Scrapy架构及部分源码解析
- Scrapy架构分析
- Spider及CrawlSpider源码分析
- Middlewares运作原理及部分源码分析
- Pipelines运作原理及部源码分析
Scrapy架构
Scrapy是用Twisted编写的,Twisted是一个流行的事件驱动的Python网络框架。因此,它使用非阻塞(也称为异步)代码实现并发。Scrapy官方文档中的系统架构图:
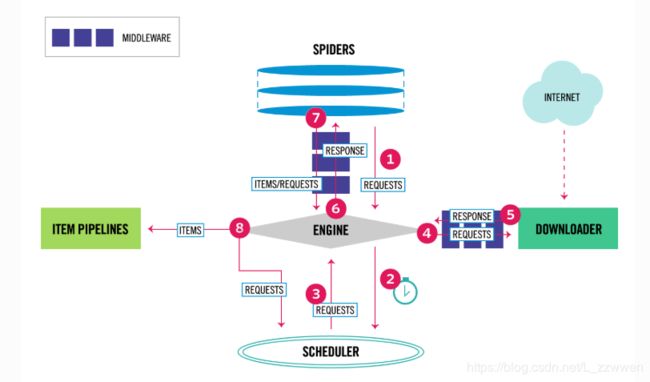
Scrapy中的数据流动由执行引擎控制,过程如下:
- Engine从Spider中获取爬取的初始Requests(请求);
- Engine在Scheduler中调度Requests,并请求下一个要爬取的Requests;
- Scheduler返回下一个Requests给Engine;
- Engine通过
Downloader Middlewares将请求发送给Downloader; - 一旦页面完成下载,Downloader将当前页面生成一个Response(响应),并通过
Downloader Middlewares将其发送到Engine; - Engine从Downloader接收Response,通过
Spider Middlewares处理并发送给Spider进行处理; - Spider处理Response,并通过
Spider Middlewares向Engine返回爬取的Item和新的Requests; - Engine将Spider返回的Item发送到Item Pipelines,然后将Spider返回的Requests发送到Scheduler,并请求可能的下一个Requests进行爬取;
- 重复以上步骤,直到Scheduler中没有更多的Requests。
Scrapy Engine
引擎(Engine)负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件;同时,引擎也是程序的入口。
调度器(Scheduler)
Scheduler从Engine接收请求(Resquest)并将它们入队,以便之后Engine请求它们时提供给Engine。
下载器(Downloader)
Downloader负责获取页面数据并提供给引擎,而后将网站的响应结果对象提供给Spider。
蜘蛛(Spiders)
Spider是用户编写用于分析响应(Response)结果并从中提取Item或跟进的URL的类。
数据管道(Item Pipeline)
Item Pipeline负责处理(如清理、验证、持久化等)被Spider提取出来的Item。
下载中间件(DownLoader Midderwares)
DownLoader Midderwares是位于Engine和Downloader之间的特定钩子,处理Engine传递给Downloader的Request以及Downloader传递给Engine的Response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy的功能。
Spider中间件(Spideer Midderwares)
Spider Midderwares是位于Engine和Spider之间的特定钩子,处理Spider的输入(Response)和输出(Item/Request)。
Spiders
Spider类定义了如何爬取网站,包括爬取得动作(是否跟进链接)以及如何从网页中提取结构化数据(Item)。总之,Spider是定义爬取的动作及分析网页的地方。
Spider爬取流程如下:
- 首先生成爬取的初始请求,然后指定一个回调函数;要执行的第一个请求是通过调用start_requests()方法获得的,该方法(默认)为start_urls中指定的URL生成请求,并将parse方法作为请求的回调函数;
- 在回调函数中,解析Response(网页相应),并返回提取数据的dict、item对象、Request对象或这些对象的iterable。Request还包含回调(默认parse,可通过callback指定),交由Scrapy下载,然后由指定的回调处理它们的响应;
- 在回调函数中,解析(css、xpath等)页面内容,并使用解析的数据生成Item;
- 最后,从spider返回的Item通常被持久化到数据库(在Pipeline中)或使用feed exports写入文件。
scrapy.Spider
Spider类提供了蜘蛛的最基本的行为与特性,其他蜘蛛都必须继承自该类(包括Scrapy自带的蜘蛛及用户自己编写的蜘蛛)。Spider并没有提供太多特殊的功能,其仅仅请求给定的start_urls/strat_requests,并根据返回的结果调用parse方法对返回结果深入爬取或提取目标数据。我们通过分析Spider代码来理解Spider的行为,源码如下:
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name = None
custom_settings = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
@property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {'spider': self})
def log(self, message, level=logging.DEBUG, **kw):
"""Log the given message at the given log level
This helper wraps a log call to the logger within the spider, but you
can use it directly (e.g. Spider.logger.info('msg')) or use any other
Python logger too.
"""
self.logger.log(level, message, **kw)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider
def set_crawler(self, crawler):
warnings.warn("set_crawler is deprecated, instantiate and bound the "
"spider to this crawler with from_crawler method "
"instead.",
category=ScrapyDeprecationWarning, stacklevel=2)
assert not hasattr(self, 'crawler'), "Spider already bounded to a " \
"crawler"
self._set_crawler(crawler)
def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
def parse(self, response):
raise NotImplementedError('{}.parse callback is not defined'.format(self.__class__.__name__))
@classmethod
def update_settings(cls, settings):
settings.setdict(cls.custom_settings or {}, priority='spider')
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
@staticmethod
def close(spider, reason):
closed = getattr(spider, 'closed', None)
if callable(closed):
return closed(reason)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
start_requests(self)
我们着重看一下start_requests方法,Spider类的入口方法就是start_requests,此方法会向start_urls发起请求(Request),请求的响应(Response)会传给回调(callback)函数,默认是parse方法。
start_requests函数非常简单,它首先判断make_requests_from_url方法是否被重载,如果没有被重载,直接向start_urls发起Request;如果被重载,就通过make_requests_from_url向start_urls发起Request。
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
注意:make_requests_from_url方法已被弃用,不赞成使用。
parse(self, response)
def parse(self, response):
raise NotImplementedError('{}.parse callback is not defined'.format(self.__class__.__name__))
parse方法是start_requests方法的默认回调函数,它非常重要,因为它是被Downloader在发出Request并获取到Response后调用的方法接口。此方法会抛出一个尚未实现的异常,意味着我们继承Spider类后一定要重写此方法。
注意:当parse方法返回Request对象时,Scrapy会重新将Request发给Downloader,待Downloader返回Response后重新回到当前的parse方法,或者执行Request构造函数中传入的回调函数。只有当parse方法返回的是爬取得Item数据,才会流动到下一环节(Pipeline)进行处理。
Spider参考表
| 熟悉 | 说明 |
|---|---|
| name | spider名称,必须唯一。 |
| allowed_domains | spider允许爬取的域。 |
| start_urls | URL列表,当没有指定特定的URL时,spider将进行爬取的URL列表。 |
| custom_settings | 运行spider时将从全局配置(settings.py)中覆盖的设置字典。必须将其定义为类属性,因为在实例化之前更新了设置。 |
| crawler | from_crawler()初始化类后,此属性由类方法设置,并链接Crawler到此spider实例绑定到的对象。 |
| settings | 运行此蜘蛛的配置,这是一个Settings实例。 |
from_crawler(crawler,*args,**kwargs) |
这是Scrapy用于创建蜘蛛的类方法,此方法在新实例中设置crawler和settings属性。 |
start_requests() |
spider爬取得入口函数,该方法必须返回一个带有初始Request的可迭代列表;默认实现是使用start_urls的URL生成的Request。 |
parse(response) |
这是Scrapy在处理未指定回调函数的请求的响应时使用的默认回调。 |
closed(reason) |
蜘蛛关闭时调用。此方法提供了一个代替调用signals.connect()来监听spider_closed信号的快捷方式。 |
Generic Spider
Scrapy提供了4个通用的spider来处理一些普遍的爬取任务:
- XMLFeedSpider:用于爬取符合XML文档格式的spider基类;
- CSVFeedSpider:用于爬取CSV文件的spider;
- CrawlSpider:用于进行间接式递进爬取得spider;
- SitemapSpider:从Sitemap.xml文件跟随进入网站进行深度爬网的spider。
学习的途径就是阅读源码,而Python的代码都是开源的,我们很容易就可以查看Generic Spider类的源代码;接下来,我会对CrawlSpider源码进行分析,而其他三种Generic Spider都大同小异,自己查看源码及官方文档即可。
scrapy.spiders.CrawlSpider
CrawlSpider是爬取一般网站常用的spider,其定义了一些规则(rule)来提供跟进link的方便机制。
除了从Spider继承过来的(您必须提供的)属性外,其提供了一个新的属性:
-
rules一个包含一个(或多个)
Rule对象的列表。 每个Rule对爬取网站的动作定义了特定表现。 如果多个rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
CrawlSpider源码如下:
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
def _build_request(self, rule, link):
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=rule, link_text=link.text)
return r
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
links = rule.process_links(links)
for link in links:
seen.add(link)
r = self._build_request(n, link)
yield rule.process_request(r)
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
def _parse_response(self, response, callback, cb_kwargs, follow=True):
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
if follow and self._follow_links:
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, six.string_types):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(CrawlSpider, cls).from_crawler(crawler, *args, **kwargs)
spider._follow_links = crawler.settings.getbool(
'CRAWLSPIDER_FOLLOW_LINKS', True)
return spider
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
parse(self, response)
前面Spider类中我们说到parse方法非常重要,且我们必须要重写它。但在CrawlSpider中,parse函数已经被CrawlSpider实现(占用)了,我们不能再重写parse方法。如下,CrawlSpider类中parse方法返回了_parse_response的调用:
- response:Response
- parse_start_url:回调函数
- cb_kwargs:cb_kwargs是一个包含要传递给回调函数的关键字参数的dict。
- follow:follow是一个布尔值,指定是否应该从使用此规则提取的每个响应中跟踪链接,默认为True。
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
_parse_response(self, response, callback, cb_kwargs, follow=True)
理解_parse_response方法是理解CrawlSpider的核心。
def _parse_response(self, response, callback, cb_kwargs, follow=True):
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
if follow and self._follow_links:
for request_or_item in self._requests_to_follow(response):
yield request_or_item
首先,_parse_response调用callback(即parse_start_url)和process_results方法得到cb_res(response中提取的信息)并迭代返回,两函数如下:这两个函数是可以重载的,如果没有重写,意味_parse_response前一部分代码啥也没干。
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
然后,if follow and self._follow_links,判断是否遵循rules规则,这意味着我们可以从两个地方设置;follow和self._follow_links都默认为True,self._follow_links如下:它是Settings实例中CRAWLSPIDER_FOLLOW_LINKS属性值。
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
如果都为True,那么就会调用_requests_to_follow函数,yield一个Item或一个Request。
_requests_to_follow((self, response)
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
links = rule.process_links(links)
for link in links:
seen.add(link)
r = self._build_request(n, link)
yield rule.process_request(r)
此函数会从self.rules属性中提取出link(链接,会去重处理),然后将link经过process_links(如果有)处理。process_links是Rule对象的一个属性,可以定义此属性以实现link的预处理(比如域名的拼接、过滤URL等)。
接着调用_build_request方法构造Request请求,最后将Request经过process_request处理后返回。process_request属性跟process_links一样,都是Rule对象的属性,但process_request是对构造的Request进行预处理。
def _build_request(self, rule, link):
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=rule, link_text=link.text)
return r
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
_build_request方法的回调函数是_response_downloaded,CrawlSpider又将请求封装了一层,Request的相应(Response)会交给_response_downloaded方法,_response_downloaded方法再交给rule.callback进行处理。rule.callback是Rule对象的回调函数,需要我们自己定义。
parse_start_url(response)
此方法是CrawlSpider可重写的方法,作用有点像Spider类的parse方法。parse_start_url方法为start_urls Request的Response调用,允许解析初始响应,并且必须返回Item对象、Request对象或包含其中任何一个的iterable。
Rule
class Rule(object):
def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=identity):
self.link_extractor = link_extractor
self.callback = callback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links
self.process_request = process_request
if follow is None:
self.follow = False if callback else True
else:
self.follow = follow
- link_extractor:一个LinkExtractor对象,它定义如何从每个已爬页面中提取链接。
- callback:一个可调用对象或一个字符串(在这种情况下,将使用具有该名称的spider对象的方法),为使用指定的链接提取器提取的每个链接调用。
- cb_kwargs :一个包含要传递给回调函数的关键字参数的dict。
- follow:布尔值,指定是否应该从使用此规则提取的每个响应中跟踪链接。
- process_links:一个可调用对象或一个字符串(在这种情况下,将使用来自具有该名称的spider对象的方法),将使用指定的链接提取器为从每个响应中提取的每个链接列表调用该函数;主要用于过滤。
- process_request是一个可调用对象或一个字符串(在这种情况下,将使用来自具有该名称的spider对象的方法),将为此规则提取的每个Request调用它。
CrawlSpider示例
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['http://www.lagou.com/']
rules = (
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = scrapy.Item()
item['name'] = response.xpath('//td[@id="job_name"]/text()').get()
...
return item
这个spider会开始对example.com的主页进行爬取,收集jobs链接,然后用parse_item方法分析jobs链接响应。对于每个jobs响应,将使用xpath或css从HTML中提取一些数据,并用它填充为一个Item。
Downloader Middlewares
Downloader Middlewares是Scrapy的请求/响应处理的钩子框架。它是一个轻量级的低级系统,用于全局改变Scrapy的请求和响应。
这一节,分析Downloader Middlewares(In scrapy.downloadermiddlewares packet),理解Downloader Middlewares运行原理,以便更好的实现自己所需的Scarpy扩展。
注意:结合Scrapy架构图阅读Middlewares源码会更容易理解。
Downloader Middlewares概览
每个Downloader Middleware都是一个python类,它定义了下面的一个或多个方法。其中Downloader Middlewares的主要入口点是from_crawler类方法,它接收一个crawler实例。
-
from_crawler(cls, crawler)
参数crawler,Crawler对象实例。
此方法如果存在,则调用这个类方法从
Crawler创建中间件实例,它必须返回中间件的新实例。Crawler对象提供对所有核心组件(如设置和信号)的访问,它是中间件访问scrapy核心组件并将其功能连接的一种方式。 -
process_request(self, request, spider)
对于通过Downloader Middlewares的每个Request,都会调用此方法;如果我们想根据自己的业务需求实现自己的Downloader Middlewares,可以在此函数中添加逻辑。
process_request()应该返回None、返回一个Response对象,返回一个Request对象,或者raise IgnoreRequest。- 如果它返回
None,scrapy将继续处理该请求,执行其他中间件,直到最后调用适当的下载处理程序执行请求(并下载其响应)。 - 如果它返回一个
Response对象,那么scrapy就不需要调用任何其他的process_request()、process_exception()方法或相应的下载函数;它将返回该Response,且每次Response都会调用已安装中间件的process_response()方法。 - 如果它返回一个
Request对象,Scrapy将停止调用process_request方法并重新调度返回的Request。执行新返回的Request后,将在下载的Response上调用相应的中间件链。 - 如果它引发
IgnoreRequest异常,将process_exception()调用已安装的下载中间件的方法。如果它们都不处理异常,则调用request的errback函数(Request.errback)。如果没有代码处理引发的异常,则会忽略它并且不会记录。
- 如果它返回
-
process_response(self, request, response, spider)
对于通过Downloader Middlewares的每个Response,都会调用此方法;
process_response()应该返回
Response对象、返回Request对象或raise IgnoreRequest异常。- 如果它返回一个
Response对象,那么该Response将继续使用链中(下载中间件链)下一个中间件的process_response()进行处理。 - 如果它返回一个
Request对象,那么中间件链将停止,返回的Request将被重新安排,以便将来下载。与process_request()返回Request的行为相同。 - 如果它引发
IgnoreRequest异常,则调用request的errback函数(Request.errback)。如果没有代码处理引发的异常,则忽略该异常,不记录该异常。
- 如果它返回一个
-
process_exception(request, exception, spider)
当下载处理程序或process_request()引发异常(包括IgnoreRequest异常)时,scrapy将调用process_exception()方法。
process_exception()应返回
None、Response对象或Request对象。- 如果返回
None,scrapy将继续处理此异常,执行已安装中间件的任何其他process_exception()方法。 - 如果返回
Response对象,则启动已安装中间件的process_response()方法链,scrapy将不必调用中间件的任何其他process_exception()方法。 - 如果它返回一个
Request对象,则返回的请求将被重新安排,以便将来下载。这将停止中间件的process_exception()方法的执行。
- 如果返回
DownloadTimeoutMiddleware
scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware
from scrapy import signals
class DownloadTimeoutMiddleware(object):
def __init__(self, timeout=180):
self._timeout = timeout
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings.getfloat('DOWNLOAD_TIMEOUT'))
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self._timeout = getattr(spider, 'download_timeout', self._timeout)
def process_request(self, request, spider):
if self._timeout:
request.meta.setdefault('download_timeout', self._timeout)
此内置DownloaderMiddleware使用from_crawler类方法获取全局配置中DOWNLOAD_TIMEOUT的值初始化DownloadTimeoutMiddleware实例,并将signals.spider_opened信号量(spider启动)绑定到spider_opened方法,优先使用spider中设置的download_timeout值作为下载延迟;process_request则用于将下载延迟值设置到Request中。
UserAgentMiddleware
scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
UserAgentMiddleware与DownloaderMiddleware代码完全一致。
自定义Downloader Middlewares
随机UA
from scrapy import signals
class RandomUserAgentDownloaderMiddleware(object):
"""从settings.py文件中获取USER_AGENT_LIST作为随机UA列表"""
def __init__(self, ua_list):
self.user_agent_list = ua_list
@classmethod
def from_crawler(cls, crawler):
return cls(crawlerua_list.settings["USER_AGENT_LIST"])
def process_request(self, request, spider):
if self.user_agent_list:
from random import choice
request.headers.setdefault('User-Agent', choice(self.user_agent_list))
注意:
- 如果需要使用自定义的UA,则需要将默认UA关闭(将其在DOWNLOADER_MIDDLEWARES中置为None)。
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
- 一种更高效的做法是使用第三方库(维护了大量的UA列表),参考github fake-useragent项目。
IP代理池
网站都有反爬虫策略,一个比较典型的就是“短时间内IP访问流量多大”,意思就是一个IP在短时间内发生了大量访问行为;如果被检测到有入侵行为,则可能被限制短时间无法再次访问网站。IP代理池就可以解决这个问题,使用IP代理池去访问目标网站,每次访问IP可能都不同,也就不至于某一个IP流量过大。
注意:
- IP代理与随机UA实现类似,这里就不给出代码;
- 可以参考第三方IP代理库,如github scrapy-proxies & github scrapy-crawlera
Spider Middlewares
每个Spider Middlewares都是一个Python类,它定义了下面定义的一个或多个方法,与Downloader Middlewares一致,其主要入口点也是from_crawler类方法,它接收一个Crawler实例。
注意:结合Scrapy架构图阅读Middlewares源码会更容易理解。
-
from_crawler(cls, crawler)
参数crawler,Crawler对象实例。
此方法如果存在,则调用这个类方法从
Crawler创建中间件实例,它必须返回中间件的新实例。Crawler对象提供对所有核心组件(如设置和信号)的访问,它是中间件访问scrapy核心组件并将其功能连接的一种方式。 -
process_spider_input(self, response,spider)
对于通过Spider Middlewares进入Spider进行处理的每个响应,都会调用此方法。
process_spider_input()应返回
None或引发异常。- 如果它返回
None,scrapy将继续处理此响应,执行所有其他spider middlewares,直到最后将响应提交给spider进行处理。 - 如果它引发了一个异常,scrapy将不会调用任何其他的spider middlewares的 process_spider_input();它将调用request.errback(如果有),否则它将调用process_spider_exception()链。errback的输出被链接回另一个方向,以便process_spider_output()处理它,或者如果它引发了异常,则调用process_spider_exception()。
- 如果它返回
-
process_spider_output(self, response, result, spider)
在处理完响应(response)后,调用此方法,并返回spider返回的结果。
参数result:spider返回的结果——Request、dict或item对象的iterable
process_spider_output()必须返回可迭代的Request、dict或item对象。
-
process_spider_exception(self, response,exception, spider)
当spider或process_spider_output()方法引发异常时,调用此方法。
process_spider_exception()应返回None或可迭代的Request、dict或item对象。
- 如果返回None,scrapy将继续处理这个异常,执行任何其他process_spider_exception(),直到异常到达Engine。
- 如果它返回一个iterable,那么从下一个spider middleware开始调用process_spider_output(),并且不会再调用其他process_spider_exception()。
-
process_start_requests(self, start_requests,spider)
参数start_requests:起始请求(可迭代的Request对象)
这个方法是spider发起起始请求时调用的,它的工作原理与process_spider_output()方法类似,只是它没有关联的响应,必须只返回请求。
它接收一个iterable(在start_requests参数中),并且必须返回另一个可迭代的Request对象。
HttpErrorMiddleware
scrapy.spidermiddlewares.httperror.HttpErrorMiddleware
此Middleware用于过滤掉不成功的(错误的)HTTP响应,这样spider就不必处理它们了;如果需要处理不成功的HTTP响应,则会增加开销,消耗更多的资源,并使spider逻辑更加复杂。
class HttpErrorMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def __init__(self, settings):
self.handle_httpstatus_all = settings.getbool('HTTPERROR_ALLOW_ALL')
self.handle_httpstatus_list = settings.getlist('HTTPERROR_ALLOWED_CODES')
def process_spider_input(self, response, spider):
if 200 <= response.status < 300: # common case
return
meta = response.meta
if 'handle_httpstatus_all' in meta:
return
if 'handle_httpstatus_list' in meta:
allowed_statuses = meta['handle_httpstatus_list']
elif self.handle_httpstatus_all:
return
else:
allowed_statuses = getattr(spider, 'handle_httpstatus_list', self.handle_httpstatus_list)
if response.status in allowed_statuses:
return
raise HttpError(response, 'Ignoring non-200 response')
def process_spider_exception(self, response, exception, spider):
if isinstance(exception, HttpError):
spider.crawler.stats.inc_value('httperror/response_ignored_count')
spider.crawler.stats.inc_value(
'httperror/response_ignored_status_count/%s' % response.status
)
logger.info(
"Ignoring response %(response)r: HTTP status code is not handled or not allowed",
{'response': response}, extra={'spider': spider},
)
return []
HttpErrorMiddleware实例会从Settings对象中取HTTPERROR_ALLOW_ALL和HTTPERROR_ALLOWED_CODES的值:
HTTPERROR_ALLOW_ALL:布尔值;如果为True代表传递所有响应,无论其状态代码如何;默认为False。HTTPERROR_ALLOWED_CODES:默认[];传递包含在此列表中的非200状态代码的所有响应。
在HttpErrorMiddleware.process_spider_input方法中,主要是对Response对象状态码进行过滤及判断过滤设置:
def process_spider_input(self, response, spider):
if 200 <= response.status < 300: # common case
return
meta = response.meta
if 'handle_httpstatus_all' in meta:
return
if 'handle_httpstatus_list' in meta:
allowed_statuses = meta['handle_httpstatus_list']
elif self.handle_httpstatus_all:
return
else:
allowed_statuses = getattr(spider, 'handle_httpstatus_list', self.handle_httpstatus_list)
if response.status in allowed_statuses:
return
raise HttpError(response, 'Ignoring non-200 response')
-
首先,属于20X的HTTP相应会直接传递(即
return None); -
其次,如果在meta中设置了
handle_httpstatus_all及handle_httpstatus_list,也会进行过滤传递; -
然后,判断
self.handle_httpstatus_all(即Settings中的HTTPERROR_ALLOW_ALL); -
最后
allowed_statuses = getattr(spider, 'handle_httpstatus_list', self.handle_httpstatus_list),获取spider中的handle_httpstatus_list属性,如果没有则默认为self.handle_httpstatus_list(即Settings中的HTTPERROR_ALLOWED_CODES)class MySpider(CrawlSpider): """在spider中设置handle_httpstatus_list可起到HTTPERROR_ALLOWED_CODES一样的作用,且handle_httpstatus_list值优先""" handle_httpstatus_list = [404]
如果Resopnse状态码符合以上任意条件,都会被传递给spider;否则,将抛出HttpError异常,交由process_spider_exception方法进行处理。
对于process_spider_exception方法,它只会处理HttpError异常——数据收集器会进行数据收集(将错误响应数+1),
pider.crawler.stats.inc_value('httperror/response_ignored_count')
spider.crawler.stats.inc_value(
'httperror/response_ignored_status_count/%s' % response.status
)
然后记录该信息,返回[](可迭代对象)scrapy将不再处理该异常。
UrlLengthMiddleware
class UrlLengthMiddleware(object):
def __init__(self, maxlength):
self.maxlength = maxlength
@classmethod
def from_settings(cls, settings):
maxlength = settings.getint('URLLENGTH_LIMIT')
if not maxlength:
raise NotConfigured
return cls(maxlength)
def process_spider_output(self, response, result, spider):
def _filter(request):
if isinstance(request, Request) and len(request.url) > self.maxlength:
logger.debug("Ignoring link (url length > %(maxlength)d): %(url)s ",
{'maxlength': self.maxlength, 'url': request.url},
extra={'spider': spider})
return False
else:
return True
return (r for r in result or () if _filter(r))
from_settings(cls, settings)
此类方法与from_crawler(cls, crawler)类方法有点类似,都是用于创建中间件实例:
- from_crawler使用Crawler对象(
scrapy.crawler.Crawler)创建中间件实例; - from_settings使用Settings对象(
scrapy.settings.Settings)创建中间件实例。
解析UrlLengthMiddleware
你会发现,这个Spider Middleware(UrlLengthMiddleware)非常简单,process_spider_output方法将spider返回的结果(Request、Item or Other)进行过滤:将其中的Request且请求的url长度小于设置的maxlength返回。
Item Pipelines
一个Item被sipder抓取之后,它被发送到Item Pipelines,Pipelines通过几个按顺序执行的组件来处理它。
每个Item Pipeline都是一个实现简单方法的Python类,它们接收一个Item并对其执行操作,还决定该Item是否应继续通过Pipeline,或者是否应删除并不再处理。
注意:结合Scrapy架构图阅读Item Pipelines源码会更容易理解。
Pipeline method
每个item pipeline都是一个python类,必须实现process_item方法:
-
process_item(self, item, spider)
每个Item Pipeline都会调用此方法。
process_item()必须返回包含数据的dict、Item(或任何子类)对象、返回Twisted Deferred或引发DropItem异常。删除的项(DropItem)不再由其他Pipeline处理。
此外,还可以实现以下方法:
-
open_spider(self, spider)
当spider启动时调用此方法。
-
close_spider(self, spider)
当spider关闭时调用此方法。
-
from_crawler(cls, crawler)
此方法如果存在,则调用这个类方法从
Crawler创建Item Pipeline实例,它必须返回Item Pipeline的新实例。Crawler对象提供对所有核心组件(如设置和信号)的访问,它是中间件访问scrapy核心组件并将其功能连接的一种方式。
ImagesPipeline
scrapy.pipelines.images.ImagesPipeline
配置ImagesPipeline,scrapy可自动下载图片(需要安装Pillow);
(1)配置ITEM_PIPELINES
ITEM_PIPELINES = {
...
'scrapy.pipelines.images.ImagesPipeline': 100,
}
(2)配置下载字段及存储路径
IMAGES_URLS_FIELD = field_name:ImagesPipeline会将此字段当成列表来处理,如果不是列表,则会抛ValueError异常。- IMAGES_STORE = path:图片存储位置。
注意:
-
可以对下载图片设置更多限制:如限制图片大小。
#In settings.py #限制图片大小为100x100 IMAGES_MIN_HEIGHT = 100 IMAGES_MIN_WIDTH = 100 -
更多图片配置可略读ImagesPipeline源码,因源码略长,这里不给出。
自定义Pipelines
异步数据插入MySQL
from twisted.enterprise import adbapi
import MySQLdb
class MySQLTwistedPipeline:
"""异步插入数据到mysql"""
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
db_dict = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWORD'],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True
)
dbpool = adbapi.ConnectionPool('MySQLdb', **db_dict)
return cls(dbpool)
def process_item(self, item, spider):
"""使用twisted将数据异步插入到mysql"""
query = self.dbpool.runInteraction(self.do_insert, item)
#异步插入异常处理函数
query.addErrorback(self.handle_error)
def handle_error(self, failure):
print(failure)
def do_insert(self, cursor, item):
"""Item数据插入逻辑"""
insert_sql = """"""
cursor.execute(insert_sql, values)
过滤重复数据
假设每个爬取的Item都具有唯一id,去除重复Item可以这样做:
from scrapy.exceptions import DropItem
class DuplicatesRemovePipeline(object):
"""数据去重"""
def __init__(self):
self.ids = set()
def process_item(self, item, spider):
if item['id'] in self.ids:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids.add(item['id'])
return item
注意:process_item抛出DropItem异常,Item将被丢弃(不会被其他Pipeline处理)。
将数据写入JSON文件
利用open_spider与close_spider方法实现文件的打开关闭。
import json
class JsonPipeline(object):
def open_spider(self, spider):
self.file = open('items.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item