sklearn库
本文是视频学习笔记
监督学习(supervised learning):有数据和标签 如classification,regression
无/非监督学习(unspervised learning):只有数据没有标签clustering
半监督学习:结合了监督学习和无监督学习,如只有少部分有标签
强化学习(reinforcement learning):从经验中总结提升
遗传算法(genetic algorithm):与强化学习类似,适者生存不适者淘汰
(一) sklearn 简单介绍介绍

sklearn全程图

一个使用scikit learn的例子:以knn为例
import numpy as np
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier #导入k近邻分类器
iris = datasets.load_iris() #sklearn的数据集中有很多数据,这里导入iris这种花的数据
iris_X = iris.data #数据
iris_y = iris.target #标签
#print(iris_X[:2,:]) #输出前两行,即前两个数据,一行表示一个数据,一个数据可以有多个属性,即列
#print(iris_y)
#开始训练数据,使用train_test_split模块测试数据占30%
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3)
#print(y_train)
knn = KNeighborsClassifier()
knn.fit(X_train,y_train) #开始训练数据
#输出预测值和真实值
print(knn.predict(X_test)) #训练后的预测值
print(y_test) #真实值
另外,可以选择load_iris(return_X_y=True),表示返回data和target,默认是false,表示返回的是字典。比如
>>> iris
结果为:
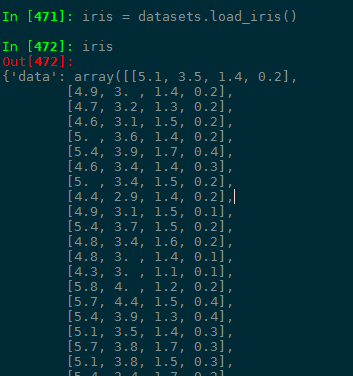
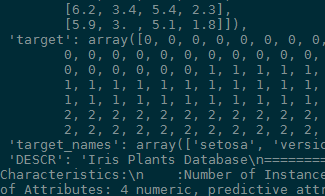
可以看到iris是一个包含两个数组的字典。而如果直接选择为True就可以直接得到这两个数组
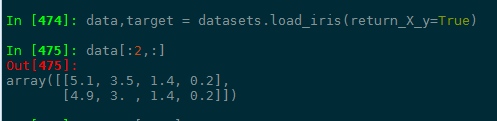
iris有三种类别,可以通过下面打印出来

最后,最上面的代码结果如下:第一批是预测值,第二批是真实值,可以看到很接近

(二)sklearn数据集
链接:sklearn-datasets
数据集中有已经存在的data,当要调用的时候直接datasets.load…即可,也可以datasets.make…自己生成数据。

1)从数据集导入数据
以Boston房价为例
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X,data_y)
print(model.predict(data_X[:4,:])) #测试值,只测试前四个数据
print(data_y[:4]) #真实值
上面的model = LinearRegression()括号里为空表示采用了默认值,当然也可以自己调,可以参考:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html

第一行表示测试数据,第二行表示真实值,看到有一定差别。想提高准确度有两个方法:
- 尝试不同model
- 尝试不同参数
- 尝试将data先normalise再使用
- …
**补充1:**除了上面的输出结果之外还可以输出系数,比如
y = a x 1 + b x 2 + c x 3 + . . . + c o n s t y=ax_1+bx_2+cx_3+...+const y=ax1+bx2+cx3+...+const
在上面例子中 x 1 , x 2 , x 3 . . . x1,x_2,x_3... x1,x2,x3...分别表示房子面积,采光,地段等等,const表示与y轴交点。现在要把前面的 a , b , c . . . . c o n s t a,b,c....const a,b,c....const输出,可以采用如下
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X,data_y)
#以y = 0.1x + 0.3为例
print(model.coef_) #coefficent,输出系数 0.1
print(model.intercept_) #跟y轴的交点坐标,即0.3

表示 a , b , . . . 分 别 等 于 − 1.0717 , 4.64... a,b,...分别等于-1.0717,4.64... a,b,...分别等于−1.0717,4.64...
**补充2:**查看都有哪些参数
查看LinearRegression()有哪些参数
print(model.get_params())
![]()
这些参数正是我们在上面图中看到的。n_jobs=1表示用一个核。
**补充3:**输出准确度
##data_X做预测,data_y作为真实值
print(model.score(data_X,data_y))
>>> 0.7406077428649428
准确度为74%
2)自己生成数据来练习
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
X,y = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1)
plt.scatter(X,y)
plt.show()
