现在开始讲另外一个知识点吧,这个知识点也是怎么说呢,就是非常有用的知识点,刚才看了一下表空间

现在咱们说一下ORACLE里面的表类型,表类型其实有这么多种表
1. 正常我们的heap table,堆表,你正常建的表
2. 然后还有分区表
3. 索引组织表
4. 簇表
5. 临时表,临时表就是用于查询排序的
6. 压缩表
7. 嵌套表,这些都没用过
ORACLE表类型也是很多的,咱们其实要考虑的就是两个表就够了,你要开发用两个表就够了,堆表和分区表,ORACLE最重要的是分区的
概念,分区的概念,正常表是大于,>是大于号,建议你大于2个G才分区,如果要是小于两个G的话,那你就不要分区这个事了,然后我刚才也
说了,日常的开发中的分表分库的问题,其实都是基于OLTP和OLAP的业务前提之下,才会进行分区,进行切割的,可能有水平,垂直切分,
在ORACLE里面早就有这种概念了,就是使用分区,来做这个事情,首先我们来扫盲一下OLTP和OLAP的概念

首先OLTP和OLAP,互联网时代,海量数据的存储和访问成为系统设计和使用的瓶颈问题,就是数据量特别大,然后业务
还挺复杂,这种问题你怎么办,对于海量数据的处理场景,主要分为两种类型,一种是联机事务的处理,还有一种是联机分析处理,
抓住关键字,一个是事务处理,还有一种是分析处理,那都是有多台机器,多个节点,表进行联机的,联机什么概念,多个机器多个节点,
就是这么去处理的,首先联机事务处理,说白了就是分布式事务了,一般是面向交易类的系统,可以这么去说,其基本特征是原始数据可以
立即传送到计算中心进行处理,然后在很短的时间内给出处理结果,其实是支持分布式事务去做,联机分析处理是指通过多个维度的,
多个方式的进行统计分析,数据的查询分析,可以做查询报表啊,可以做数据挖掘啊,分析出来了,提供一个决策啊,这种能力,就好比你
做一个离线分析,我这个就是固态硬盘,实时分析或者离线分析,都是这种大数据的处理,商品推荐,近期浏览过的商品,把同类的商品给你n
推荐过来,分析处理的,分布式的海量数据处理,就这两个概念,早期的ORACLE其实以为大数据时代,他自己能承载的住,但是很抱歉,
它是承载不住的,因为人家那个PG级的,一千亿往上的那种数据,海量数据,其实这种东西ORACLE也是无能为力的,只能利用咱们的hadoop,
做离线分析,在线分析,实时的,spark像这种东西,只能是依赖于这种东西,一千亿以下的数据,单表,单表一千亿以下的数据,这个都不算
海量数据,想这种东西你也可以考虑,这个ORACLE也是可以做处理的,理论上来说,其实刚才那个已经是很庞大的数据了

两者的主要区别,就是TP和AP的主要区别,首先TP,比如说,日常的交易处理啊,面向实时的处理,处理的是当前最新的细节的,
二维分立的,他要求读写的实时性比较高,事务的强一致性,分析要求就是很简单,很easy,像这个海量数据的分析呢,可能就很复杂了,
他实时性不一定要求很高,很低,事务性也可以很弱,你少分析一两条数据无所谓,丢一点数据也无所谓,但是很复杂,咱们可能都知道订单啊,
订单的系统,跟钱有关的业务,其实他这个业务都是很简单很简单的,不是很复杂的,可能就是这边把订单放在一个地方,他们两个可能数据
操作,业务都不是很复杂,这个事就结束了,那像OLAP这边就做很复杂的分析了,即使这边是多个节点的,但是他写业务代码的复杂度,一般
不会很复杂,而且数据量也是很小的,可能很实时,可能是1秒钟给我来100条数据,但是每条数据的量都是很小,然后这个分析的需求业务,
处理数据的业务都是很简单的,可能维度是二维的,一个时间,一个空间最多了,像AP这种就很复杂了,你要涉及到很多的东西,你要进行
一个综合的统计分析,这个东西可能就很复杂了,就做一个报表啊,类似这种东西,尤其是一些历史性的数据,比如这个东西12年它是什么
样的结果,13年怎么样,14年怎么样,15年怎么样,给我做一下同比,再给我做一下环比,同比和环比听过吗,应该都听过吧,这是一个很经典
的词,不知道搜一搜,历史数据吗,14年13年,这个数据怎么比,2月份1月份,09年12月份,09年11月份,这种规律的这种数据的对比,
这种分析很多

就是关系型数据库和非关系型数据库,首先呢特点,关系型数据库的优点和缺点,NoSQL的特点,优点和缺点,
这个东西怎么说啊,我建议你把这个东西仔细看一看,加上你自己的理解,这个说出来才有意义,要不然所有的人都和我这个说的一样,
那我觉得也没有什么技术含量,那这个优点和缺点就不用我再说了,NoSQL就是高并发大数据下,读写能力是很强的,性能是很高的,而且
是分布式的,而且是高可用的,咱们的关系型数据库呢,主要是处理事务,可以进行复杂逻辑的查询,非常的成熟,通用化,这就够了,他们
两个的优点,一个是可以解决很复杂的任务,数据库里一百多张表,NoSQL给我做一下,不现实,绝对够呛,100多张表给我映射到NoSQL里边,
你用我们的LIST,HASH,或者是ZSET,都不合适,就是他能处理很复杂的业务,能够进行join查询,技术很成熟,多少年了,NoSQL就针对于
大并发了,然后他们的缺点,也都会有

对我们的数据要进行切分,为什么要进行切分,相当于读这段话,浏览一下,就是你要通过特定的条件和规则,说白了就是你
自己的业务,怎么样去规定的,你这个业务是长成什么样,你就得把放在同一个数据库的数据,这个表放到A库里了,然后就需要把
A库里的数据,数据量很大,你得切分到B库,或者C库,这种形式,然后咱们传统上的切分就两种,一种是垂直,一种是水平,那垂直切分
是什么意思啊,它是按业务逻辑模块走的,叫Sharding,就是这个垂直的切分,其实对于ORACLE就相当于不同的SCHEMA,就是按照不同的
表,来区分不同的数据库,这个叫做垂直纵向的切分,就好像我昨天讲的那个似的,供应商里面一堆表,这个业务是一个业务,然后其他的
比如订单,购物车这是一个系统,一堆表,他们两个正常来讲,系统小的话,是不是可以用一个数据库实例,但是后来觉得这样不好用,
不好扩展,所以我要按照不同的业务模块,我这边分一个库,他们的业务是紧密相关的,然后跟其他的系统,这个系统可能是关联不大,
这个叫做垂直的切分,水平切分就是根据表中数据的逻辑关系,然后进行一个划分,水平切分就是有一个特点,同一张表中的数据按照
某一个条件,拆分到多个数据库上,注意这句话,按照表中数据的某一个条件,说白了就是某一个记录呗,按照这种规则切分到不同的
数据库上,这种方式叫做水平横向的切分,你比如说,咱们那天也讲了,咱们QQ的会员,里面都有一个字段,一个字段的条件,type这个
条件,type就是等级level,一个是一级,一个是二级,一个是三级,然后是很多,比如说四级,五级,按照这个级别,所有数据一级的用户
都放在一个库里面,存着,把二级的右放到一个数据库里面存着,像这种按照某一个条件,或者是某两个条件,这东西不是非得是一个条件,
也可能是两个三个条件,你可以是并行的关系,and关系,条件1加条件2,都满足,所有满足这两个条件的数据,都给他放到一个数据库里,
这是可以的,就是按照一种类型条件,一个字段,或者两个字段,他们两个都有对应的特点,垂直切分的特点就是规则简单,我已经把大方向
业务划分出来了,两块系统,一个是购物车,一个是订单,基本上没有太多的关系,有关系的我就合理的做一些冗余,或者做一个中间库啊,
做一个数据转换,他们之间做数据交换也可以,都行,总之垂直拆分的特点就是规则特别简单,按照不同的业务划分成两个数据库,
然后把这个数据库的表中的业务创建出来就可以了,实施也比较方便,尤其是各个业务的解耦,就是耦合性非常低,两个之间没有任何的
影响,系统之间的影响也非常小,系统的逻辑也非常的清晰,这边就是处理订单的,那边就是处理供应商的,也可以按照角色去划分,
你比如这边的系统就是用户的系统,而那边的系统就是操作人员的系统,或者是什么的系统,可以按照角色划分,然后这里边也说了,
根据不同的表来进行拆分,对程序的影响更小,拆分规则也简单,水平切分相对于垂直切分,他比较复杂,为什么啊,因为他是把一张表的
不同数据,拆分到不同的数据库上,所以这个就比较麻烦了,举个简单的例子,比如这表有1,2,3,4,四条记录,比如我把1,2条记录就拆到
一个库了,那这里就没有了,这里放1,2,这里放3,4,那最后我要查count的时候,我至少要连两个数据源,然后count(*),这边再
count(*),两边再加起来,一共是4,最起码要做这个事了,那这个东西维护起来也比较麻烦一些

这边就是画一个,什么叫垂直拆分就在这儿呢,本身之前是一个库,单个的database,用户系统单独划分一个database了,
订单系统一个database,支付系统又有一个database,他们之间可能有一些数据的交换,这也是从网上随便抓的一个图,
这个很简单

什么是水平切分呢,就是按照某一种规则,来把一张表的数据库,一张表的数据,分散到各个库上,比如说,这个逻辑都是
这么去分的,大方向肯定是按照垂直进行拆分,我把单个数据库变成3个系统,一个是用户,一个是订单,还有一个是支付,
然后我先我用户的数据真的是很多很多,那怎么办啊,用户这张表啊,我指的是一个用户系统,用户系统里可能有10几张表,
就不一定是一张表,那我可能觉得user这张表可能太多了,比如说腾讯,那怎么办啊,用户我按照我自己的业务规则,按照
用户的ID啊,或者按照其他的type啊,时间啊,按照这种规则,一个也好,两个也好,我把它拆分成3个数据库,存放不同的数据,
这三个才放一个表里的数据,有什么拆分的原则和规范吗,其实拆分的原则很简单,拆分的原则是什么啊,我就简单的说两个原则吧,
两个条件满足吧,两个条件一定是and的情况,并不是OR的情况,AND和OR是有区别的,1和2两个是AND的时候,你才能采用分表,
分表的这个理念,分表也叫分片,一般来讲也可以这么去说,都一样的,什么意思呢,第一个条件是什么啊,第一个条件一定是要
访问的非常的频繁,这个才是最主要的,高并发下,访问频繁,非常的频繁,可能1,秒钟就访问多少多少次,访问的非常的频繁,
满足这一个条件就OK了,第二个就是数据量太大了,就是数据量大,我记得我也说过了,就是你即使数据量大,数据量多大啊,
数据量很大很大,那我也不一定非要这么分表啊,按照你自己的需求来,你数据量大,但是我可能就一天查询一次,那我就后台
定时跑一个存储过程,或者每天凌晨的两天钟跑一个存储过程,第二天6点钟才会看这个数据结果,你就没必要做这个事情了,
你把这个很大的一张表,你把它分成不同的数据库,这样给你的业务就增大难度了,本来做这个事就很简单的,当然这个数据量
大到什么程度上,我觉得就是10个G左右吧,或者是20个G,你要是上百G,我这个表,我是没见过,反正我觉得50个G就是一个极限了,
你表里的数据如果有50个G的话,ORACLE来讲,就不管你这个表是不是频繁访问,你以后维护也麻烦啊,你就需要把这个东西做一个分库,
或者说你不分库也行,但是你起码也不是单表50个G,你可以把它分散成多个表,user表随便起个名字,里面50个G,那我现在把它拆开,
把它分成u1,u2,u3,u4,u5,......,每个表里放10个G,这样多好啊,为什么我们不往同一个数据库里去切分,为什么50个G不是这里放
10个G,这里放10个G,这里也放10个G,这边还有10个G,为什么不放在5张表,放到一个数据库里呢,还是我刚刚说的第一个条件,
并发大,并发大你这里是一个数据源,反正我这个service肯定要返回一个数据源,所以你这么拆不拆没啥用,就是一定要知道,
你必须得分成数据库了,多个数据源,可能这个并发有1万次,1万次太多了,举个简单的例子,我就随便说5万次,并发5万次,
其实这也是一个负债均衡,第一个数据源承担了一万次,第二个数据源又承担了一万次,然后你还可以再细粒度,也可以这里面
再拆分10个,放到这儿,一个数据库可能承担5千次,然后再2往下递归的铺垫,这都行

相当于拆分的优缺点了,优点我就简单的介绍一下了,垂直拆分的优点就这三个:
1. 业务逻辑清晰
2. 扩展性强
3. 维护起来非常简单
在软件设计上有一个什么啊,怎么说呢,有一个原则,我之前好像也说过,我记得外国有一个很牛的人,他说了一个话,
别人都跟他一起说了,你做软件开发吧,现在不是都讲分布式事务吗,分布式,如果你的应用能不用分布式事务的方式实现,
原始垂直的方案实现,那你最好就原始垂直的方案,分布式第一个首要的原则,能不用分布式就不用分布式,能理解我说的意思吧,
这是设计开始的第一个原则,就是尽量别用分布式,分布式带来的成本,包括不可控的东西太多了,所以说垂直拆分就是最简单的,
水平拆分你得有一个规则,之前的规则你得做的足够好,这才行,尽量的去避免多个数据源之间的联合,这里面的join是什么意思呢,
我跟你们说啊,事实上是这样的,相当于这里一个数据源,这里两个数据源,就是这边有一张表,这边有一张表,这两个表之间要有一个
join,要有一个join关系,但是你不能写数据库语句写成那样,这两个数据源吗,所以他们两个有一个通用的字段,比如这边规定有一个
type类型,然后这边有一个id,其他的,他们两个有一个自定义的主外键关系,挂上钩,通过这里的字段就可以找到这里惟一的数据,
是这样的,通过这种方案,这也可以叫做一种join
然后就是水平拆分的优点:
1. 可以提高并发的能力,肯定能提高并发的能力,我要把数据分到不同的分片上,不同的库上了,然后提高系统的稳定性和负载能力
然后下面就是有一个小例子,也很简单的,其实我在这里说其实没啥意义,还是得根据你以后的具体的工作,具体的需求,可能我要
按照时间的维度,时间进行一个拆分,水平的拆表,可以按照不同的角色,进行拆分,供应商或者用户,按照不同的业务规则等等去做,
这种东西都不是不固定的,如果数据库设计有一个固定的套路的话,那这个就太简单了,这种事本来就是一个很难把控的一件事,
然后比如你电商里买东西,有一些自营产品,还有一些第三方的产品,那就会进行分库的操作,我自营的放到一个数据库里面,还有
订单的分流,放到不同的数据节点上,有很多,真是没有一个很细粒度的说明,只是一些大体上的概念上的问题,以后做实际案例的
时候再说吧,这个目前只能是到这个程度了

拆分的缺点和解决方案,这块就是你做数据拆分了,你无论是做水平拆分也好,还是做垂直拆分也好,你都会有一些共通的缺点
主要是有三大缺点吧,小缺点一堆,但是我们要解决三大核心的缺点
1. 第一大缺点是解决了分布式事务的问题,因为不管是水平还是垂直,你总是把数据分散到不同的数据源上了,比如物理来讲
就是返回了不同的机器,所以来说他就会有一些分布式事务的问题,肯定是有这个问题的,解决方案其实多了去了,我只是列这么
几种,解决方案,根据不同的实例,具体分析解决,那我举三个常见的方案,第一种方案,比如你业务逻辑非常复杂的时候,这什么意思,
说白了,就是你要有一个概念,我画一个图吧,比如现在我把原先一个数据库的东西,我分成了三个数据库,分成了三个数据库,
然后第一块存了1,2,3,第二块存了4,5,6,第三块存了7,8,9,那就是一个很简单的逻辑,像这种问题,只要是拆分了,涉及到分布式
事务的问题,这是百分百会涉及的,我们应该怎么去解决分布式事务的问题呢,这个还是得按照你具体的问题具体的去分析,你只能
这么说,比如说你这个业务逻辑非常复杂,但是数据量不大的时候,什么叫业务逻辑非常复杂啊,我们都写过JAVA代码,可能是业务逻辑
很复杂,正常来讲一个数据库的话,你怎么去写,从service开始,一直到service结束,我可能写了2千多行的业务,甚至说更多,就是一个
Service里面包含了两千多行,你这个业务逻辑很复杂的时候,然后你还得操作不同的数据,你前1千行代码,也操作这三条数据,后一千行
代码也操作另外一个一千行数据,最后你还得操作另外一个一千行数据,最后再结束,我举的例子就是业务逻辑很复杂的时候,你应该怎么
去考虑,业务逻辑复杂的时候的话,一般这种都是使用SOA,做通用的服务,就这么办是最简单,最省事的,我个人觉得是最OK的,在Service
层上做多个切面,配置多个事务,我先不讲具体怎么做,能理解吗,使用SOA做通用的服务,在Service层上做多个切面,配置多个事务,
首先我说的第一种方案是在业务逻辑复杂的时候,SOA我画一个图吧,只有想不到,没有做不到的事情,举个例子吧,就现在咱们说,
这种电商的网站,可能不一定就是电商了,就比如WEB服务吧,这是我的WEB服务,这又是一个WEB服务,这又是一个WEB服务,可以吧,
WEB服务干什么呢,WEB服务就是一个应用吗,WEB APPLICATION,我要把它放到TOMCAT,或者WEB容器上去运行,那我把这个
叫做WEB1,WEB2WEB3,这边叫WEB1,这边叫WEB2,这边叫WEB3,这是我的三个WEB应用,三个应用涉及到不同的逻辑,相当于三个系统,
这边对应的可能就是我的服务层了,那么着三个服务层就是SOA,1,2,3,SOA1,SOA2,SOA3,就是这个意思,SOA是什么意思呢,
咱们以前写代码的时候,写JAVA代码的时候,或者你做项目的时候,之前不是这么去写的,就是一个JAVA Project,里面分层吗,
先有一个WEB层,就是Controller,然后就是Service层,然后Service Implement层,然后还有DAO层,数据访问层,持久层,
然后有什么实体啊,Entity,这个不说了,大体上就是这样的,现在一种新型的都是怎么去做的呢,把WEB层提出来,
他就类似于我们这里的WEB1,WEB2,WEB3, 然后所有的Service层都抽出来,转换成不同的SOA服务,比如WEB1是针对于用户的,
这可能是user web1,那就涉及到增删改查的,user service,就是us吧,
我把它就当做一个服务了,那当然用户还关联一些角色啊,就是role,role service,还可能关联一些岗位啊,什么权限啊,包括什么
功能啊,总之跟这个模块相关的service,我都给他独立出来,抽象成一个一个的小service,然后直接扔到这个系统中,可能一个服务
一个服务单独的去linux中java -jar,然后就直接把这个服务给启动了,之前也学过netty,学netty不是学了怎么起的吗,java -jar
启动主函数,服务就起来了,那这个service其实我也可以这么去做,都一样的,好了,那这里就提供了10个服务,SOA1就提供了10个
服务,那这10个服务可能就针对WEB1去做服务的,那也可能有一种情况就是说,可以有一种什么情况啊,不一定这10个服务就是针对
与他的,有可能针对于它,也可能针对于她,总之我这个SOA1,里面假设有100个小服务的话,里面有80个,甚至80个以上,针对WEB1的,
可能有些服务是通用的服务,这个就不说了,比如这里是订单的一个系统,ORDER,这一百个服务都是针对订单,每个系统都有一些耦合,
这是肯定的,包括第三个,比如购物车,这个WEB系统,那我现在的原则就是什么啊,就包括我以前做设计的时候,一个SOA只对应一个
数据源,一个DATABASE,就是一个DB,然后这个SOA也是对应一个DB,一个数据源,这一个也对应一个DB,举个例子,那假如我先做有一个
问题,说WEB2里面就是有一个功能,就是需要SOA1里面的其中的一个服务,并且还要用到SOA3的一个服务,那这个东西怎么去做呢,
他们两个用的是不同的数据源,一个是DB1,一个是DB3,来一个SOA4,如果有这种公用的话,那我就可以单独来一个Service,他可能
就不返回任何的数据库了,就是为了抽取公共的,也不一定访问数据库,可以访问也可以不访问,有没有都一样,然后这里面就
写一个service,这个怎么写呢,咱们就叫public SOA4,里面去调SOA1,SOA3的service,里面加两个事务的切面,
相当于Spring的XML配置的话,加两个execution,这两个切面都对应上,都加到这一个方法上,这样的话只要这个方法
一失败的话,同时就回滚两个切面里的SOA1,和SOA3服务,我说的方案是针对于你的业务逻辑很复杂的时候,你要采用这种,
可能我这里跨度很大,可能既要访问SOA1,SOA2,SOA3,还有可能要访问SOA5,可能提供更多的服务了,总之要调好多service的时候,
那你就这么去做,这么去做就OK的
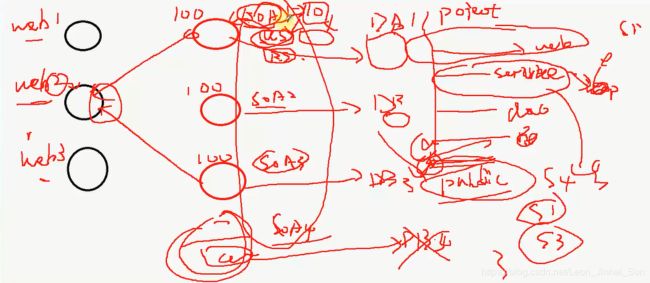
我就暴露两个服务,真很简单,就是你写一个方法的时候,你这么去写,public 这个方法我略了,这个方法里面我调一个SOA,
我再把我两个数据源,DB1和D3的数据源,这个本来就是一个SOA的服务,那这个服务肯定对应了一堆的配置,
Spring的ApplicationContextxml,我把两个数据源都放到这里面,不就OK了吗,我再配置两个事务,这个叫T1,这个叫T3,
这个数据源叫D1,D3,然后我再配置两个切面,D1的数据源配一下S方法,D3的数据源再配一下S方法,就好像加两个Transaction一样,
在这个方法上加一个,然后在这个方法上又加一个,这不就OK了吗,分布式的主要意思概念就是,分布式不是系统来的,他就是按照表来的,
我可以很笃定的跟你说,我先做只要有两个数据源,这里面放一部分表,这里面放一部分表,这个系统就是一个分布式系统,
分布式概念就是这么来的
