Spring Cloud知识要点
Spring Cloud框架组件
服务发现——Netflix Eureka
断路器——Netflix Hystrix
服务网关——Netflix Zuul
声明式服务调用——Spring Cloud Fegiin
分布式配置——Spring Cloud Config
客服端负载均衡——Netflix Ribbon
消息驱动——Spring Cloud Stream
分布式服务追踪——Spring Cloud Sleuth
服务发现核心组件:Eureka
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
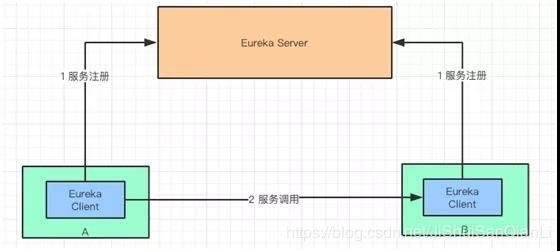
每个服务都会包含一个Eureka Client,其中会配置Eureka Server的信息,这样当服务启动的时候就能够把自己注册到 Eureka Server 中去了。
注册完毕以后,“A”服务通过 Eureka Client 从 Eureka Server 获取(Get Registry)服务“B”的信息。
由于,“A”服务调用“B”服务,所以“A”服务称之为“消费者”,“B”服务称之为“生产者”。
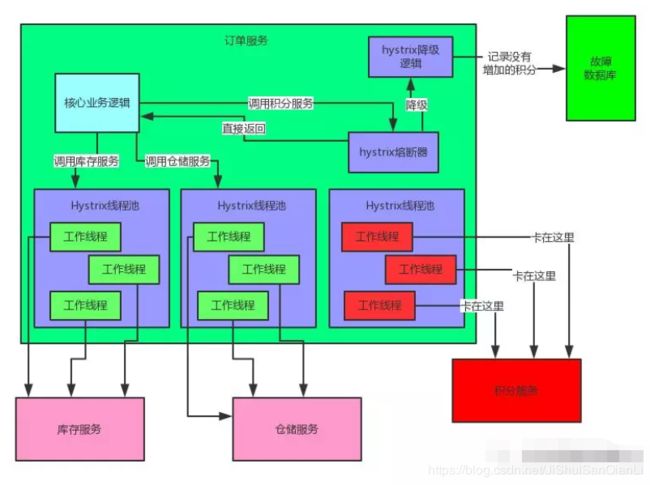
断路器Hystrix
Hystrix是隔离、熔断以及降级的一个框架。啥意思呢?说白了,Hystrix会搞很多个小小的线程池,比如订单服务请求库存服务是一个线程池,请求仓储服务是一个线程池,请求积分服务是一个线程池。每个线程池里的线程就仅仅用于请求那个服务。
这个时候如果别人请求订单服务,订单服务还是可以正常调用库存服务扣减库存,调用仓储服务通知发货。只不过调用积分服务的时候,每次都会报错。但是如果积分服务都挂了,每次调用都要去卡住几秒钟干啥呢?有意义吗?当然没有!所以我们直接对积分服务熔断,比如在5分钟内请求积分服务直接就返回了,不要去走网络请求卡住几秒钟,这个过程,就是所谓的熔断!
每次调用积分服务,你就在数据库里记录一条消息,说给某某用户增加了多少积分,因为积分服务挂了,导致没增加成功!这样等积分服务恢复了,你可以根据这些记录手工加一下积分。这个过程,就是所谓的降级。
声明式服务调用Fegin
那么问题来了,Feign是如何做到这么神奇的呢?很简单,Feign的一个关键机制就是使用了动态代理。
-
首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
-
接着你要是调用那个接口,本质就是会调用 Feign创建的动态代理,这是核心中的核心
-
Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址
-
最后针对这个地址,发起请求、解析响应
Netflix Zuul的功能和原理
鉴权——识别每个资源的身份验证需求并拒绝不满足这些需求的请求。
洞察和监控——在边缘跟踪有意义的数据和统计数据,以便为我们提供准确的生产视图。
流量转发——根据需要动态地将请求路由到不同的后端集群。
压力测试——逐步增加集群的流量,以评估性能。
减少负载——为每种类型的请求分配容量,并删除超过限制的请求。
静态响应处理——直接在边缘构建一些响应,而不是将它们转发到内部集群
多区域弹性——跨AWS区域路由请求,以使我们的ELB使用多样化,并使我们的优势更接近我们的成员
过滤器是Zuul业务逻辑的核心所在。它们能够执行非常大范围的操作,并且可以在请求-响应生命周期的不同部分运行
还有两种类型的过滤器:同步和异步。因为我们是在一个事件循环上运行的,所以千万不要阻塞过滤器。如果要阻塞,可以在一个异步过滤器中阻塞,在一个单独的threadpool上阻塞——否则可以使用同步过滤器。
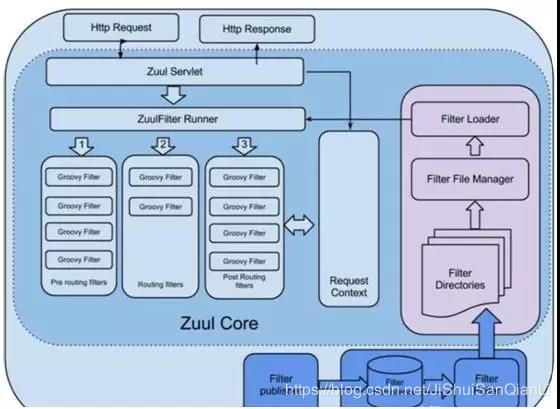 Zuul 内部工作原理图
Zuul 内部工作原理图
Zuul 收到 HTTP 请求以后,会通知 Zuul Servlet 处理,与此同时会生成一个 Request Context 用来记录请求的上下文信息,它会一直保持直到路由结束。
Zuul Filter Runner 接到 Zuul Servlet 的通知以后,会从 Request Context 中取请求的信息,并且交给 Filter Processer 处理,它会维护一套过滤和路由的规则,根据这些规则将请求发送到目标的服务。
配置中心实现配置自动刷新原理
Spring Cloud Bus会向外提供一个http接口,即图中的/bus/refresh。我们将这个接口配置到远程的git的webhook上,当git上的文件内容发生变动时,就会自动调用/bus-refresh接口。Bus就会通知config-server,config-server会发布更新消息到消息总线的消息队列中,其他服务订阅到该消息就会信息刷新,从而实现整个微服务进行自动刷新。
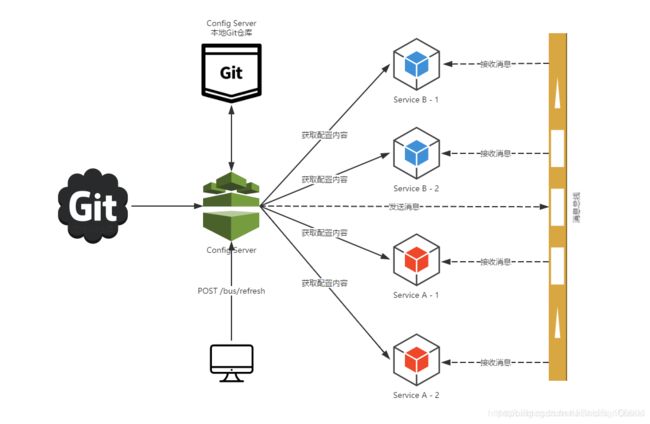
1、提交配置触发post请求给server端的bus/refresh接口
2、server端接收到请求并发送给Spring Cloud Bus总线
3、Spring Cloud Bus接到消息并通知给其它连接到总线的客户端
4、其它客户端接收到通知,请求Server端获取最新配置
5、全部客户端均获取到最新的配置
Ribbon内置负载均衡规则
| 内置负载均衡规则类 | 规则描述 |
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 注意:可以通过修改配置loadbalancer. (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的
|
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值(加权)。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。 |
| BestAvailableRule | 忽略哪些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| Retry | 重试机制的选择逻辑 |
Spring Cloud Stream的原理
对于消息系统而言一共分为两类:基于应用标准的 JMS、基于协议标准的 AMQP,在整个 SpringCloud 之中支持有 RabbitMQ、Kafka 组件的消息系统。利用 SpringCloudStream 可以实现更加方便的消息系统的整合处理
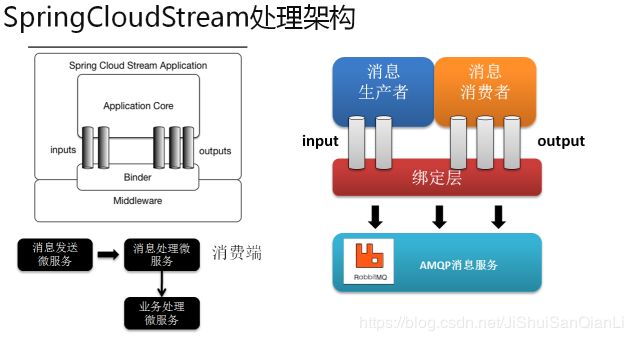
最底层是消息服务,中间层是绑定层,绑定层和底层的消息服务进行绑定,顶层是消息生产者和消息消费者,顶层可以向绑定层生产消息和和获取消息消费
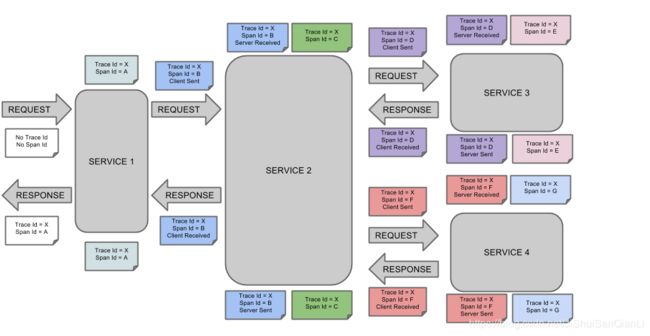
SpringCloud Sleuth
Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
Annotation:用来及时记录一个事件的存在,用于定义请求的开始和停止的一些核心注释是:
可视化Span和Trace将与Zipkin注释一起查看系统如下图:
参考文章:
https://m.php.cn/java-article-417097.html
https://mp.weixin.qq.com/s/wG4CTLORnvemkjUsZ7YP6Q
https://www.cnblogs.com/huangjuncong/p/9111604.html
https://mp.weixin.qq.com/s?__biz=MzU0OTk3ODQ3Ng==&mid=2247483712&idx=1&sn=4cd88761830428a2e485ac4c2cf120f9&chksm=fba6e943ccd16055344222ce9c794358e1a4a84fdf4263eaa7c91e9756597bd06e49f9b390cb&scene=21#wechat_redirect