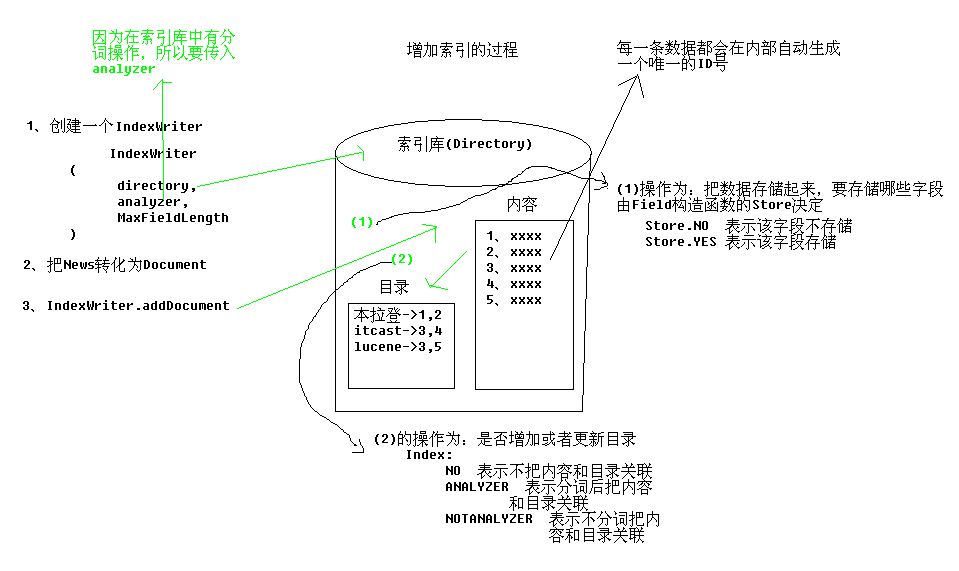
Lucene建立索引库
问题?Lucene如何建立索引库,lucene所需要的jar包是那些 , lucene如何使用索引库,lucene的核心原理
一、Lucene是什么?
全文检索只是一个概念,而具体实现有很多框架,lucene是其中的一种方式。本文将以lucene3.0进行开发
官兵与Luncne的jar包可以去官网下载:点击打开链接,不过好像Lucene已经更新到6.1了。
二、建立索引库
1.互联网搜索全文搜索引擎结构图:

2.Lucene的结构图:

说明
:
(1)在数据库中,数据库中的数据文件存储在磁盘上。索引库也是同样,索引库中的索引数据也在磁盘上存在,我们用 Directory
这个类来描述.
(2)我们可以通过API的
IndexWrite
来实现对索引库的增、删、改、查的操作.
(3)在数据库中,各种数据形式都可以概括为一种:表。在索引库中,各种数据形式也可以抽象出一种数据格式为
Document
.
(4)Document的结构为:Document(List).
(5)Field里存放一个键值对。键值对都为字符串的形式.
(6)对索引库中索引的操作实际上也就是对Document的操作.
3.准备lucene的开发环境
在挂窝囊下载好压缩包后,至少要准备四个包:
lucene-core-3.1.0.jar(
核心包
)、
lucene-analyzers-3.1.0.jar(
分词器
)、
lucene-highlighter-3.1.0.jar(
高亮器
)、
lucene-memory-3.1.0.jar(
内存器)
4.索引结构
5.第一个索引例子:
实体类:Article
package com.itcast.ldp.domain;
import java.io.Serializable;
public class Article implements Serializable{
private Long aid;
private String title;
private String content;
public Long getAid() {
return aid;
}
public void setAid(Long aid) {
this.aid = aid;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article [aid=" + aid + ", title=" + title + ", content="
+ content + "]";
}
}
(1)创建索引库
package com.itcast.ldp.lucene;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
/**
*
* 把Article对象放入到索引库中去
* 在索引库中把Article对象拿出来
* @author Administrator
*
*/
public class CreateLucene1 {
/**
*
* 创建索引
* @throws Exception
*/
@Test
public void createIndex() throws Exception{
/**
* 创建Article对象
*/
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎");
article.setContent("taobao");
/**
* //创建一个indexWriter对象 参数(1:索引库位置,2:分词器,3:代表文档中的属性最大长度)
*/
//1.索引库位置
Directory directory = FSDirectory.open(new File("./DirIndex"));
//2.分词器:讲一段内容分成关键词的作用
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
//3.表示文档属性的最大长度 MaxFieldLength.LIMITED限制索引库汇总字段的大小,必须限制.源码中只能放10K
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.LIMITED);
/**
* 把Article对象转化doucument对象
* Field.Index.*:详解如下
*Index.ANALYZED : 使用分析器将域值分解成独立的词汇单元流,并使用每个语汇单元能被搜索。该选项适用于普通文本域(正文、标题、摘要等);
*Index.NOT_ANALYZED : 对域进行索引,但不对String值进行分析。该操作实际上将域值作为单一语汇单元使之能够被搜索。该选项适用于索引那些不能被分解的域值(URL、文件路径、日期、人名、社保号码、手机号码等。)该选项尤其适用于"精确匹配"搜索;
*Index.ANALYZED_NO_NORMS : 这是Index.ANALYZED选项的一个变体,它不会在索引里面存储norms信息。norms记录了索引中的index-time boost信息,但是当你进行搜索时可能会比较耗费内存;
*Index.NOT_ANALYZED_NO_NORMS : 与Index.NOT_ANALYZED选项类似,但是也不存储norms。该选项用于搜索期间节省索引空间和减少内存消耗,因为single-token域并不需要norms信息,除非它们已被进行加权操作;
*Index.NO : 使对应的域值不被搜索;
*/
//创建文档
Document document = new Document();
//1.表示在索引库中的字段 2.存储在索引库中的值
Field idField = new Field("aid", article.getAid().toString(), Store.YES, Index.NOT_ANALYZED);
Field titleField = new Field("title", article.getTitle(), Store.YES, Index.ANALYZED);
Field contentField = new Field("content", article.getContent(), Store.YES, Index.ANALYZED);
//2.把field放入document中
document.add(idField);
document.add(titleField);
document.add(contentField);
/**
* 把document对象放入到索引库中
*/
indexWriter.addDocument(document);
/**
* 关闭资源(因为是存放磁盘上的,就有IO流,那就需要关闭)
*/
/*indexWriter.optimize();合并多个indexWriter对象产生的cfs文件合并,也可以不写,底层到达一定数量了,自动优化*/
indexWriter.close();
} }结果:
(2)查询索引库
package com.itcast.ldp.lucene;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
/**
*
* 把Article对象放入到索引库中去
* 在索引库中把Article对象拿出来
* @author Administrator
*
*/
public class CreateLucene1 {
/**
* 从索引库中根据关键词检索出来
* @throws Exception
*
*/
@Test
public void findIndex() throws Exception{
/**
* 1.创建insercher对象
*/
Directory directory = FSDirectory.open(new File("./DirIndex"));
IndexSearcher indexSearcher = new IndexSearcher(directory);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
//规定检索字段 1:版本号 2:字段 3:分词器
/*QueryParser queryParser = new QueryParser(Version.LUCENE_30, "title", analyzer);*/
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"}, analyzer);
//指定关键词
Query query = queryParser.parse("lucene");
//第二个参数:检索索引库中的前几个目录
TopDocs topDocs = indexSearcher.search(query, 20);
int count = topDocs.totalHits;//根据关键词得到目录中中总的条目数
System.out.println("共查询到条目数:"+count);
//ScoreDoc得到关键词所在的哪一行,得到总的索引号数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List articles = new ArrayList();
for(ScoreDoc scoreDoc:scoreDocs){
//关键词的索引号
int doc= scoreDoc.doc;
//根据索引号,得到文档,相当于得到书的页数
Document document = indexSearcher.doc(doc);
Article article = new Article();
article.setAid(Long.parseLong(document.get("aid")));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
articles.add(article);
}
for(Article article:articles){
System.out.println("索引库中得到:"+article.toString());
}
}
}
结果:

代码说明
步骤:
注意:因为分词器把输入的关键字都变成小写。
1) 创建IndexSearch
2) 创建Query对象
3) 进行搜索
4) 获得总结果数和前N行记录ID列表
5) 根据目录ID列表把Document转为为JavaBean并放入集合中。
6) 循环出要检索的内容
6.保持数据库与索引库的同步
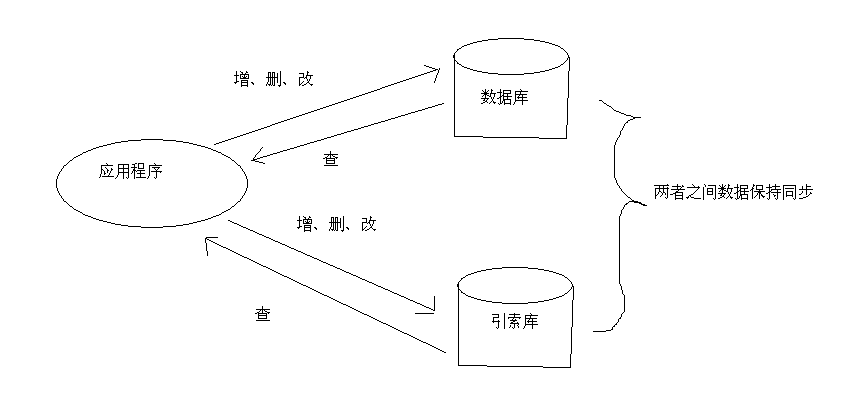
说明:
在一个系统中,如果索引功能存在,那么数据库和索引库应该是同时存在的。
这个时候需要保证索引库的数据和数据库中的数据保持一致性。可以在对数据库进行增、删、改操作的同时对索引库也进行相应的操作。
这样就可以保证数据库与索引库的一致性。
7.Document和实体相互转化工具类
说明:在对索引库进行操作时,增、删、改过程要把一个JavaBean(这里是指Article)封装成Document,而查询的过程是要把一个Document转化成JavaBean。在进行维护的工作中,要反复进行这样的操作,所以我们有必要建立一个工具类来重用代码。
package com.itcast.ldp.util;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import com.itcast.ldp.domain.Article;
public class DocumentArticleUtil {
public Document ArticleToDocument(Article article){
Document document = new Document();
//创建文档
//1.表示在索引库中的字段 2.存储在索引库中的值
/*NumericUtils.longToPrefixCoded(article.getAid());//要使用专业工具转化类型放入文档Long类型转化为String类型*/
Field idField = new Field("aid", article.getAid().toString(), Store.YES, Index.NOT_ANALYZED);
Field titleField = new Field("title", article.getTitle(), Store.YES, Index.ANALYZED);//Index.NO:
Field contentField = new Field("content", article.getContent(), Store.YES, Index.ANALYZED);
//2.把field放入document中
document.add(idField);
document.add(titleField);
document.add(contentField);
return document;
}
public Article DocumentToArticle(Document document){
Article article = new Article();
/*NumericUtils.prefixCodedToLong(document.get("aid"));//String类型转化为long类型*/
article.setAid(Long.parseLong(document.get("aid")));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
return article;
}
}
什么情况下使用Index.NOT_ANALYZED
当这个属性的值代表的是一个不可分割的整体,例如 ID
什么情况下使用Index.ANALYZED
当这个属性的值代表的是一个可分割的整体。
package com.itcast.ldp.util;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class DirectorAndAnalyzerUtile {
public static Directory directory;
public static Analyzer analyzer;
static{
try {
directory=FSDirectory.open(new File("./DirIndex"));
analyzer = new StandardAnalyzer(Version.LUCENE_30);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
8.索引库的增删改查(crud操作)
package com.itcast.ldp.lucene;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
import com.itcast.ldp.util.DirectorAndAnalyzerUtile;
import com.itcast.ldp.util.DocumentArticleUtil;
public class CrudLucene {
/**
* 创建索引
* @throws Exception
*/
@Test
public void createIndex() throws Exception{
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎");
article.setContent("Oracle,google,baidu,taobao");
IndexWriter indexWriter = new IndexWriter(DirectorAndAnalyzerUtile.directory, DirectorAndAnalyzerUtile.analyzer, MaxFieldLength.LIMITED);
DocumentArticleUtil util = new DocumentArticleUtil();
Document document = util.ArticleToDocument(article);
indexWriter.addDocument(document);
indexWriter.optimize();//优化,将多个indexWriter对象产生的cfs文件合并,也可以不写,底层到达一定数量了,自动优化
indexWriter.close();
}
/**
*
* 从索引库中得到索引
* @throws Exception
*/
@Test
public void findIndex() throws Exception{
IndexSearcher indexSearcher = new IndexSearcher(DirectorAndAnalyzerUtile.directory);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"}, DirectorAndAnalyzerUtile.analyzer);
//指定关键词
Query query = queryParser.parse("taobao11");
TopDocs topDocs = indexSearcher.search(query, 1);
int count = topDocs.totalHits;//得到含有lucene关键字的索引条目
System.out.println("总条数:"+count);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
DocumentArticleUtil documentArticleUtil = new DocumentArticleUtil();
List articles = new ArrayList();
for(ScoreDoc scoreDoc:scoreDocs){
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
Article article = documentArticleUtil.DocumentToArticle(document);
articles.add(article);
}
for(Article article:articles){
System.out.println("索引库索引得到:"+article.toString());
}
}
/**
*
* 删除关键词
* @throws Exception
*/
@Test
public void deleteIndex() throws Exception{
//创建关键词对象,字段名称为title,字段名称中含有lucene的关键字
Term term = new Term("title","lucene");
IndexWriter indexWriter = new IndexWriter(DirectorAndAnalyzerUtile.directory, DirectorAndAnalyzerUtile.analyzer, MaxFieldLength.LIMITED);
//删除关键词对象term是用来删除的
indexWriter.deleteDocuments(term);
indexWriter.close();
}
/**
*
* 更新关键字,先删除后更新
* @throws Exception
*/
@Test
public void updateIndex() throws Exception{
//创建关键词对象,字段名称为title,字段名称中含有lucene的关键字
Term term = new Term("title","lucene");
IndexWriter indexWriter = new IndexWriter(DirectorAndAnalyzerUtile.directory, DirectorAndAnalyzerUtile.analyzer, MaxFieldLength.LIMITED);
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎1");
article.setContent("Oracle,google,baidu,taobao11");
DocumentArticleUtil util = new DocumentArticleUtil();
Document doc = util.ArticleToDocument(article);
//更新关键词 term是用来删除的,doc是用来增加的
indexWriter.updateDocument(term, doc);
indexWriter.close();
}
}
9.IndexWrite详解
Hibernate中的SessionFactory 说明:在Hibernate中,一般保持一个数据库就只有一个SessionFactory。因为在SessionFactory中维护二级缓存,而SessionFactory又是线程安全的。所以SessionFactory是共享的。
同理:在索引库汇总如果同时有两个Indexwite去操作同一个索引库,就会造成错误。
如:

错误:

相应的在Luncen索引库中会出现write.lock这个文件。因为当一个IndexWriter在进行读索引库操作的时候,lucene会为索引库,以防止其他IndexWriter访问索引库而导致数据不一致,直到IndexWriter关闭为止。

注意:所以对IndexWrite的操作最好是单例模式,不然会抛出异常。
10.优化部分
当我们执行多次索引的时候,会出现索引库的文件如图所示:(索引里内容是一样的),会出现多个cfs文件,执行多少次,就会出现多少个cfs文件

当执行delete操作时,会生成如图所示的结构:也是一样的都会出现多个del文件

从图中可以看出来,lucene在执行删除的时候,是先把要删除的元素形成了一个文件del文件,然后再和cfs文件进行整合得出最后结果。
如果增加、删除反复操作很多次,就会造成文件大量增加,这样检索的速度也会下降,所以我们有必要去优化索引结构。Lucen有自动优化的功能,当文件数目到达一定量的时候,会自动合并cfs和del文件。但是我们可以手工去合并该文件。就一条语句:
indexWriter.optimize();//优化,将多个indexWriter对象产生的cfs文件合并,也可以不写,底层到达一定数量了,自动优化

注意使用内置工具类:LuceneUtils.getIndexWriter().setMergeFactor(3)意思为当文件的个数达到3的时候,合并成一个文件。如果没有设置这个值,则使用默认的情况:10个
11.内存索引库
前面介绍了索引库的特征及使用方法,这里我们提出一个问题,索引库是放在本地磁盘上的,如果我们将索引库放到内存当中,无疑速度将提升数倍。当然程序退出的时候,内存当中的索引自然也清除了,如果索引库很大,就得保证有足够的内存空间。
没有在磁盘上出现索引库。所以单独使用内存索引库没有任何意义。然后又要保证内存索引库中的内容和索引库中的内容保持一致,就得把内存索引库加入到本地索引库中。

实验代码:
package com.itcast.ldp.memory;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
import com.itcast.ldp.util.DirectorAndAnalyzerUtile;
import com.itcast.ldp.util.DocumentArticleUtil;
public class DirectoryMemoryTest {
/**
*
* 内存索引库的建立RAMDirectory()
* @throws Exception
*/
@Test
public void testMemory() throws Exception{
/*Directory directory = FSDirectory.open(new File("./MemoryTest"));这是创建池畔索引库*/
Directory directory = new RAMDirectory();//这是创建内存索引库
IndexWriter indexWriter = new IndexWriter(directory, DirectorAndAnalyzerUtile.analyzer,MaxFieldLength.LIMITED);
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎");
article.setContent("Oracle,google,baidu,taobao");
DocumentArticleUtil util = new DocumentArticleUtil();
Document document = util.ArticleToDocument(article);
indexWriter.addDocument(document);
indexWriter.close();
this.inserchDirectory(directory);
}
public void inserchDirectory(Directory directory) throws Exception{
IndexSearcher indexSearcher = new IndexSearcher(directory);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"}, DirectorAndAnalyzerUtile.analyzer);
Query query = queryParser.parse("lucene");
TopDocs docs = indexSearcher.search(query, 1);
ScoreDoc[] scoreDocs = docs.scoreDocs;
List articles = new ArrayList();
DocumentArticleUtil articleUtil = new DocumentArticleUtil();
for(ScoreDoc scoreDoc:scoreDocs){
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
Article article = articleUtil.DocumentToArticle(document);
articles.add(article);
}
for(Article article:articles){
System.out.println(article.toString());
}
}
/**
*
* 内存索引库与文件索引库的建立
* 保证文件索引库的持久性
* 保证内存索引库的性能
* @throws Exception
*/
@Test
public void testMemoryDirectoryAndFileDirectory() throws Exception{
//1.建立两个索引库
//2.把文件索引库放入到内存索引库当中
Directory fileDirectory = FSDirectory.open(new File("./DirCrud"));
Directory memoryDirectory = new RAMDirectory(fileDirectory);
//3.建立两个indexWritter,这里的true代表内存索引库的内容到文件索引库中覆盖,默认false表示追加
IndexWriter fileWriter = new IndexWriter(fileDirectory, DirectorAndAnalyzerUtile.analyzer, true,MaxFieldLength.LIMITED);
IndexWriter memoryWriter = new IndexWriter(memoryDirectory, DirectorAndAnalyzerUtile.analyzer, MaxFieldLength.LIMITED);
//4.让内存索引库和客户端交互
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎");
article.setContent("Oracle,google,baidu,taobao");
DocumentArticleUtil util = new DocumentArticleUtil();
Document document = util.ArticleToDocument(article);
memoryWriter.addDocument(document);
//5.把内存索引库内容放入到文件索引库当中
fileWriter.addIndexesNoOptimize(memoryDirectory);
memoryWriter.close();
fileWriter.close();
this.inserchDirectory(fileDirectory);
}
}
12.分词器
(1).分词器的作用
在前面创建是索引库的时候,就已经用到分词器了,它的作用主要是将数据进行分词(英文内置,中文自定义),然后在放到索引库中,方便进行索引。这就是它的作用
(2).英文分词器的步骤
切分关键词——>去除停用词——>转化为小写
Eg1:
I am a Person of China
切分:I、am、a、Person、of、China 去除停用词:Person、China 转化小写:person、china
这就是因为分词器的全过程。
(3).中文分词器
但是英文分词器对中文分割就不行,若强制使用该方式,最后将分割成一个一个字符,那很明显不是我们中国人要的关键字啊,中文中有词语,四字词语,古汉语等,所以又中国人开发了一款分词器IKAnalyzer(开源的,可以在网上下载,这个包需要导入的),在里面可自定义一些需要分割的汉字和需要停用的用词。
导入包后:
包要导入,然后有一个xml配置文件要导入,在这个jar包中本身已经写好了许多的词语,就可以分割了,但是有一些词语需要自己自定义进行分割才行,所以就需要在配置文件中进行配置:
IK Analyzer 扩展配置
/mydict.dic;
ext_stopword.dic:这个是停用词的文件,需要停用的都可以写在当中,这个工具会自动停用该文件出现的词语
mydict.dic:这个是用户自定义需要分割的词语。
(4).代码
package com.itcast.ldp.Analyzed;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.TermAttribute;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class AnalyzedTest {
/**
* 英文分词器三个步骤
* @throws Exception
*/
@Test
public void englishDirectoryTest() throws Exception{
//1.拆分
//2.停用词
//3.大写转化为小写
String text = "I'm a the customer among all customers!";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
this.coverContent(analyzer, text);
}
//英文分词
private void coverContent(Analyzer analyzer,String text) throws Exception{
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
tokenStream.addAttribute(TermAttribute.class);
while(tokenStream.incrementToken()){
TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class);
System.out.println(termAttribute.term());
}
}
//中文分词器最麻烦,外国人提供的那套就不适用了
@Test
public void ChineseDirectoryTest_1() throws Exception{
String text = "我是一名中国人!";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
this.coverContent(analyzer, text);
}
//二分法分词器
@Test
public void ChineseDirectoryTest_2() throws Exception{
String text = "我是一名中国人!";
Analyzer analyzer = new CJKAnalyzer(Version.LUCENE_30);
this.coverContent(analyzer, text);
}
//使用中国人开发的一套分词器 IKAnalyzer3.2.0Stable.jar该词库不就支持中文分词同时支持英文分词
//使用扩展词典的时候,必须保证编码格式相同
@Test
public void ChineseDirectoryTest_3() throws Exception{
String text = "am the english 赵东 我是一名中国人!";
Analyzer analyzer = new IKAnalyzer();
this.coverContent(analyzer, text);
}
}
13.相关度排名,及高亮
这个的定义看表面意思都可理解,百度是全文检索,它检索到的内容会根据在这个内容中关键字出现的次数进行排名然后将数据显示给用户看,而高亮则是管家会加红,会把主要的关键字区分出来。
package com.itcast.ldp.highlight;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
import com.itcast.ldp.util.DirectorAndAnalyzerUtile;
import com.itcast.ldp.util.DocumentArticleUtil;
public class HighLightTest {
public void inserchTest(int min,int max) throws Exception{
IndexSearcher indexSearcher = new IndexSearcher(DirectorAndAnalyzerUtile.directory);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30,new String[]{"title","content"},DirectorAndAnalyzerUtile.analyzer);
Query query = queryParser.parse("lucene");
TopDocs topDocs = indexSearcher.search(query, 30);
//创建和配置高亮器
Formatter formatter = new SimpleHTMLFormatter("", "");
Scorer scorer =new QueryScorer(query);//得到高亮的关键词
Highlighter highlighter = new Highlighter(formatter, scorer);//给指定的关键词加前缀和后缀
//创建摘要器
Fragmenter fragmenter = new SimpleFragmenter(10);//指定索引库中的字段摘要大小,如果是无参构造器,则默认大小为150
highlighter.setTextFragmenter(fragmenter);//设置摘要
int count = topDocs.totalHits;
System.out.println("查询总的记录条目数:"+count);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
int pageSize = Math.min(count, min+max);
List articles = new ArrayList();
DocumentArticleUtil util = new DocumentArticleUtil();
for(int i=min;i luence
* 2.分词器的作用就是提取高亮器高亮的关键字
*/
String text = highlighter.getBestFragment(DirectorAndAnalyzerUtile.analyzer, "title", document.get("title"));
article.setTitle(text);
articles.add(article);
}
indexSearcher.close();
for(Article article:articles){
System.out.println(article.toString());
}
}
@Test
public void highLightTest()throws Exception{
inserchTest(0, 40);
}
}
13.Lucene的核心API介绍
IndexWriter
1) 利用这个类可以对索引库进行增、删、改操作。
2) 利用构造方法IndexWriter indexWriter = new IndexWriter(directory,LuceneConfig.analyzer,MaxFieldLength.LIMITED)可以构造一个IndexWriter的对象。
3) addDocument向索引库中添加一个Document
4) updateDocument更新一个Document
5) deleteDocuments删除一个Document
Directory指向索引库的位置,有两种Directory
1) 利用这个类可以对索引库进行增、删、改操作。
2) 利用构造方法IndexWriter indexWriter = new IndexWriter(directory,LuceneConfig.analyzer,MaxFieldLength.LIMITED)可以构造一个IndexWriter的对象。
3) addDocument向索引库中添加一个Document
4) updateDocument更新一个Document
5) deleteDocuments删除一个Document
Directory指向索引库的位置,有两种Directory
FSDirectory
1) 通过FSDirectory.open(new File("./indexDir"))建立一个indexDir的文件夹,而这个文件夹就是索引库存放的位置。
2) 通过这种方法建立索引库时如果indexDire文件夹不存在,程序将自动创建一个,如果存在就用原来的这个。
3) 通过这个类可以知道所建立的索引库在磁盘上,能永久性的保存数据。这是优点
4) 缺点为因为程序要访问磁盘上的数据,这个操作可能引发大量的IO操作,会降低性能。
RAMDirectory
1) 通过构造函数的形式Directory ramdirectory = new RAMDirectory(fsdirectory)可以建立RAMDirectory。
2) 这种方法建立的索引库会在内存中开辟一定的空间,通过构造函数的形式把fsdirectory移动到内存中。
3) 这种方法索引库中的数据是暂时的,只要内存的数据消失,这个索引库就跟着消失了。
4) 因为程序是在内存中跟索引库交互,所以利用这种方法创建的索引的好处就在效率比较高,访问速度比较快。
Document
1) 通过无参的构造函数可以创建一个Document对象。Document doc = new Document();
2) 一个Directory是由很多Document组成的。用户从客户端输入的要搜索的关键内容被服务器端包装成JavaBean,然后再转化为Document。这个转化过程的代码如下:
Field
1) Field相当于JavaBean的属性。
2) Field的用法为:
new Field("title",article.getTitle(),Store.YES,Index.ANALYZED)
a) 第一个参数为属性
b) 第二个参数为属性值
c) 第三个参数为是否往索引库里存储
d) 第四个参数为是否更新引索
1) NO 不进行引索
2) ANALYZED 进行分词引索
3) NOT_ANALYZED 进行引索,把整个输入作为一个词对待。
MaxFieldLength
a) 能存储的最大长度
b) 在IndexWriter的构造方法里使用
c) 值为:
1) LIMITED 限制的最大长度 值为10000
2) UNLIMITED 没有限制的最大长度(一般不使用)