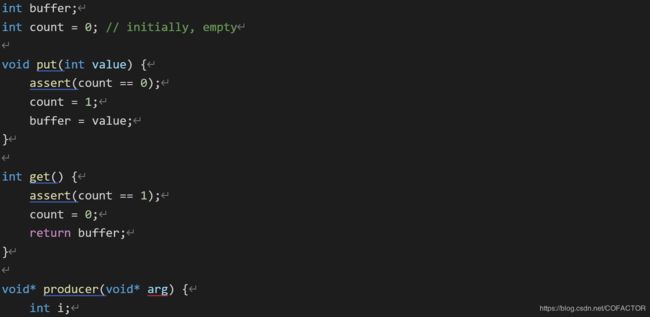
缓冲区为线程所共享,所以必须保证同步访问,否则会导致竞争条件。看下面一段代码:
int buffer;
int count = 0; // initially, empty
void put(int value) {
assert(count == 0);
count = 1;
buffer = value;
}
int get() {
assert(count == 1);
count = 0;
return buffer;
}
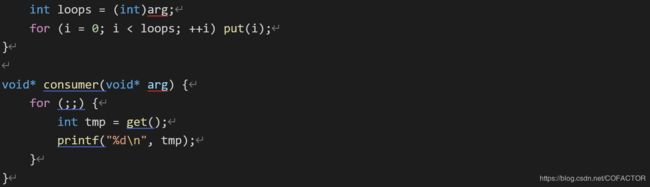
void* producer(void* arg) {
int i;
int loops = (int)arg;
for (i = 0; i < loops; ++i) put(i);
}
void* consumer(void* arg) {
for (; {
int tmp = get();
printf("%d\n", tmp);
}
}
为了方便,设缓冲区buffer仅为一个整数。两个过程分别从缓冲区写入和读出数据。put()假设缓冲区为空(用系统调用assert()检验)。然后将数据写入缓冲区,并标记缓冲区已满。可见,只有count = 0时才可以写入数据,count = 1时才可以读出数据。如果尝试向已满的缓冲区写入或从空缓冲区读出,assert()会输出错误信息并结束进程。由专门的线程来producer和consumer分别负责调用put()和get()。
显然,put()和get()都具有临界区。但是光把锁补充上去是不够的,还需要其它东西。
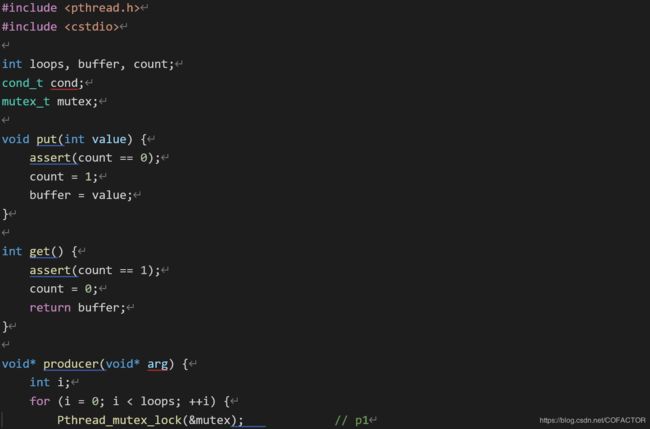
5、看下面一段代码:
#include
#include
int loops, buffer, count;
cond_t cond;
mutex_t mutex;
void put(int value) {
assert(count == 0);
count = 1;
buffer = value;
}
int get() {
assert(count == 1);
count = 0;
return buffer;
}
void* producer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
Pthread_mutex_lock(&mutex); // p1
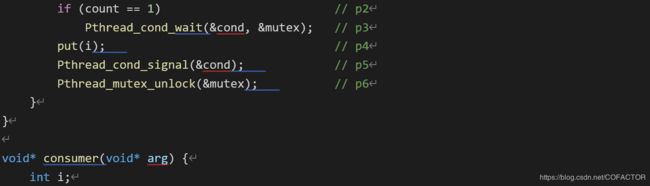
if (count == 1) // p2
Pthread_cond_wait(&cond, &mutex); // p3
put(i); // p4
Pthread_cond_signal(&cond); // p5
Pthread_mutex_unlock(&mutex); // p6
}
}
void* consumer(void* arg) {
int i;
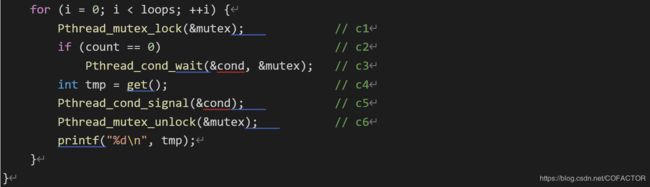
for (i = 0; i < loops; ++i) {
Pthread_mutex_lock(&mutex); // c1
if (count == 0) // c2
Pthread_cond_wait(&cond, &mutex); // c3
int tmp = get(); // c4
Pthread_cond_signal(&cond); // c5
Pthread_mutex_unlock(&mutex); // c6
printf("%d\n", tmp);
}
}
这里添加了条件变量cond和一个锁mutex。
我们来考察过程producer和consumer。同样,生产者写入缓冲区之前先确认缓冲区为空,消费者读出缓冲区前先确认缓冲区非空。当只有1个生产者和1个消费者时,这份代码是可以正常运作的。但是如果作为生产者或消费者的线程多于1个呢?这会导致两个临界问题。
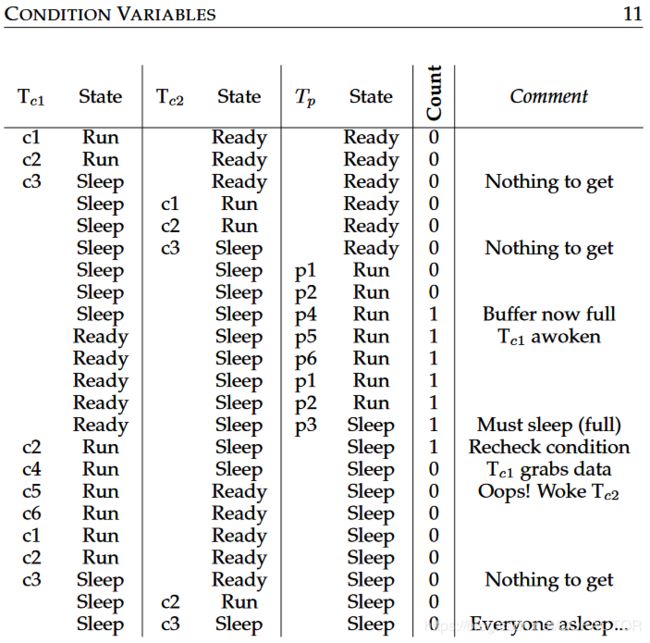
设一个核心上分配有一个生产者线程TP和两个消费者线程TC1、TC2,它们在临界区中需要执行的步骤(p1 ~ p6,c1 ~ c6)已经在代码中用注释标记。在运行中,可能会发生这样的情况:
假设调度器选择TC1先运行。后者检测到缓冲区为空就休眠。接下来调度器运行的线程是TP。由于缓冲区为空,因此TP不等待,而是写入缓冲区并唤醒消费者。TP继续运行一段时间后,检测到缓冲区已满,遂休眠。休眠后,调度器选择TC2继续运行。TC2顺利在缓冲区中取完数据并在唤醒生产者、释放锁(步骤c6)后被暂停。但是接下来调度器选择继续运行的线程却是TC1。TC1从暂停的位置开始继续执行,结果尝试向空缓冲区取走数据。这时程序报错。
不难看出问题的所在:TC1被唤醒后,并未重新检查缓冲区是否为空,而是直接从断点继续执行了。而缓冲区在TC1休眠期间已经为空。signal()只是简单唤醒线程,也不做别的,因此需要手动在等待后继续检查所需要的条件。这称为Mesa语义。与之相对的是Hoare语义,即在线程苏醒后重新检查、许多OS实现的都是Mesa语义。
当然,在线程苏醒后重新检查所需条件也很简单:把代码中负责检验条件的if换成while。这就是第3点说的需要使用while的原因。有时候虽然不需要这样做,但是这样做肯定更加安全。
虚假唤醒(spurious wakeup),指的是线程在条件变量满足之前就先行返回。线程被虚假唤醒时,如果在while循环中,就会重新检测条件并继续等待。
6、但是,即便这样处理了,还会有另一个问题,原因是只有单个条件变量:
假设调度器依次运行TC1和TC2,它们检测到缓冲区为空后均进入休眠。而后生产者TP运行了,它一直运行到第二次尝试写入缓冲区。因为缓冲区只能存放一个整数,所以这一次已经无法写入,TP进入休眠。然后TC1苏醒后重新检查条件并继续,读取数据后却仅仅唤醒了TC2。后来继续TC1运行,检测到缓冲区为空,进入休眠。TC2继续,也因为缓冲区为空而休眠了。于是,三个线程都在休眠状态,没有线程来唤醒它们。
可见,作为消费者的线程应该只唤醒生产者而不是消费者。上述问题的解决方案也很简单:使用两个条件变量,以便根据不同条件变量的值来决定要唤醒哪一种线程。
7、总结一下生产者 / 消费者问题中导致出错的两种情况:
(1)线程唤醒后,未重新检查共享的缓冲区;
(2)唤醒了错误类型的线程。
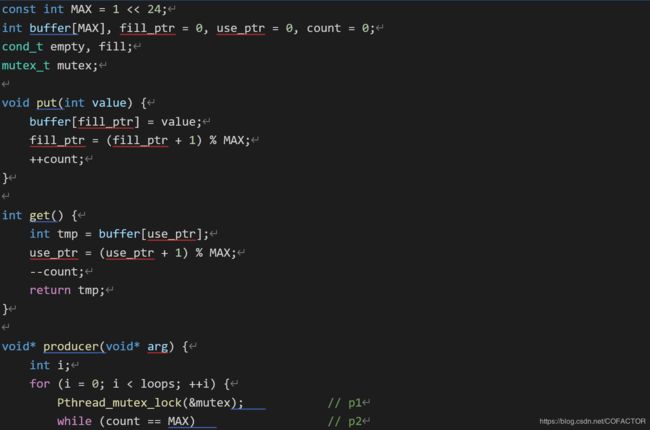
下面提供一份解决了这两个问题的代码(且缓冲区容量并非单个整型变量的长度):
#include
#include
const int MAX = 1 << 24;
int buffer[MAX], fill_ptr = 0, use_ptr = 0, count = 0;
cond_t empty, fill;
mutex_t mutex;
void put(int value) {
buffer[fill_ptr] = value;
fill_ptr = (fill_ptr + 1) % MAX;
++count;
}
int get() {
int tmp = buffer[use_ptr];
use_ptr = (use_ptr + 1) % MAX;
–count;
return tmp;
}
void* producer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
Pthread_mutex_lock(&mutex); // p1
while (count == MAX) // p2
Pthread_cond_wait(&empty, &mutex); // p3
put(i); // p4
Pthread_cond_signal(&fill); // p5
Pthread_mutex_unlock(&mutex); // p6
}
}
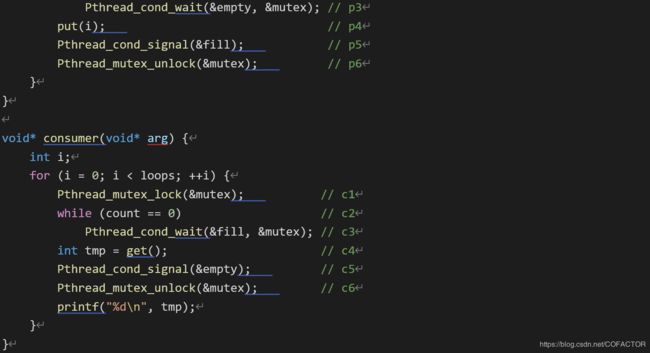
void* consumer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
Pthread_mutex_lock(&mutex); // c1
while (count == 0) // c2
Pthread_cond_wait(&fill, &mutex); // c3
int tmp = get(); // c4
Pthread_cond_signal(&empty); // c5
Pthread_mutex_unlock(&mutex); // c6
printf("%d\n", tmp);
}
}
8、我们再来看一些条件变量的应用例子。
在内存分配中,如果有线程请求分配内存,而可供分配的内存不足,则请求内存的线程需要等待;如果有线程释放内存,就要通知等待的线程。
比如线程A和B要求128字节和64字节的内存空间,但现在已经无空间可用;后来线程C释放了96 B的内存。显然,B才应该被唤醒。但是实际上被唤醒的线程可能是A,因为不知道哪个线程才是需要被唤醒的。
一个办法是唤醒所有线程,也就是调用pthread_cond_broadcast()或std:: condition_variable::notify_all()。
Lampson和Redell称这样的条件为覆盖条件(covering condition),因为覆盖了所有的有线程需要唤醒的情况。虽然该方法实现简单,但是对性能影响较大,因为许多不应唤醒的进程也被继续执行了。它们会检查条件,验证条件不满足,然后重新进入休眠。这个方法一般不常用。通常,如果你发现你的程序只有在把signal()改成broadcast的时候才能正常运行,那么你的程序很可能有bug。当然,像上面举的内存分配这样的例子中,这种方法可能是最直接的解决问题的方法。
9、信号量(semaphore)是一个整数。POSIX标准中,信号量支持两种操作:wait和post。Edsger W. Dijkstra把它们分别称为P和V(取的是两个荷兰语单词的开头),这两个操作合称PV操作。信号量的行为取决于初值,因此必须初始化。POSIX标准中的头文件
信号量的值为负时,其绝对值等于等待中的线程数。虽然这个值对用户不可见,但是这里还是把这个特性说一下,以便更好地明白信号量的功能。
10、锁也称为二进制信号量(binary semaphore)。下面是一个示例:
设信号量的初值为1。线程0先调用wait,信号量–1。由于信号量非负,因此线程0继续执行。线程0进入临界区之后被调度器打断,切换到线程1。线程1也调用一次wait,信号量变为–1,证明有线程可能进入了临界区,于是线程1等待。而后,切换至线程0。线程0离开临界区后调用一次post,信号量增加到0。因为线程1在等待,所以它被唤醒(进入就绪态)。而后调度器切换线程1运行。线程1从wait返回,继续执行。线程1调用post后,信号量增加到1,然后线程1从post返回。
11、看下面一段代码:
#include
#include
#include
sem_t s;
void* child(void* arg) {
puts(“child”);
sem_post(&s);
return nullptr;
}
int main() {
sem_init(&s, 0, X);
puts(“parent: begin”);
pthread_t c;
Pthread_create(&c, nullptr, child, nullptr);
sem_wait(&s);
puts(“parent: end”);
return 0;
}
预期的输出是:
parent: begin
child
parent: end
怎样使用信号量达到这个效果呢?这个信号量的初值要设为0。因为要分两种情况:
(1)假设子线程创建后没有立刻运行。这时候,父线程先调用了wait(在子线程调用post之前),等待子线程。为了在这个情况下能使父线程等待,信号量s的值必须不大于0。父线程调用wait后,s = –1,父线程进入睡眠。当子线程开始运行并调用post后,信号量变为0,父线程被唤醒,从wait返回。
(2)由于调度策略等原因,子线程在父线程调用wait之前就先调用了post(父线程调用wait在子线程调用post之后)。信号量增加1。为了使父线程在子线程调用post后就继续运行,信号量的值在这时需要为1,这样父线程调用wait后不至于等待。也就是说,信号量的初值只能是0。
通过这两个例子,我们归纳出信号量初值的一般情况:如果想用信号量作为锁,那么初值为1,使得一旦有一个线程进入临界区之后,其它进入该临界区的线程都要等待。如果主线程需要先让其创建的子线程运行一段时间,初值则为0。
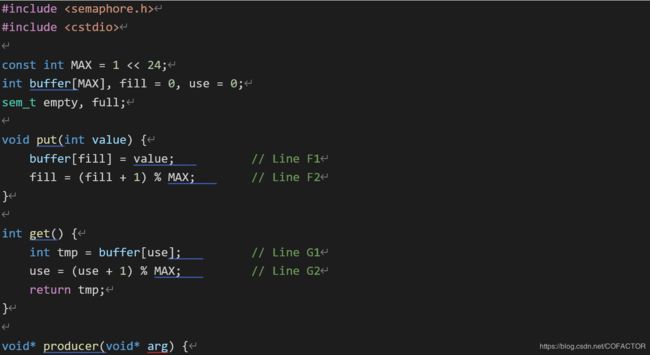
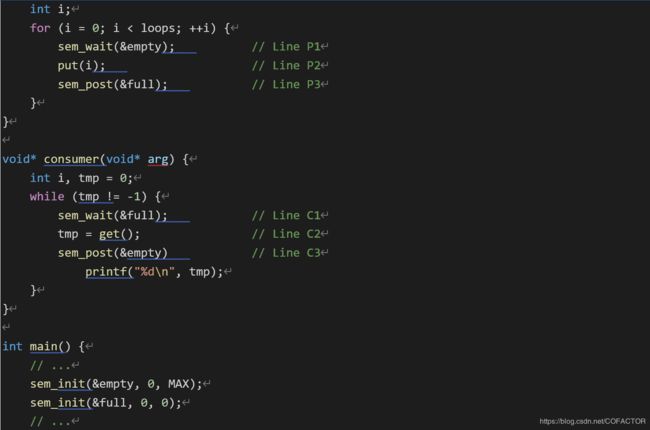
12、下面我们用两个信号量empty和full来解决生产者-消费者问题。它们分别代表缓冲区为空或已满。
看下面一段代码:
#include
#include
const int MAX = 1 << 24;
int buffer[MAX], fill = 0, use = 0;
sem_t empty, full;
void put(int value) {
buffer[fill] = value; // Line F1
fill = (fill + 1) % MAX; // Line F2
}
int get() {
int tmp = buffer[use]; // Line G1
use = (use + 1) % MAX; // Line G2
return tmp;
}
void* producer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
}
}
void* consumer(void* arg) {
int i, tmp = 0;
while (tmp != -1) {
sem_wait(&full); // Line C1
tmp = get(); // Line C2
sem_post(&empty) // Line C3
printf("%d\n", tmp);
}
}
int main() {
// …
sem_init(&empty, 0, MAX);
sem_init(&full, 0, 0);
// …
}
在这个例子中,生产者首先等待缓冲区清空,以便存入数据;消费者等待缓冲区有数据,然后取走。为了简便,先设MAX = 1,生产者和消费者线程各有1个,它们都被分配到同一个CPU核心上。
假设消费者先运行。消费者调用sem_wait(&full)。而full的初值是0,所以这时full = –1,阻塞消费者,并等待另一个进程执行sem_post(&full)。后来生产者开始运行,先执行sem_wait(&empty)。由于empty的值被初始化为1(即MAX),所以empty减小到0,生产者不等待,直接向缓冲区写入数据。生产者继续执行sem_post(&full),将full的值从–1变为0,唤醒消费者(消费者从阻塞态变为就绪态)。
接下来分两种情况讨论:
(1)假设生产者继续运行。它又会执行一次sem_wait(&empty),不过这次它会被阻塞,因为empty = 0,执行这个语句时变为–1。
(2)生产者被调度器打断,运行的线程切换至消费者。消费者从sem_wait(&full)返回,发现缓冲区不为空,取走数据。
可见,两种情况都符合我们的预期。但是,如果MAX不为1,怎么办?
下面我们提高检验标准。设MAX = 10,即缓冲区的容量为10;并且有多个生产者和多个消费者。这时候就会产生竞争条件了。假设两个生产者A和B都准备调用put函数,调度器决定先运行A,A往缓冲区填入一个数据。但是正当A填充数据完毕准备增加用于计数的整型变量fill的时候,调度器就将其打断了,并决定运行B。这时候B仍然向位置0写入数据,于是A写入的数据就被覆盖了。
因此,向缓冲区写入数据和增加计数器计数属于临界区。也就是说,条件变量并不能解决竞争条件,条件变量常常需要配合互斥锁一起使用。可见,条件变量和互斥锁解决的是不同场景的问题。
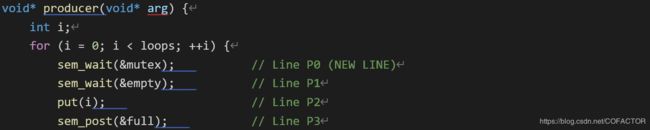
我们尝试引入一个互斥锁。声明互斥锁mutex,并把生产者和消费者的代码修改:
void* producer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
sem_wait(&mutex); // Line P0 (NEW LINE)
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
sem_post(&mutex); // Line P4 (NEW LINE)
}
}
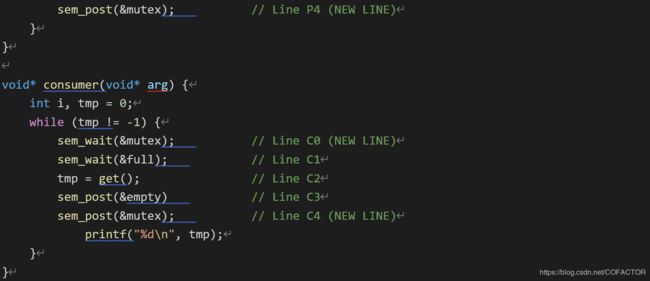
void* consumer(void* arg) {
int i, tmp = 0;
while (tmp != -1) {
sem_wait(&mutex); // Line C0 (NEW LINE)
sem_wait(&full); // Line C1
tmp = get(); // Line C2
sem_post(&empty) // Line C3
sem_post(&mutex); // Line C4 (NEW LINE)
printf("%d\n", tmp);
}
}
看上去很正确。但事实上,这会引发一个问题。
设生产者和消费者线程各1个,且消费者先运行。消费者上锁,调用sem_wait(&full)。这时缓冲区为空,因此消费者被阻塞,让出CPU。注意:这时候的锁仍然在消费者上。
生产者开始运行。在它执行第一句sem_wait(&mutex)的时候,由于锁已经被消费者锁上,生产者无法获得锁,因此也被阻塞,等待锁的释放。
就这样,消费者获得了锁,等待生产者向缓冲区写入内容后在信号量full上进行通知,以取得数据;生产者在等待消费者释放锁,然后向缓冲区写入数据。每一方都在互相等待另一方释放自己所需要的资源。这种情况被称为死锁(deadlock)。就好像两个人碰面时都在互相等对方先让开那般。
在本例中,引发死锁的原因是:一个线程过早上锁,结果在上锁后继续执行的过程中需要的资源正好得由另一个线程提供;但另一个线程在提供之前就要尝试上锁,然而失败了,必须等待这个线程先把锁释放。也就是说,上锁的时间过早了。
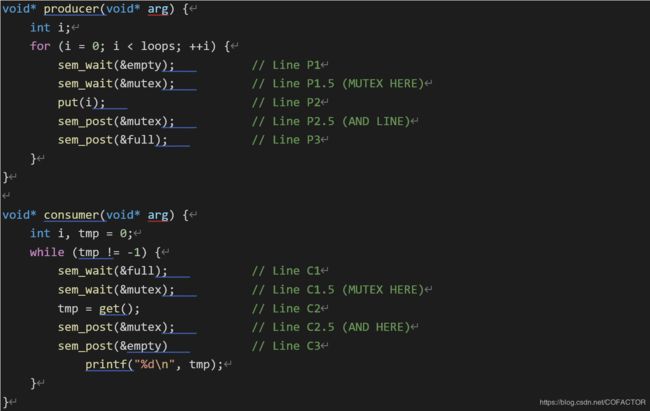
可见,避免死锁的一个办法是:缩小锁的操作范围。即只在马上进入临界区前才上锁,离开临界区后就要立刻释放锁。因此修改后的代码是这样的:
void* producer(void* arg) {
int i;
for (i = 0; i < loops; ++i) {
sem_wait(&empty); // Line P1
sem_wait(&mutex); // Line P1.5 (MUTEX HERE)
put(i); // Line P2
sem_post(&mutex); // Line P2.5 (AND LINE)
sem_post(&full); // Line P3
}
}
void* consumer(void* arg) {
int i, tmp = 0;
while (tmp != -1) {
sem_wait(&full); // Line C1
sem_wait(&mutex); // Line C1.5 (MUTEX HERE)
tmp = get(); // Line C2
sem_post(&mutex); // Line C2.5 (AND HERE)
sem_post(&empty) // Line C3
printf("%d\n", tmp);
}
}
当然,也可以把上锁和解锁的语句放在put()和get()内。
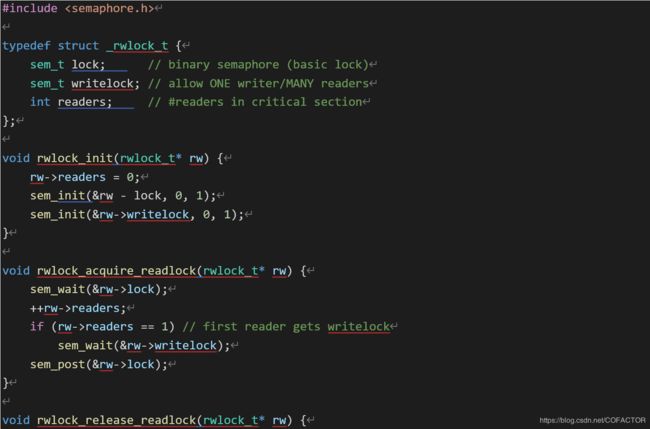
13、另一种常见的锁是读写锁,也称读者写者锁(reader-writer lock)、共享-互斥锁(shared-exclusive lock)、多读者-单写者锁、多读者锁、push lock,用于解决读写问题:读操作可以并发,但写操作必须互斥。
下面是读写锁的一种实现:
#include
typedef struct _rwlock_t {
sem_t lock; // binary semaphore (basic lock)
sem_t writelock; // allow ONE writer/MANY readers
int readers; // #readers in critical section
};
void rwlock_init(rwlock_t* rw) {
rw->readers = 0;
sem_init(&rw - lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void rwlock_acquire_readlock(rwlock_t* rw) {
sem_wait(&rw->lock);
++rw->readers;
if (rw->readers == 1) // first reader gets writelock
sem_wait(&rw->writelock);
sem_post(&rw->lock);
}
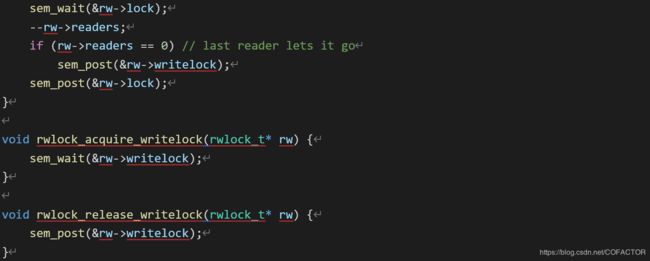
void rwlock_release_readlock(rwlock_t* rw) {
sem_wait(&rw->lock);
–rw->readers;
if (rw->readers == 0) // last reader lets it go
sem_post(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_acquire_writelock(rwlock_t* rw) {
sem_wait(&rw->writelock);
}
void rwlock_release_writelock(rwlock_t* rw) {
sem_post(&rw->writelock);
}
这个实现中,获得读锁的步骤是:获得作为锁的信号量lock,然后增加计数变量readers,后者用于追踪有多少线程在读取指定的数据。第一个获得读锁的线程也占用写锁,防止其它线程在读取的过程中写入数据,造成读取到“脏数据”(dirty data)。每个线程读取完毕后,都对lock进行一次post,于是正在读取的线程数就减去1。
在获得读锁和释放读锁之前用另外的锁进行控制,不但可以确保先请求获得读锁的进程先获得读锁,而且可以确保变量readers的值在获得读锁的函数结束后等于已经获得读锁的线程数。多线程的情形下,被自增变量的增量小于执行自增操作的总数的例子参见第7章的第5点和第18点。对释放读锁也有类似的道理。
线程获得写锁之前,必须先等待正在读取数据的线程结束读取。这可能导致负责写入的进程饥饿。由代码可见,在写入过程中,不允许任何线程对正在写入的数据(及其附近的数据)进行读取。至于锁住的数据的范围多大,则由程序员在编写需要读写数据的线程时决定。
需要注意的是,读写锁具有更多开销。
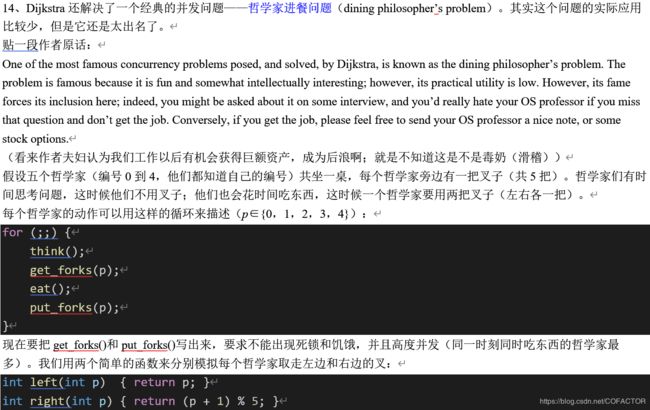
14、Dijkstra还解决了一个经典的并发问题——哲学家进餐问题(dining philosopher’s problem)。其实这个问题的实际应用比较少,但是它还是太出名了。
贴一段作者原话:
One of the most famous concurrency problems posed, and solved, by Dijkstra, is known as the dining philosopher’s problem. The problem is famous because it is fun and somewhat intellectually interesting; however, its practical utility is low. However, its fame forces its inclusion here; indeed, you might be asked about it on some interview, and you’d really hate your OS professor if you miss that question and don’t get the job. Conversely, if you get the job, please feel free to send your OS professor a nice note, or some stock options.
(看来作者夫妇认为我们工作以后有机会获得巨额资产,成为后浪啊;就是不知道这是不是毒奶(滑稽))
假设五个哲学家(编号0到4,他们都知道自己的编号)共坐一桌,每个哲学家旁边有一把叉子(共5把)。哲学家们有时间思考问题,这时候他们不用叉子;他们也会花时间吃东西,这时候一个哲学家要用两把叉子(左右各一把)。
每个哲学家的动作可以用这样的循环来描述(p∈{0,1,2,3,4}):
for (; {
think();
get_forks§;
eat();
put_forks§;
}
现在要把get_forks()和put_forks()写出来,要求不能出现死锁和饥饿,并且高度并发(同一时刻同时吃东西的哲学家最多)。我们用两个简单的函数来分别模拟每个哲学家取走左边和右边的叉:
int left(int p) { return p; }
int right(int p) { return (p + 1) % 5; }
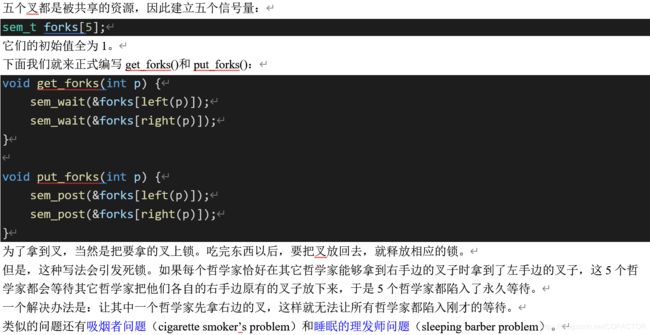
五个叉都是被共享的资源,因此建立五个信号量:
sem_t forks[5];
它们的初始值全为1。
下面我们就来正式编写get_forks()和put_forks():
void get_forks(int p) {
sem_wait(&forks[left§]);
sem_wait(&forks[right§]);
}
void put_forks(int p) {
sem_post(&forks[left§]);
sem_post(&forks[right§]);
}
为了拿到叉,当然是把要拿的叉上锁。吃完东西以后,要把叉放回去,就释放相应的锁。
但是,这种写法会引发死锁。如果每个哲学家恰好在其它哲学家能够拿到右手边的叉子时拿到了左手边的叉子,这5个哲学家都会等待其它哲学家把他们各自的右手边原有的叉子放下来,于是5个哲学家都陷入了永久等待。
一个解决办法是:让其中一个哲学家先拿右边的叉,这样就无法让所有哲学家都陷入刚才的等待。
类似的问题还有吸烟者问题(cigarette smoker’s problem)和睡眠的理发师问题(sleeping barber problem)。
15、信号量也能用来实现线程节流(thread throttling)。为了防止太多的线程同时请求大量资源,可以用信号量来限制同时并发的线程数。假设有数百个线程会请求庞大的内存,我们可以设定一个信号量,其初值为线程数限制;在它们请求内存的代码之前补充对该信号量的wait操作(不要在请求内存的语句之后补充post语句),这样一旦有超过限制数量的线程即将请求内存,多出来的这些线程就会先进入睡眠,以此限制这些进程占用内存的总量。




![]()



![]()



![]()


![]()



![]()
![]()


![]()