Redis——基础篇
Redis特性
将数据存储在缓存,可大大提高数据的IO性能,于是有了缓存的使用,随着对缓存的利用越来越多样化越来越充分,就有了各种缓存框架,Redis是其中较为优秀的,其特性如下几点:
- 更丰富的数据类型
- 进程内与跨进程
- 单机与分布式
- 功能丰富:持久化机制、过期策略
- 支持多种编程语言
- 高可用,集群化
Redis安装
我这里用centOS7的虚拟机来装,为什么,别问,问就是在玩docker。
获取安装包
wget http://download.redis.io/releases/redis-5.0.5.tar.gz什么?你告诉我你没有wget? 那就用yum -y install wget命令下载wget
解压
tar -zxvf redis-5.0.5.tar.gz安装gcc依赖
yum install gcc编译安装redis
cd redis-5.0.5
make MALLOC=libc将编译后的src目录下的二进制文件安装到/usr/local/bin
cd src
make install修改配置文件
默认配置文件是/home/soft/redis-5.0.5/redis.conf
后台启动
daemonize no
改成
daemonize yes下面一行必须改成 bind 0.0.0.0 或注释,否则只能在本机访问
bind 127.0.0.1如果需要密码访问,取消requirepass的注释
requirepass yourpassword使用指定配置文件启动Redis(这个命令建议配置alias)
/home/soft/redis-5.0.5/src/redis-server /home/soft/redis-5.0.5/redis.conf进入客户端(这个命令建议配置alias)
/home/soft/redis-5.0.5/src/redis-cli停止redis(在客户端中)
127.0.0.1:6379> shutdown完事儿啦!!!接下来就好好研究研究redis的基本数据类型吧。上手才能学的最快,嗯嗯。
基本操作
默认有16个库,可以在配置文件中修改,默认使用第一个db0
databases 16因为没有完全隔离,不像数据库的database,不适合把不同的库分配给不同的业务使用。
切换数据库
select 0清空当前数据库
flushdb清空所有数据库
flushallRedis是字典结构的存储方式,采用key-value存储。key和value的最大长度限制是512M。
设值
set king 123取值
get king查看所有键
keys *获取键总数
dbsize查看键是否存在
exists king删除键
del king重命名键
rename king chenxiansheng查看类型
type kingRedis基本数据类型
最基本也是最常用的数据类型就是String。set和get命令就是String的操作命令。
String字符串
存储类型
可以用来存储字符串、整数、浮点数。
操作命令
设置多个值
mset king 123 letme 321设置值,如果key存在,则设值不成功
setnx king 123
基于此特性,可用来实现分布式锁。用del key释放锁。
但如果释放锁的操作失败,导致其他节点永远获取不了锁,那么就引出了下面一个话题,给key加过期时间。
加过期时间可用expire命令
expire letme 5但如此一来,设值与加时间就不是一个原子操作了。可能导致,加锁后设置过期时间失败。所以可以使用多参数设值的方式
![]()
具体命令
set lock 1 EX 5 NX设值一个lock锁存在则失败,不存在则5秒后过期。
(整数)值递增、递减
incr king
incrby king 100
decr king
decrby king 100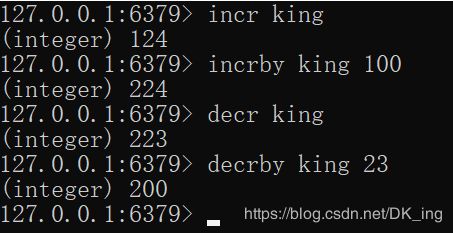
(浮点型)增量
set f 2.6
incrbyfloat f 7.4获取多个值
mget king f获取值长度
strlen king字符串追加内容
append king test获取指定范围的字符
getrange king 0 3存储原理
以set king test为例,因为Redis是KV的数据库,它是通过hashtable实现的。所以每个键值对都会有一个dictEntry(源码位置:dict.h),里面指向了key和value的指针。next指向下一个dictEntry。
typedef struct dictEntry {
void *key; /* key 关键字定义 */
union {
void *val;
uint64_t u64; /* value 定义 */
int64_t s64;
double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;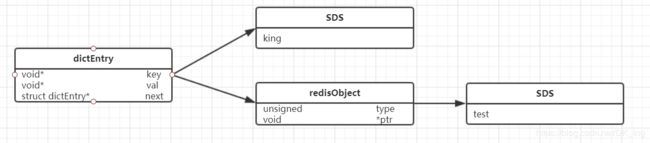
key是字符串,但是Redis没有直接使用C的字符数组,而是存储在自定义的SDS中。
value既不是直接作为字符串存储,也不是直接存储在SDS中,而是存储在redisObject中。实际上五种常用的数据类型的任何一种,都是通过redisObject来存储的。
redisObject
redisObject定义在src/server.h文件中。
typedef struct redisObject {
unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */
int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了*/
void *ptr; /* 指向对象实际的数据结构 */
} robj;可以使用type命令来查看对外的类型。
内部编码

可以看到,字符串类型的内部编码有三种:
- int,存储9个字节的长整型(long , 2^63-1)
- embstr,代表embstr格式的SDS(Simple Dynamic String 简单动态字符串),存储小于44个字节的字符串
- raw,存储大于44个字节的字符串
/* object.c */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 441、什么是SDS?
在3.2以后的版本中,SDS又有多种结构(sds.h):sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表2^5=32byte,2^8=256byte,2^16=65536byte=64KB,2^32byte=4GB。
/* sds.h */
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 当前字符数组的长度 */
uint8_t alloc; /*当前字符数组总共分配的内存大小 */
unsigned char flags; /* 当前字符数组的属性、用来标识到底是 sdshdr8 还是 sdshdr16 等 */
char buf[]; /* 字符串真正的值 */
};2、为什么Redis要用SDS实现字符串呢?
我们知道,C语言本身没有字符串类型(只能用字符串数组char[]实现)。
- 使用字符数组必须先给目标变量分配足够的空间,否则可能OutOfBound
- 如果要获取字符长度,必须遍历字符数组,时间复杂度O(n)。
- C字符串长度的变更会对字符数组做内存重分配。
- 通过从字符串开始到结尾碰到的第一个'\0'来标记字符串的结束,因此不能保存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全。
SDS的特点:
- 不用担心内存溢出问题,如果需要会对SDS进行扩容。
- 获取字符串长度时间复杂度为O(1),因为定义了len属性。
- 通过“空间预分配”(sdsMakeRoomFor)和“惰性空间释放”,防止多次重分配内存。
- 判断是否结束的标志是len属性(它同样以'\0'结尾是因为这样就可以使用C语言中的函数库操作字符串的函数了),可以包含'\0'。
3、embstr和raw的区别?
embstr的使用只分配一次内存空间(因为RedisObject和SDS是连续的),而raw需要分配两次内存空间(分别为RedisObject和SDS分配空间)。
因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个RedisObject和SDS都需要重新分配空间,因此Redis中的embstr实现为只读。
4、int和embstr什么时候转化为raw?
当int数据不再是整数,或大小超过了long的范围,自动转化为embstr。
5、未超过阈值情况下,为什么会转换成raw?
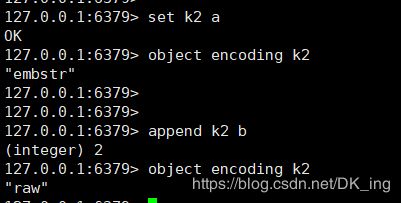
这是为什么呢?对于embstr来说,由于是只读的,因此在对embstr对象进行修改时,都会先转化为raw再进行修改。
因此,只要是修改embstr对象,修改后的对象一定时raw的,无论是否达到了44个字节。
6、当长度小于阈值时,会还原吗?
关于Redis内部编码的转换,都符合以下规律:编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存块编码转换(但是不包括重新set)。
7、为什么要对底层的数据结构进行一层包装呢?
通过封装,可以根据对象的类型动态地选择存储结构和可以使用的命令,实现节省空间和优化查询速度。
应用场景
缓存
String类型
例如:热点数据缓存(例如报表,明星出轨),对象缓存,全页缓存。
可以提升热点数据的访问速度。
数据共享分布式
String类型,因为Redis是分布式的独立服务,可以在多个应用之间共享
例如:分布式Session
org.springframework.session
spring-session-data-redis
分布式锁
String类型setnx方法,只有不存在时才能添加成功,返回true。
SET key value [EX seconds] [PX milliseconds] [NX|XX]
public Boolean getLock(Object lockObject){
jedisUtil = getJedisConnetion();
boolean flag = jedisUtil.setNX(lockObj, 1);
if(flag){
expire(locakObj,10);
}
return flag;
}
public void releaseLock(Object lockObject){
del(lockObj);
}全局ID
int类型,incrby,利用原子性
incrby userid 1000
(分库分表的场景,一次性拿一段)
计数器
int类型,incr方法
例如:文章的阅读量,微博点赞数,允许一定的延迟,先写入Redis再定时同步到数据库。
发散:这让我想到了我们项目的一个实际场景,多线程分页查询问题,如何保证数据不重复取。可以用计数器
限流
int类型,incr方法
以访问者的IP和其他信息作为key,访问一次增加一次计数,超过次数则返回false。
位统计
String类型的bitcount。
字符是以8位二进制存储的。
set k1 a
setbit k1 6 1
get k1
setbit k1 7 0
get k1哎哟 有点东西哦。
a对应的ASCII码是97,转换为二进制数据是01100001;
b对应的ASCII码是98,转换为二进制数据是01100010;
因为bit非常节省空间(1MB=8388608bit),可以用来做大量数据量的统计。
例如:在线用户统计,留存用户统计
setbit onlineusers 0 1
setbit onlineusers 1 1
setbit onlineusers 2 0支持按位与、按位或等操作。
BITOP AND destkey key [key ...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。
BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey 。
BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。
BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey 。如果一个对象的value有多个值的时候应该怎么存储?
例如用一个key存储一张表的数据。
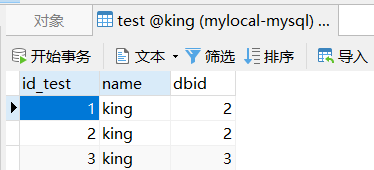
利用redis String数据类型,可以通过key分层的方式来实现,例如:
mset test:1:name king test:1:dbid 2在取值时,可以一次获取多个值:
mget test:1:name test:1:dbid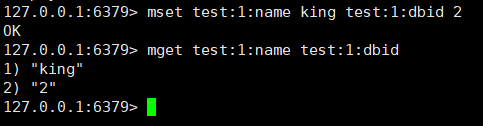
当然啦,这才看到String,这种方式费劲哦,key那么长 写起来都费劲,更别说占用空间问题咯。
Hash哈希
来吧,类型一出,结构先行。
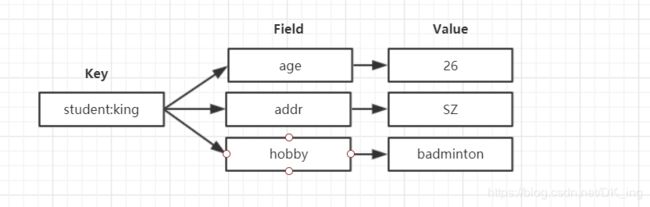
存储类型
包含键值对的无序散列表。value只能是字符串,不能嵌套其他类型。
同样是存储字符串,Hash与String的主要区别?
- 把所有相关的值聚集到一个key中,节省内存空间;
- 只使用一个key,减少key冲突;
- 当需要批量获取值的时候,只需要使用一个命令,减少内存/IO/CPU的消耗。
Hash不适合的场景:
- Field不能单独设置过期时间
- 没有bit操作
- 需要考虑数据量分布问题
操作命令
hset h1 f 6
hset h1 e 5
hmset h1 a 1 b 2 c 3 d 4hget h1 a
hmget h1 a b c d
hkeys h1
hvals h1
hgetall h1key操作
hexists h1 a
hdel h1 a
hlen h1存储(实现)原理
Redis的hash本身也是一个kv的结构,类似于Java中的HashMap。
外层的哈希只用到了hashtable。当存储hash数据类型时,我们把它叫做内层的哈希。内层的哈希底层可以使用两种数据结构实现:
ziplist:OBJ_ENCODING_ZIPLIST(压缩列表)
hashtable:OBJ_ENCODING_HT(哈希表)
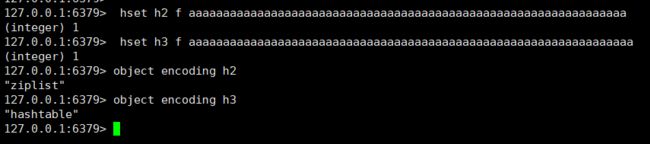
ziplist压缩列表
ziplist压缩列表是什么?
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time. However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist.
哈哈,来段英文。咳咳不是我写的,源码的解释来自于(ziplist.c的注释)
ziplist是经过特殊编码的双向链接,旨在提高内存效率。 它存储字符串和整数值,其中整数被编码为实际整数,而不是一系列字符。 它允许在O(1)时间在列表的任一侧进行推和弹出操作。 但是,由于每个操作都需要重新分配zip列表使用的内存,因此实际的复杂性与zip列表使用的内存量有关。
ziplist的内部结构?
ziplist.c源码第16行的注释:
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;编码 encoding(ziplist.c 源码第 204 行)
#define ZIP_STR_06B (0 << 6) //长度小于等于 63 字节
#define ZIP_STR_14B (1 << 6) //长度小于等于 16383 字节
#define ZIP_STR_32B (2 << 6) //长度小于等于 4294967295 字节
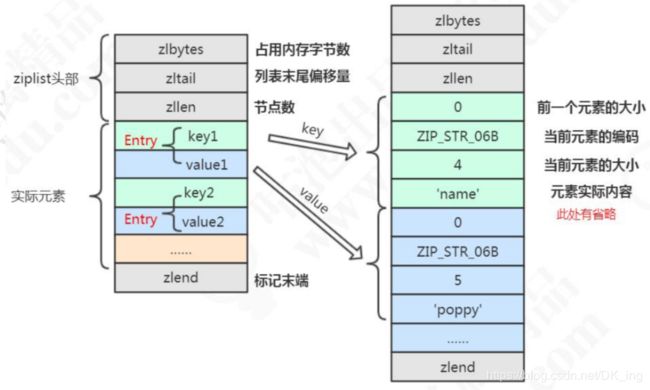
详细吧,这可不是我画滴。
什么时候使用ziplist存储?
当hash对象同时满足以下两个条件的时候,使用ziplist编码:
- 所有的键值对的键和值的字符串长度都小于等于64bytes;
- 哈希对象保存的键值对数量小于512个。

/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}一个哈希对象超过配置的阈值(键和值的长度>64bytes,键值对个数>512)时,会转换成哈希表(hashtable)。
hashtable(dict)
在redis中,hashtable被称为字典(dictionary),它是一个数组+链表的结构。前面我们知道了,Redis的KV结构是通过一个dictEntry来实现的。Redis又对dictEntry进行了多层的封装。
/* 源码位置:dict.h */
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;dictEntry放到了dictht(hashtable中):
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 掩码大小,用于计算索引值。总是等于 size-1 */
unsigned long used; /* 已有节点数 */
} dictht;ht放到了dict里面:
typedef struct dict {
dictType *type; /* 字典类型 */
void *privdata; /* 私有数据 */
dictht ht[2]; /* 一个字典有两个哈希表 */
long rehashidx; /* rehash 索引 */
unsigned long iterators; /* 当前正在使用的迭代器数量 */
} dict;从最底层到最顶层:dictEntry——dictht——dict——OBJ_ENCODING_HT
总结:哈希的存储结构
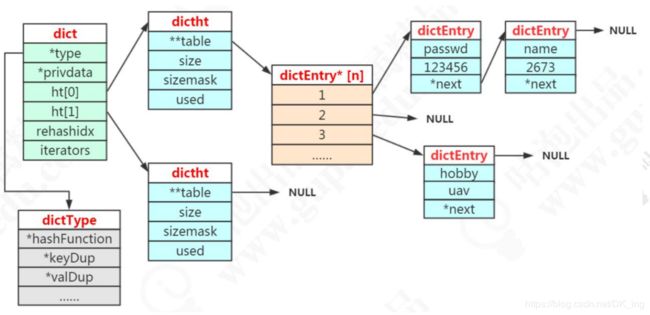
注意:dictht后面是NULL说明第二个ht还没用到。dictEntry*后面是NULL说明没有hash到这个地址。dictEntry后面是NULL说明没有发生哈希冲突。
为什么要定义两个哈希表呢?
redis的hash默认使用的是ht[0],ht[1]不会初始化和分配空间。
哈希表dictht是用链地址法来解决碰撞问题。在这种情况下,哈希表的性能取决于它的大小(size属性)和它所保存的节点的数量(userd属性)之间的比率:
- 比率在1:1时(一个哈希表ht只存储一个节点entry),哈希表的性能最好;
- 如果节点数量比哈希表的大小要大很多的话(这个比例用ratio表示,5表示平均一个ht存储5个entry),那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在。
在这种情况下需要扩容。Redis里面的这种操作叫做rehash。
rehash的步骤:
- 为字符ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对的数量。扩展:ht[1]的大小为第一个大于等于ht[0].used*2。
- 将所有的ht[0]上的节点rehash到ht[1]上,重新计算hash值和索引,然后放入指定的位置。
- 当ht[0]全部迁移到了ht[1]之后,释放ht[0]的空间,将ht[1]设置为ht[0]表,并创建新的ht[1],为下次rehash做准备。
什么时候触发扩容?
/* 源码位置:dict.c */
/* Using dictEnableResize() / dictDisableResize() we make possible to
* enable/disable resizing of the hash table as needed. This is very important
* for Redis, as we use copy-on-write and don't want to move too much memory
* around when there is a child performing saving operations.
*
* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio. */
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;ratio = used / size,已使用节点与字典大小的比例
dict_can_resize为 1 并且 dict_force_resize_ratio 已使用节点数和字典大小之间的比率超过 1:5,触发扩容
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
/* 扩容判断*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}扩容方法dictExpand
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}缩容
/* 源码:server.c */
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}应用场景
String
String可以做的事情,除了位运算Hash都可以做。
存储对象类型的数据
比如对象或者一张表的数据,比String节省了更多key的空间,也更加便于集中管理。
购物车
key:用户id;field:商品id;value:商品数量。
+1:hincr
-1:hdecr
删除:hdel
全选:hgetall
商品数:hlen
List列表
存储类型
存储有序的字符串(从左到右),元素可以重复。可以充当队列和栈的角色。

操作命令
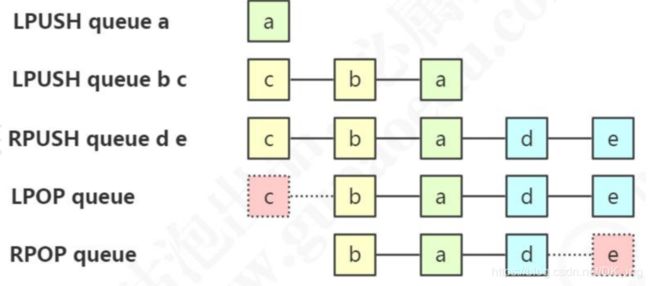
元素增减:
lpush queue a b c d
lpush queue x y z
rpush queue d e
lpop queue
blpop queue
brpop queue取值:
lindex queue 0
lrange queue 0 -1lpush与rpush简单理解就是,都是压栈操作,先入后出,lpush是正向压栈的话,rpush就是反向压栈:
存储(实现)原理
统一使用quicklist来存储。quicklist存储了一个双向链表,每个节点都是一个ziplist。
![]()
quicklist
quicklist(快速列表)是ziplist和linkedlist的结合体。
quicklist.h,head和tail指向双向列表的表头和表尾。
typedef struct quicklist {
quicklistNode *head; /* 指向双向列表的表头 */
quicklistNode *tail; /* 指向双向列表的表尾 */
unsigned long count; /* 所有的 ziplist 中一共存了多少个元素 */
unsigned long len; /* 双向链表的长度,node 的数量 */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* 压缩深度,0:不压缩; */
} quicklist;redis-conf相关参数:
| 参数 | 含义 |
| list-max-ziplist-size(fill) | 正数表示单个 ziplist 最多所包含的 entry 个数。 -1:4KB;-2:8KB;-3:16KB;-4:32KB;-5:64KB |
| list-compress-depth(compress) | 压缩深度,默认是 0。 1:首尾的 ziplist 不压缩;2:首尾第一第二个 ziplist 不压缩,以此类推 |
quicklistNode中的*zl指向一个ziplist,一个ziplist可以存放多个元素。
typedef struct quicklistNode {
struct quicklistNode *prev; /* 前一个节点 */
struct quicklistNode *next; /* 后一个节点 */
unsigned char *zl; /* 指向实际的 ziplist */
unsigned int sz; /* 当前 ziplist 占用多少字节 */
unsigned int count : 16; /* 当前 ziplist 中存储了多少个元素,占 16bit(下同),最大 65536 个 */
unsigned int encoding : 2; /* 是否采用了 LZF 压缩算法压缩节点,1:RAW 2:LZF */
unsigned int container : 2; /* 2:ziplist,未来可能支持其他结构存储 */
unsigned int recompress : 1; /* 当前 ziplist 是不是已经被解压出来作临时使用 */
unsigned int attempted_compress : 1; /* 测试用 */
unsigned int extra : 10; /* 预留给未来使用 */
} quicklistNode;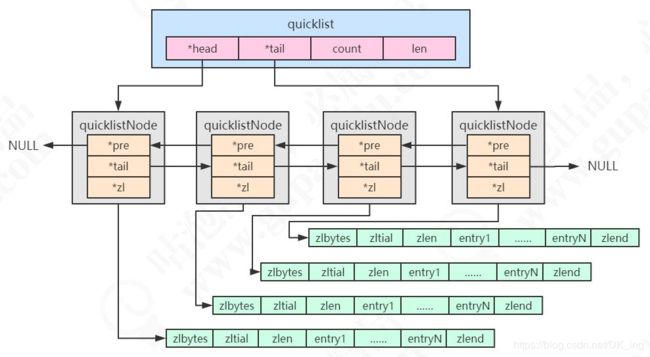
应用场景
用户消息时间线timeline
因为List是有序的,可以用来做用户时间线
消息队列
List提供了两个阻塞的弹出操作:BLPOP/BRPOP,可以设置超时时间。
BLPOP:BLPOP key1 timeout 弹出并获取列表的第一个元素,如果列表没有元素会阻塞列表知道等待超时或发现可弹出元素为止。
BRPOP:BRPOP key1 timeout 弹出并获取列表的最后一个元素,如果列表没有元素会阻塞列表知道等待超时或发现可弹出元素为止。
队列:FIFO:rpush blpop,左头右尾,右边进入队列,左边出队列。
栈:FILO:rpush brpop
Set集合
存储类型
String类型的无序集合,最大存储数量2^32-1(40亿左右)。
操作命令
#添加一个或多个元素
sadd myset a b c d e f g
#获取所有元素
smembers myset
#统计元素个数
scard myset
#随机获取一个元素
srandmember key
#随机弹出一个元素
spop myset
#移除一个或者多个元素
srem myset d e f g
#查看元素是否存在
sismember myset g存储(实现)原理
Redis用intset或hashtable存储set。如果元素都是整数类型,就用intset;如果不是整数类型,就用hashtable(数组+链表的存储结构)。
KV是怎么存储set的元素的呢?key就是元素的值,value为null。
如果元素超过512个,也会用hashtable存储。
应用场景
随机获取元素 spop myset
点赞、签到、打卡
商品标签
用tags:i5021来维护商品所有的标签
sadd tags:i5021 画面清晰
sadd tags:i5021 流畅
sadd tags:i5021 美观
商品筛选
#获取差集
sdiff set1 set2
#获取交集
sinter set1 set2
#获取并集
sunion set1 set2ZSet有序集合
存储类型
sorted set,有序的 set,每个元素有个 score。
score 相同时,按照 key 的 ASCII 码排序。
数据结构对比:
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序实现方式 |
| 列表list | 是 | 是 | 索引下标 |
| 集合set | 否 | 否 | 无 |
| 有序集合zset | 否 | 是 | 分值score |
操作命令
#添加元素
zadd myzset 10 java 20 php 30 ruby 40 python
#获取全部元素
zrange myzset 0 -1 withscores
zrevrange myzset 0 -1 withscores
#根据分值区间获取元素
zrangebyscore myzset 20 30
#移除元素,也可以根据 score rank删除
zrem myzset php ruby
#统计元素格式
zcard myzset
#分值递增
zincrby myzset 5 java
#根据分值统计个数
zcount myzset 20 60
#获取元素rank
zrank myzset java
#获取元素score
zscore myzset java
倒序reverse存储(实现)原理
同时满足以下条件时使用ziplist编码:
- 元素数量小于128个
- 所有member的长度都小于64字节
在ziplist的内部,按照score排序递增来存储。插入的时候要移动之后的数据。
超过阈值之后,使用skiplist+dict存储。
什么是skiplist?
有序链表如下:
![]()
为提高查找表的效率,提出了跳表的概念如下结构

假设每相邻两个节点增加一个指针,让指针指向下下个节点。如此连成新的链表,相较于原链表跨度更大,以此提高查找效率。
redis中t_zset.c源码中有一个zslRandomLevel的方法。
应用场景
排行榜
id为6001的新闻点击数加1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的15条:zrevrange hotNews:20190926 0 15 withscores
应用场景总结
- 缓存——提升热点数据的访问速度
- 共享数据——数据的存储和共享的问题
- 全局 ID —— 分布式全局 ID 的生成方案(分库分表)
- 分布式锁——进程间共享数据的原子操作保证在线用户统计和计数
- 队列、栈——跨进程的队列/栈
- 消息队列——异步解耦的消息机制
- 服务注册与发现 —— RPC 通信机制的服务协调中心(Dubbo 支持 Redis)
- 购物车
- 新浪/Twitter 用户消息时间线
- 抽奖逻辑(礼物、转发)
- 点赞、签到、打卡
- 商品标签
- 用户(商品)关注(推荐)模型
- 电商产品筛选
- 排行榜