Hadoop完全分布式安装的心酸历程
1.下载VMware安装包
官网下载地址:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html。
下载后点击.exe文件进行安装,安装成功后首次登录需要输入注册码,根据自己安装的版本百度搜索对应的注册码即可,输入注册码后即完成该软件的破解。破解后进入VMware的主界面如图1所示。
 图1 VMware主界面
图1 VMware主界面
2.设置VMware的网络连接模式:
点击“编辑”下的“虚拟网络编辑器”,进入VMware的网络设置界面(如图2所示),点击“![]() ””进入管理员权限下的网络设置界面(如图3所示):(1)选择NAT模式,各个虚拟机通过NAT使用宿主机的IP来访问外网。(2)我们的要求是集群中的各个虚拟机有固定的IP、可以访问外网,所以勾掉“
””进入管理员权限下的网络设置界面(如图3所示):(1)选择NAT模式,各个虚拟机通过NAT使用宿主机的IP来访问外网。(2)我们的要求是集群中的各个虚拟机有固定的IP、可以访问外网,所以勾掉“![]() ”;(3)点击“
”;(3)点击“![]() ”,进入NAT设置界面(如图4所示),这里需要记一下网关IP(192.168.211.2)后面的配置会用到,点击“
”,进入NAT设置界面(如图4所示),这里需要记一下网关IP(192.168.211.2)后面的配置会用到,点击“![]() ”进行DNS配置(如图5所示)。至此VMware的网络配置完毕。
”进行DNS配置(如图5所示)。至此VMware的网络配置完毕。
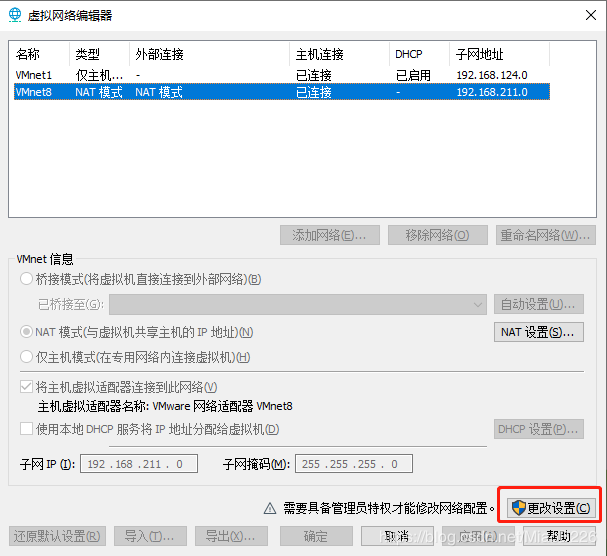 图2 WMware网络设置界面
图2 WMware网络设置界面
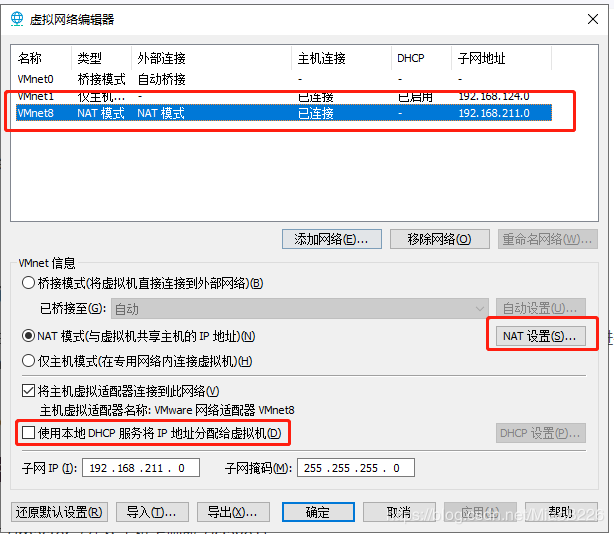 图3 管理员权限下的VMware网络设置界面
图3 管理员权限下的VMware网络设置界面
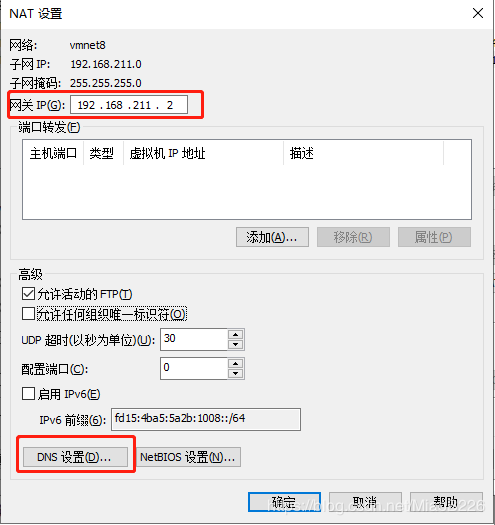 图4 NAT设置界面
图4 NAT设置界面
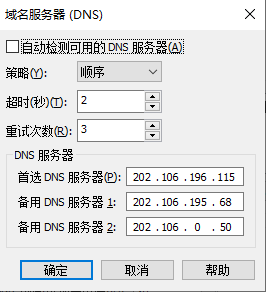 图5 DNS配置界面标题
图5 DNS配置界面标题
3.安装虚拟机
(1)在VMware主页点击“新建虚拟机”;
(2)选择“典型”安装,点击“下一步”,如图6所示;
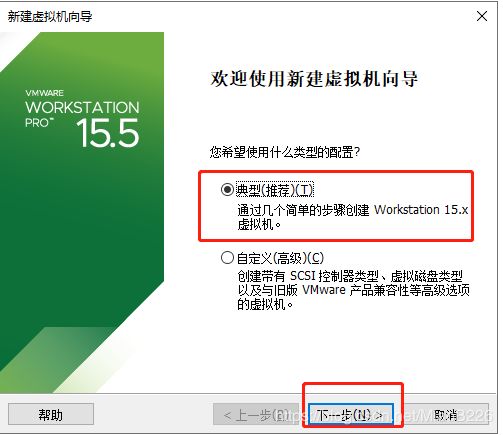 图6 选择典型安装
图6 选择典型安装
(3)选择“稍后暗转操作系统”,点击“下一步”,如图7所示;
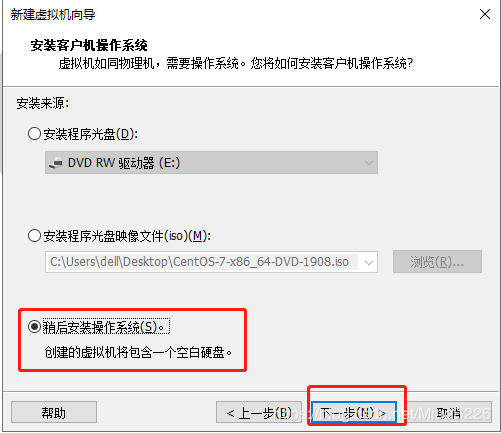 图7 选择稍后安装操作系统
图7 选择稍后安装操作系统
(4)选择要安装的系统类型,这里我选择的是Linux操作系统,系统版本为Centos7 64位,如图8所示;
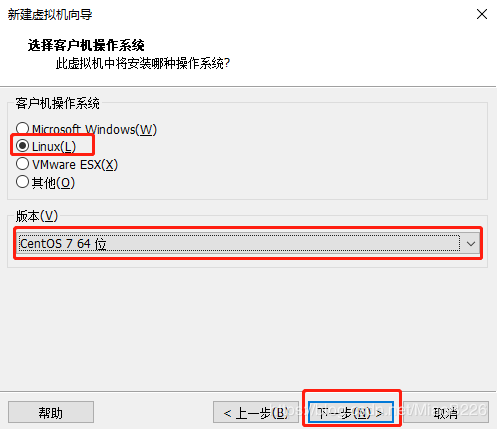 图8 选择要装的系统与版本
图8 选择要装的系统与版本
(5)设置虚拟机的名称与安装位置,如图9所示;
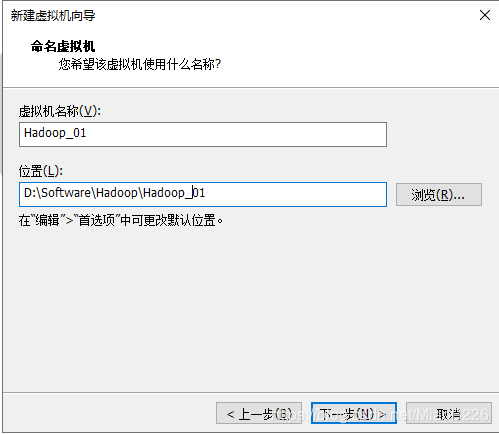 图9 设置虚拟机的名称与路径
图9 设置虚拟机的名称与路径
(6)设置虚拟机的空间大小,默认的设置即可,如图10所示;
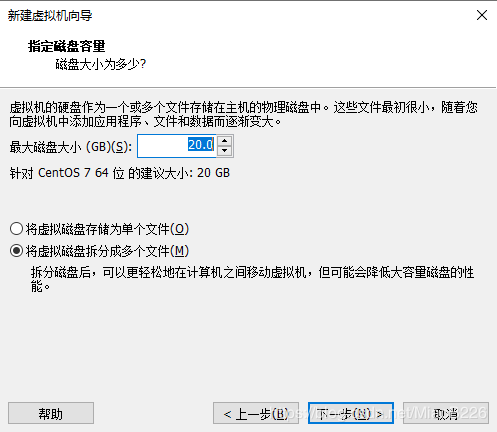 图10 设置虚拟机的空间大小
图10 设置虚拟机的空间大小
(7)点击“完成”实现虚拟机的安装,如图11所示;
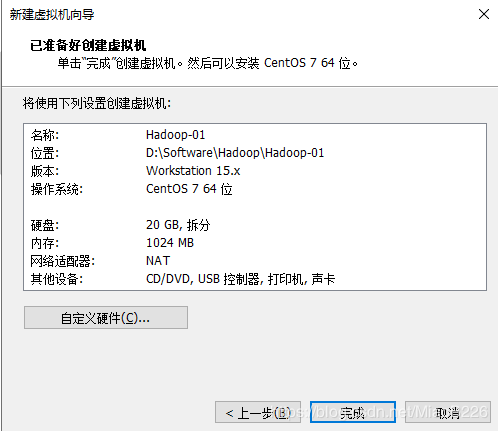 图11 完成虚拟机的安装
图11 完成虚拟机的安装
(8)下载Centos7的iso镜像文件,选择下载“CentOS-7-x86_64-DVD-2003.iso”(下载地址:http://mirrors.aliyun.com/centos/7/isos/x86_64/),如图12所示;
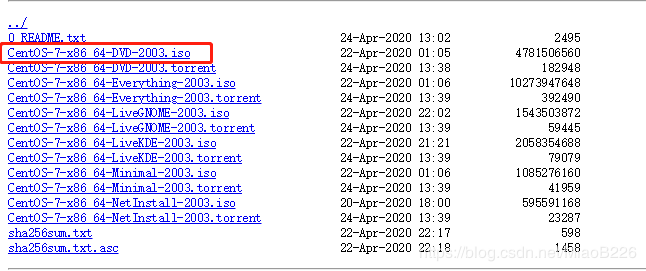 图12 下载Centos7的iso镜像文件
图12 下载Centos7的iso镜像文件
(9)点击“编辑虚拟机设置”来进行虚拟机相关信息的设置,如图13所示:
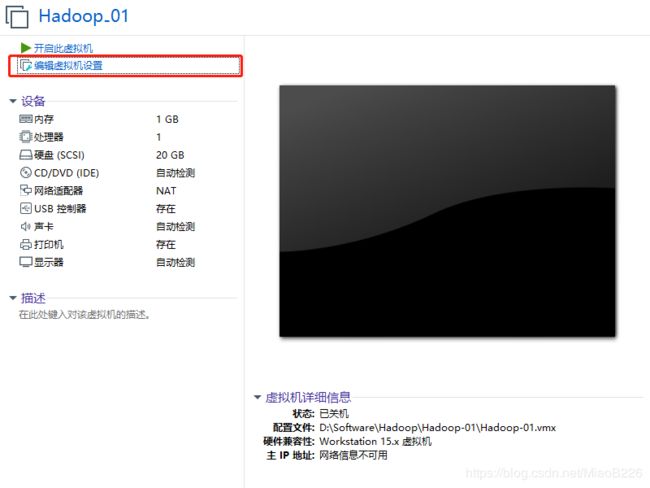 图13 编辑虚拟机设置
图13 编辑虚拟机设置
(10)点击DVD,指定操作系统ISO文件所在位置,如图14所示。
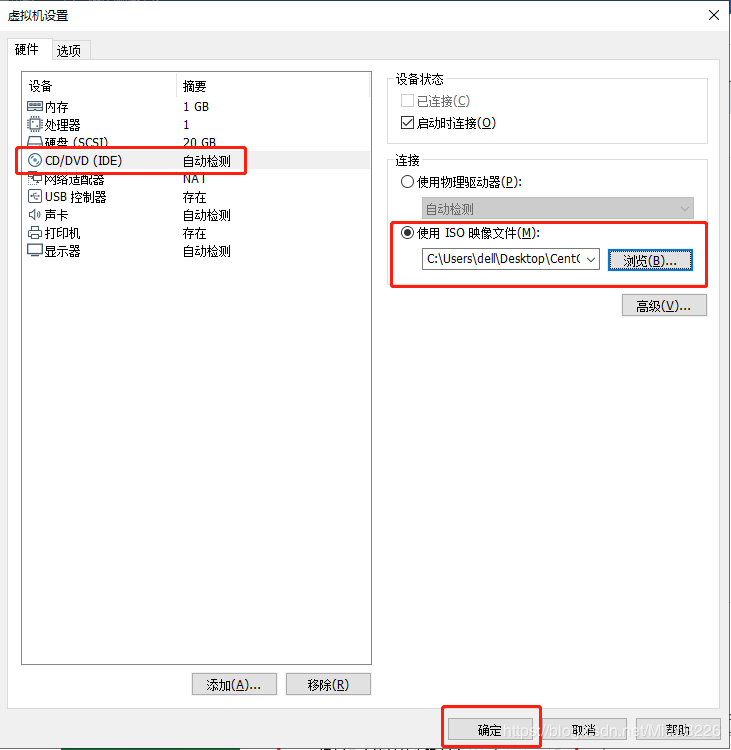 图14 指定操作系统ISO文件位置
图14 指定操作系统ISO文件位置
(11)开启虚拟机,进行系统安装,如图15所示;
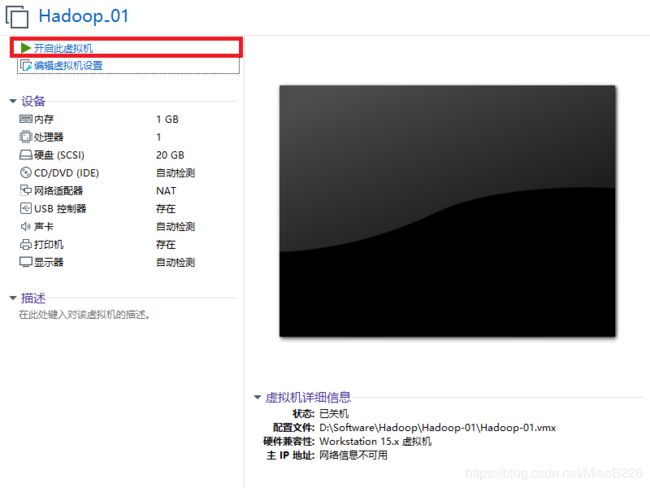 图15 开启虚拟机进行系统安装
图15 开启虚拟机进行系统安装
(12)敲击回车,进行系统的安装,如图16所示;
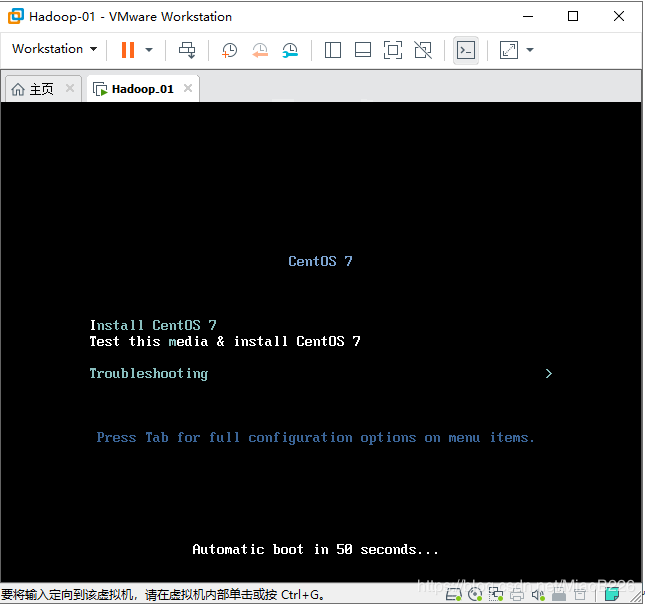 图16 进行系统安装
图16 进行系统安装
(13)选择安装系统的版本(英文版、中文版),默认安装英文版,根据自身需求选择(建议选择英文版,路径不容易出错),如图17所示;
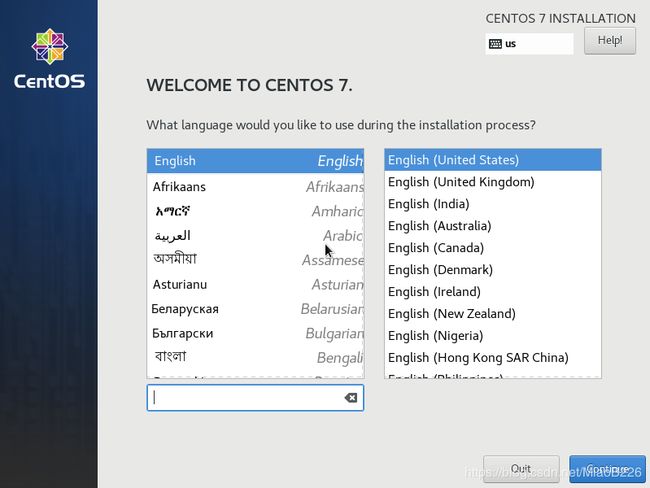 图17 选择安装系统的语言
图17 选择安装系统的语言
(14)进行安装前的必要配置,配置完成后才能进行安装(如图18所示),使用默认的配置即可,直接点击“Done”按钮(如图19所示),点击“Begin Installation”开始进行安装(如图20所示)。
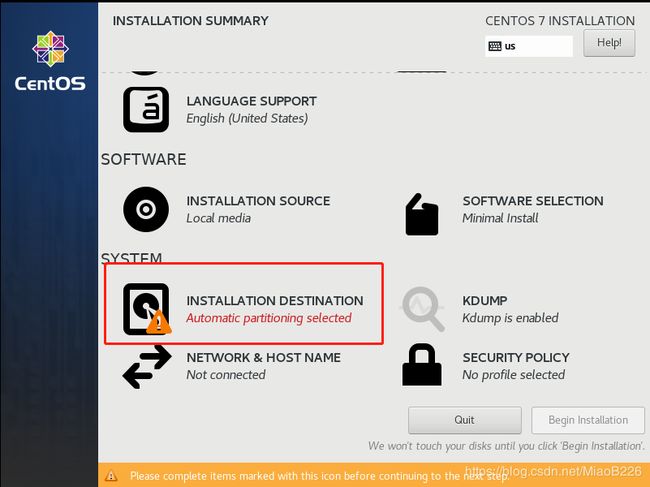 图18 进行安装所需的配置
图18 进行安装所需的配置
 图19 选择默认配置
图19 选择默认配置
 图20 开始进行安装
图20 开始进行安装
(15)点击“ROOT PASSWORD”进行root账户密码的设置(如图21所示),为root账户设置完密码后点击“Done”(如图22所示),点击“Finish configuration”按钮完成配置继续进行安装(如图23所示)。点击Reboot启动操作系统(如图24所示)。
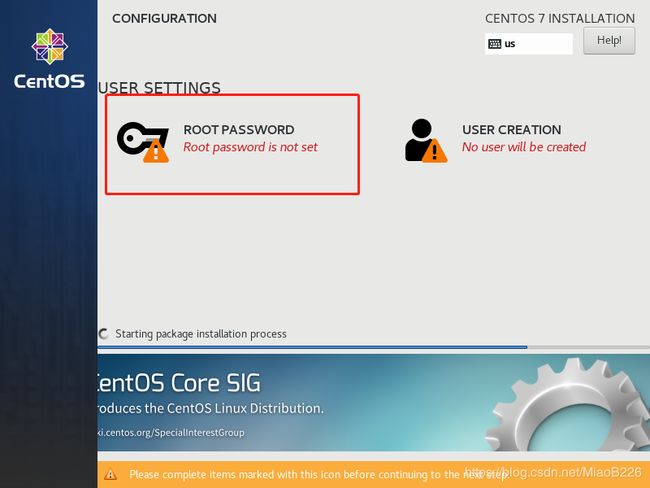 图21 为root账户设置密码
图21 为root账户设置密码
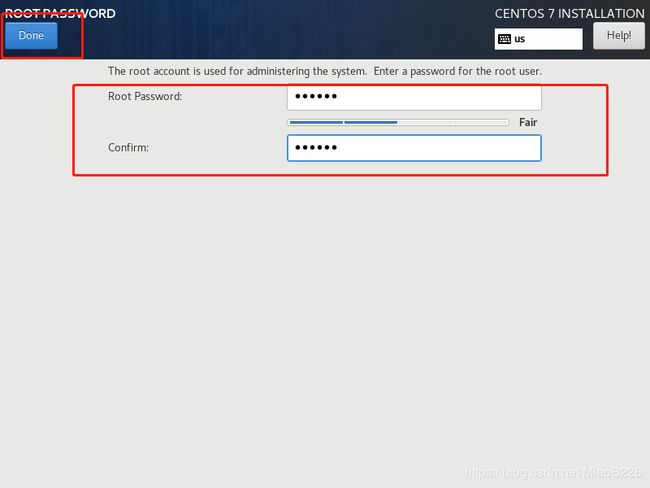 图22 为root账户设置密码
图22 为root账户设置密码
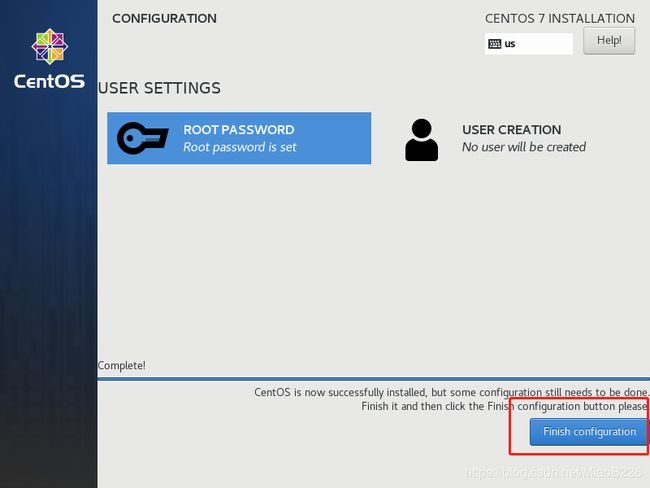 图23 完成配置
图23 完成配置
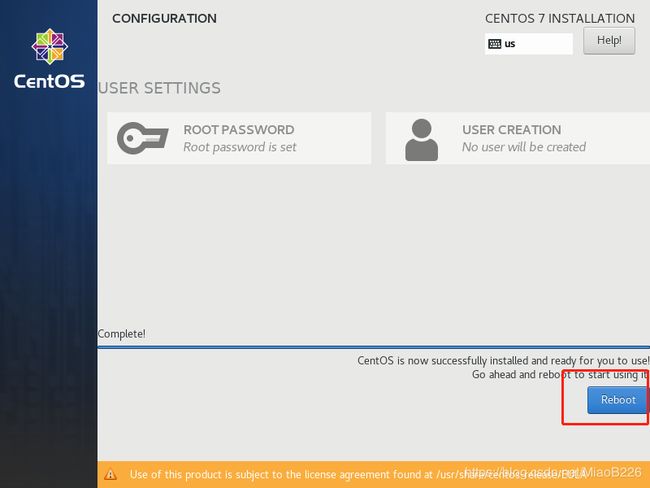 图24 安装成功重启系统
图24 安装成功重启系统
按上述方法,功安装3个虚拟机,分别是hadoop_01、hadoop_02、hadoop_03。
- 配置虚拟机的网络
(1)Centos 7的网络配置文件在/etc/sysconfig/network-scripts/下,名称类似ifcfg-*,进入这个文件夹下进行查看(如图25所示),在我的系统中这个文件为ifcfg-ens33。
 图25 查找Centos7网络配置文件
图25 查找Centos7网络配置文件
(2)编辑网络配置文件,输入如下命令:vi ifcfg-ens33。修改后的配置文件如图26所示
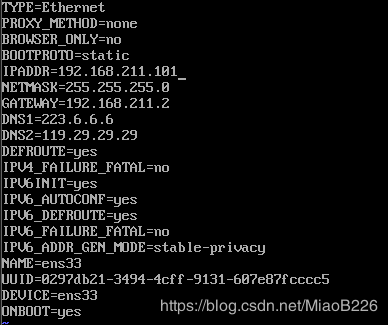 图26修改网络配置文件
图26修改网络配置文件
BOOTPROTO=static #启用静态IP地址
IPADDR=192.168.211.101 #IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.211.2 #默认网关,就是在配置VMware时让记住的那个网关ip
DNS1=223.6.6.6 #DNS
DNS2=119.29.29.29 #备用DNS
ONBOOT=yes #开机启用本配置
编辑完成后,保存修改。输入命令:wq
(3)重启网络,输入如下命令:service network restart
查看IP地址,输入如下命令:ip addr
看一下网络是否通畅,输入如下命令:ping ww.baidu.com
如果看到如图27所示,那么恭喜你网络已经畅通无阻了。
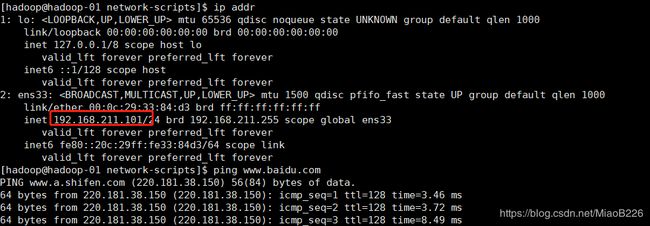 图27 查看配置网络是否畅通
图27 查看配置网络是否畅通
(4)关闭防火墙
查看防火墙状态(如图28所示,绿色的active running表示防火墙开启),输入如下命令:systemctl status firewalld.servic
 图28 查看防火墙状态
图28 查看防火墙状态
关闭防火墙,输入如下命令:systemctl stop firewalld.service,再次查看防火墙的状态为 inactive(dead),证明防火墙已被关闭(如图29所示)。
 图29 关闭防火墙
图29 关闭防火墙
如果像永久关闭防火墙,只需禁止防火墙服务开机自启(如图30所示),输入如下命令:systemctl disable firewalld.service图31 禁止防火墙服务开机启动
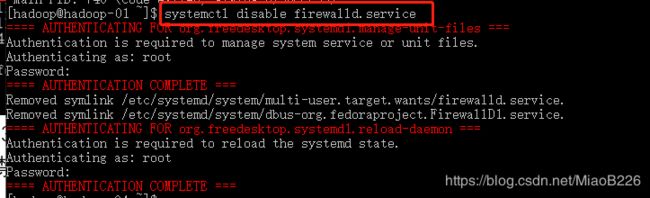 图30 禁止防火墙服务开机启动
图30 禁止防火墙服务开机启动
按照上面的方法依次配置hadoop_02与hadoop_03的网络,网络配置文件除IP地址以外其它设置一与hadoop_01一样(注:hadoop_02的IP为192.168.211.102、hadoop_03的IP为192.168.211.103)。
(5)关闭selinux
编辑selinux文件,输入如下命令:vi /etc/sysconfig/selinux。设置SELINUX=disabled如图31所示,修改完成后输入如下命令(wq)进行保存。
 图31 关闭selinux
图31 关闭selinux
5.为每台虚拟机新建一个Hadoop用户,并授予sudo权限。
新建hadoop用户,输入如下命令:sudo useradd -m hadoop -s /bin/bash
修改hadoop用户的密码,输入如下命令:sudo passwd Hadoop
授予hadoop用户sudo权限,输入如下命令:sudo adduser hadoop sudo图33 新建用户并授予sudo权限
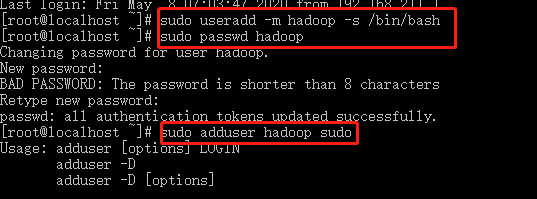 图32 新建用户并授予sudo权限
图32 新建用户并授予sudo权限
需要编辑一下/etc/sudoers文件在里面将hadoop用户加入授权即可,输入命令:vi /etc/sudoers
修改后的文件如图33所示,编辑完成后,保存修改。输入命令:wq!
 图33 将新用户授予sudo权限
图33 将新用户授予sudo权限
6.修改主机名
输入以下命令修改主机名:hostnamectl set-hostname 主机名
例如(hadoop_01):hostnamectl set-hostname hadoop-01.host.com
例如(hadoop_02):hostnamectl set-hostname hadoop-02.host.com
例如(hadoop_03):hostnamectl set-hostname hadoop-03.host.com
修改完后重新登录会发现主机名已经完成修改,修改成功的实例如图34所示(hadoop:用户名、hadoop-01:主机名):
7.设置hosts
添加本机与另外两台机器的IP地址与主机名,输入如下命令(编辑后的文件如图35所示):sudo vi /etc/hosts
 图35 编辑后的hosts的文件
图35 编辑后的hosts的文件
192.168.211.101 :主机IP地址
hadoop-01.host.com:长主机名
Hadoop-01:短主机名
8.设置3台虚拟主机之间可以ssh免密码登录;
(1)在hadoop-01上生成公钥,输入如下命令:ssh-keygen -t rsa
输入命令后一直回车即可(如图36所示)。
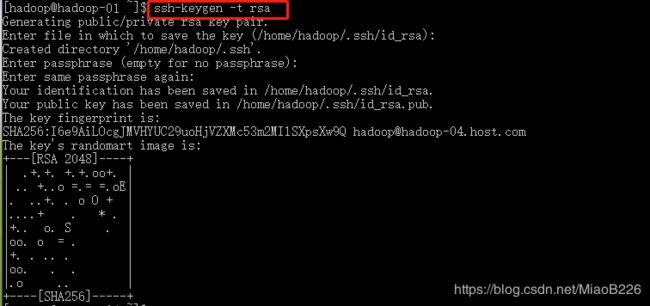 图36 在主机上生成公钥
图36 在主机上生成公钥
(2)向本机以及其它主机分发公钥,依次输入如下命令(如图37所示):
ssh-copy-id hadoop-01.host.com
ssh-copy-id hadoop-02.host.com
ssh-copy-id hadoop-03.host.com
 图37 分发公钥
图37 分发公钥
(3)设置hadoop-02、hadoop-03到其他机器的无密钥登录
9、安装java环境
在官网下载linux的jdk安装包,网址如下所示:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html。选择下载Linux x64 Compressed Archive类型(如图38所示,注:下载需要有Oracle的账号与密码)
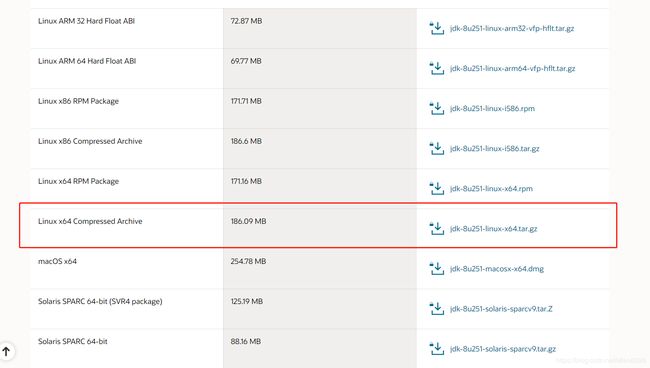 图38 下载java安装包
图38 下载java安装包
使用xftp工具将下载的安装包传到hadoop-01主机中,我这里将文件传到了/home/hadoop/Downloads文件夹下。
(1)在 /usr/lib 下创建名为jvm的文件夹,用来存储jdk文件,输入如下命令:
cd /etc/lib
sudo mkdir jvm
(2)将下载的压缩包文件解压到jvm文件夹下,输入如下命令:
cd /home/Hadoop/Downloads
sudo tar -zxvf ./jdk-8u251-linux-i586.tar.gz -C /usr/lib/jvm/
 图39 解压缩jdk
图39 解压缩jdk
(3)设置jdk的环境变量
使用如下命令:cd /usr/lib/jvm ,可以看到解压后的jdk文件,如图40所示。
 图40 查看解压后的文件
图40 查看解压后的文件
编辑.bashrc文件,输入如下命令:sudo vi ~/.bashrc
在最前面加入两行:
export JAVA_HOME=JDK解压路径
export PATH=$JAVA_HOME/bin:$PATH(如图41所示)
接着输入完成编辑命令:wq
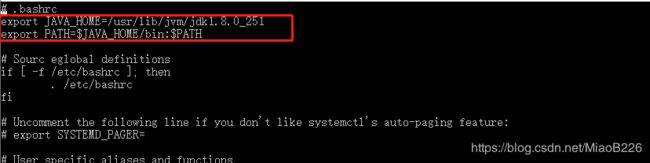 图41 添加jdk环境变量
图41 添加jdk环境变量
接着还需要让该环境变量生效,输入如下命令:source ~/.bashrc
输入如下命令,看java环境是否安装成功:java -version
安装成功,如图42所示
 图42 成功安装jdk
图42 成功安装jdk
如果报图43所示的错误,则输入如下命令:sudo yum install glibc.i686,一直输入y即可。安装成功后,再次输入:java -version
(4)为hadoop-02、hadoop-03安装jdk
10.安装Hadoop
(1)官网下载地址:https://hadoop.apache.org/releases.html
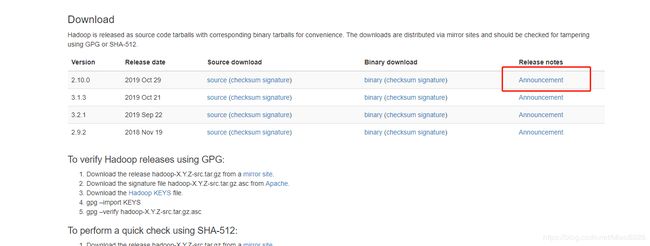 图44 hadoop下载
图44 hadoop下载
(2)点击Announcement,进入下载界面,选择“Download tar.gz”。如图45所示:
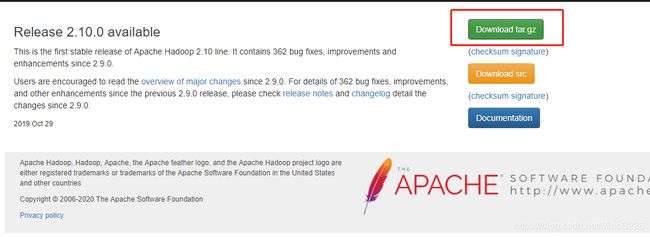 图45 hadoop下载
图45 hadoop下载
(3)将下载后的Hadoop文件同样上传文件到/home/hadoop/Downloads文件夹下。
将下载的压缩包文件解压到/usr/local文件夹下,输入如下命令:
cd /home/Hadoop/Downloads
sudo tar -zxf hadoop-2.10.0.tar.gz -C /usr/local/
(4)修改hadoop的配置文件(hadoop-2.10.0/etc/hadoop文件夹下的slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml )
首先在/usr/local/ hadoop-2.10.0下新建一个文件夹:sudo mkdir hdfs
紧接着在/usr/local/Hadoop-2.10.0下新建三个文件夹:
sudo mkdir tmp
sudo mkdir data
sudo mkdir name
slaves
文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost。分布式配置可以保留 localhost,也可以删掉(让 hadoop-01 节点仅作为 NameNode 使用)。这里,我删掉了localhost,让hadoop-01节点仅作为NameNode使用。编辑后的文件如图46所示:
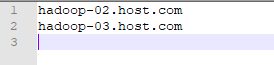 图46 编辑后的slaves文件
图46 编辑后的slaves文件
core-site.xml
fs.defaults参数配置的是HDFS的地址,hadoop.tmp.dir配置的是Hadoop临时目录(创建的tmp文件夹)。编辑后的文件如图47所示:
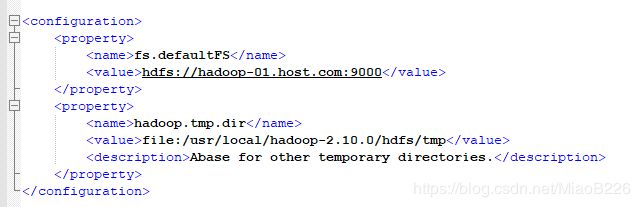 图47 编辑后的core-site.xml文件
图47 编辑后的core-site.xml文件
hdfs-site.xml
dfs.replication 一般设为 3,但我们只有hadoop-02与hadoop-03两个节点,所以 dfs.replication 的值设为 2:
dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将hadoop-03规划为SecondaryNameNode服务器。
dfs.namenode.name.dir配置的是namenode的存储目录(创建的name文件夹)。
dfs.namenode.data.dir配置的是datanode的存储目录(创建的name文件夹)。
配置信息如图48所示:
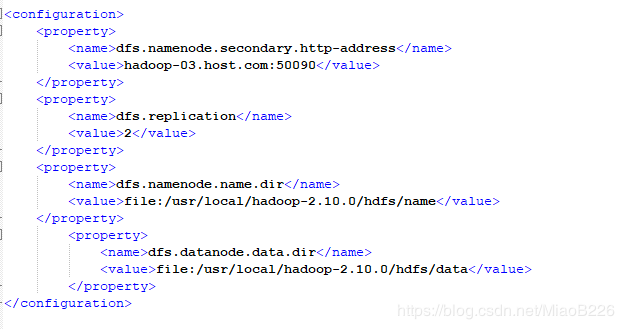 图48 编辑后的hdfs-site.xml文件
图48 编辑后的hdfs-site.xml文件
mapred-site.xml
可能需要先重命名,默认文件名为 mapred-site.xml.template
mapreduce.framework.name设置mapreduce任务运行在yarn上。
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在hadoop-03机器上。
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号。
 图49 编辑后的
mapred-site.xml
文件
图49 编辑后的
mapred-site.xml
文件
yarn-site.xml
根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向hadoop-02.host.com。
 图50 编辑后的yarn-site.xml
图50 编辑后的yarn-site.xml
(5)通过scp来分发hadoop软件
使用命令将hadoop-01上的hadoop-2.10.0文件夹分发到hadoop-02与hadoop-03上,命令如下所示:
scp -r /usr/local/hadoop-2.10.0/ hadoop-02.host.com:/usr/local
scp -r /usr/local/hadoop-2.10.0/ hadoop-03.host.com:/usr/local
(6)在hadoop-01上添加hadoop环境变量
sudo vi ~/.bashrc
在文件中加入这一行,如图51所示,修改完成后保存修改输入如下命令:wq。
export PATH=$PATH:/usr/local/hadoop-2.10.0/bin:/usr/local/hadoop-2.10.0/sbin
 图51 添加hadoop环境变量
图51 添加hadoop环境变量
更新环境变量:
source ~/.bashrc
(7) 格式化NameNode(根据自己需求是否要格式化)
在hadoop-01输入如下命令:
/usr/local/hadoop-2.10.0/bin/hdfs namenode –format
切记:如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
(8)启动hdfs
按规划,hdfs服务器是部署在hadoop-01上的。因此,首先在hadoop-01上启动hdfs,输入如下命令:
/usr/local/hadoop-2.10.0/sbin/start-dfs.sh
查看启动情况,输入如下命令:jps
 图52 成功启动hdfs
图52 成功启动hdfs
(9) 启动YARN
按照规划,yarn服务器是部署在hadoop-02上的。因此,在hadoop-02上启动yarn,输入如下命令:
/usr/local/hadoop-2.10.0/sbin/start-yarn.sh
查看启动情况,输入命令:jps
 图53 成功启动yarn
图53 成功启动yarn
(10) 启动日志服务器
按照规划,日志服务器是部署在hadoop-03上的。因此,在hadoop-0上启动日志服务,输入如下命令:
/usr/local/hadoop-2.10/sbin/mr-jobhistory-daemon.sh start historyserver
查看启动情况,输入命令:jps
 图54 成功启动日志服务器
图54 成功启动日志服务器
11、配置主机(安装虚拟机的机器)hosts
(1)win + r
(2)输入drivers
 图55 编辑本机hosts
图55 编辑本机hosts
(3)进入etc文件夹
 图56 编辑hosts
图56 编辑hosts
(4)编辑hosts文件(切记,这个文件需要以管理员身份编辑)
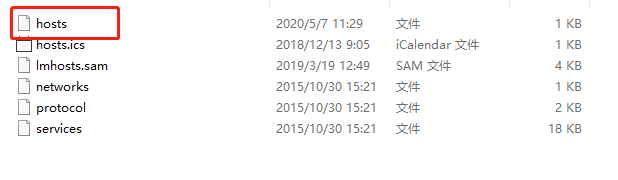 图57 编辑hosts
图57 编辑hosts
(5)添加3个虚拟机的IP地址与主机名
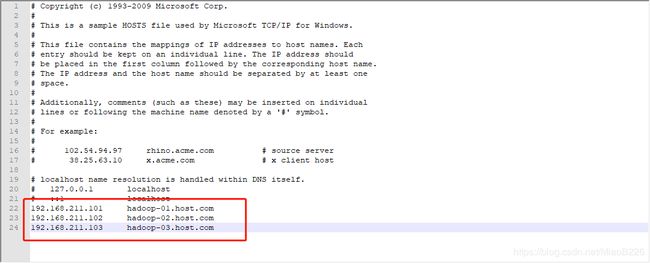 图58 添加虚拟机的ip地址与主机名
图58 添加虚拟机的ip地址与主机名
12、查看HDFS Web页面
网址:http://hadoop-01.host.com:50070/
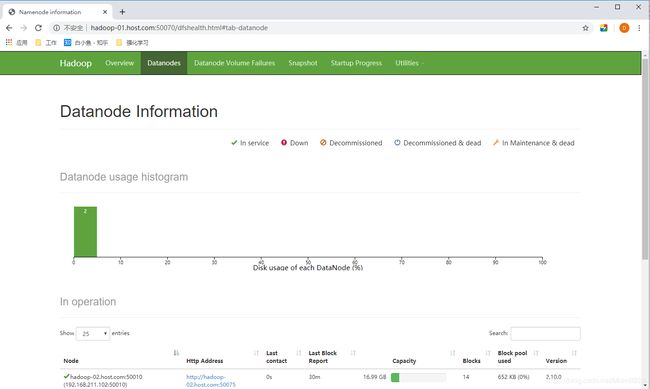 图59 HDFS Web界面
图59 HDFS Web界面
13、查看YARN Web 页面
网址:http://hadoop-02.host.com:8088/cluster
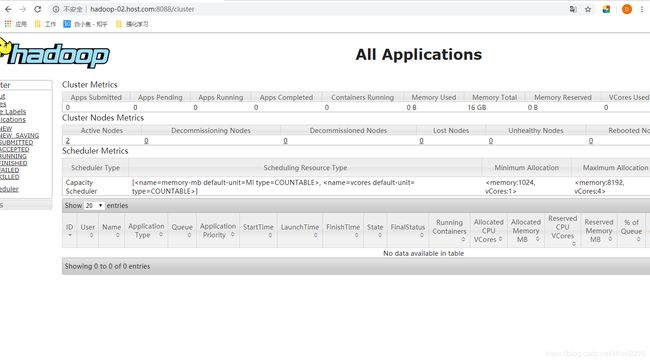 图60 YARN Web 页面
图60 YARN Web 页面
14、测试hadoop的demo
(1)首先创建 HDFS 上的用户目录:
hdfs dfs -mkdir -p /user/hadoop
(2) 将 /usr/local/Hadoop-2.10.0/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
hdfs dfs -mkdir input
hdfs dfs -put /usr/local/hadoop-2.10.0/etc/hadoop/*.xml input
会看到一大串报错信息,但是不要怕,这些报错信息可以忽略(这些报错信息在以前的版本中是warning,总之不要理他就好了)。
 图61 将文件传输到分布式系统
图61 将文件传输到分布式系统
(3) 通过查看 DataNode 的状态(占用大小有改变),确认输入文件确实复制到了 DataNode 中,如下图所示:
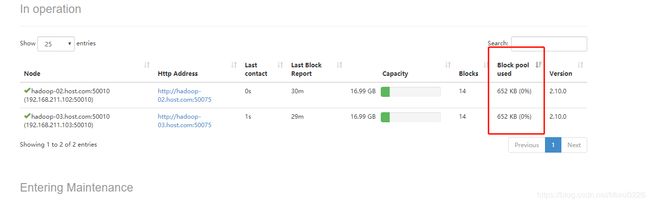 图62 查看DataNode占用情况
图62 查看DataNode占用情况
(4)运行 MapReduce 作业
hadoop jar /usr/local/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
成功输出如下所示
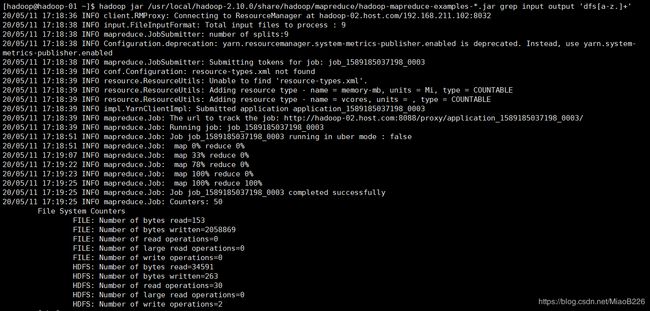
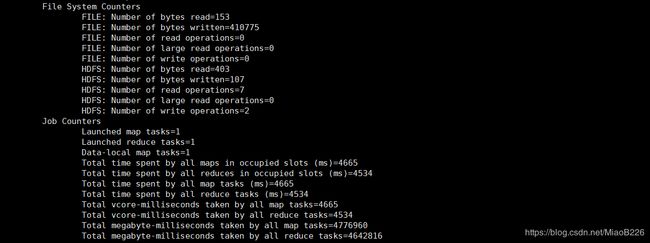
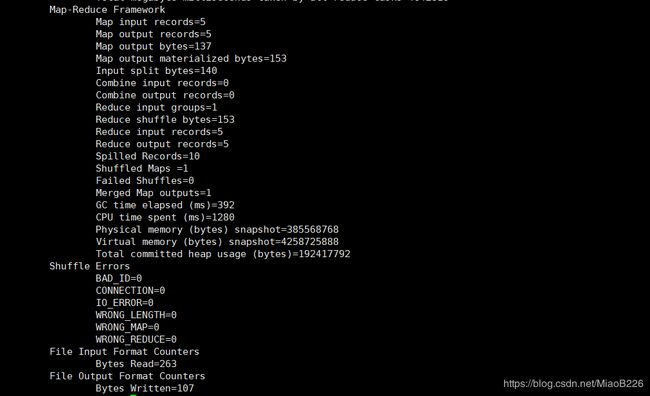
15、关闭Hadoop
1、在hadoop-02上关闭yarn
stop-yarn.sh
2、在hadoop-01上关闭dfs
stop-dfs.sh
3、在hadoop-03上关闭日志服务器
mr-jobhistory-daemon.sh stop historyserver